
13. YOLOv10¶
YOLOv10 是清华大学研究人员近期提出的一种实时目标检测方法,通过消除NMS、优化模型架构和引入创新模块等策略, 在保持高精度的同时显著降低了计算开销,为实时目标检测领域带来了新的突破。
YOLOv10 的主要特征包括其整体效率精度驱动的模型设计, 该设计全面优化了模型的各个组件,还使用轻量级的分类头和空间信道解耦下采样来减少计算开销。 此外,YOLOv10采用了大型内核卷积和部分自关注模块来增强全局表示学习,从而实现了最先进的性能和效率。
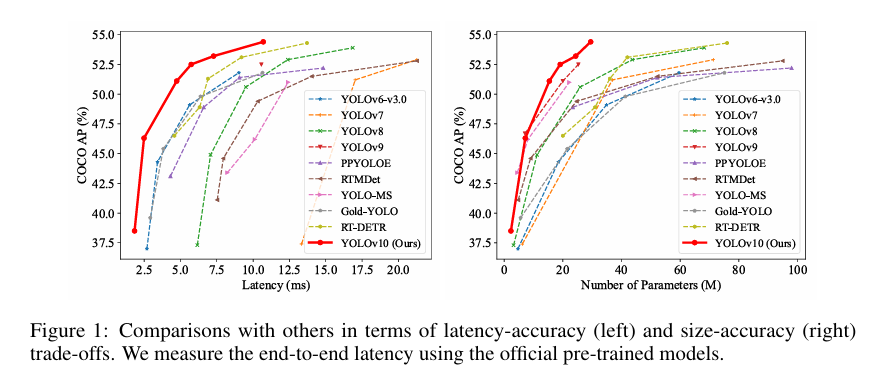
YOLOv10在各种模型规模上都达到了最先进的性能和效率。例如,在COCO上类似的AP下, YOLOv10-S比RT-DETR-R18快1.8倍,同时参数和FLOP数量减少2.8倍。 与YOLOv9-C相比,在相同的性能下,YOLOv10-B的延迟减少了46%,参数减少了25%。
YOLOv10论文地址:https://arxiv.org/pdf/2405.14458
YOLOv10项目地址:https://github.com/THU-MIG/yolov10
本章将简单测试YOLOv10,并导出rknn模型,在鲁班猫板卡上部署测试。
13.1. YOLOv10简单测试¶
在个人PC上使用Anaconda创建一个yolov10环境,然后简单使用yolov10。
13.1.1. 环境配置¶
获取工程源码:
git clone https://github.com/THU-MIG/yolov10.git
使用Anaconda进行环境管理,创建一个yolov10环境:
conda create -n yolov10 python=3.9
conda activate yolov10
# 切换到yolov10工程目录,然后安装依赖
cd yolov10
pip install -r requirements.txt
pip install -e .
# 安装完成后简单测试yolo命令
(yolov10) xxx@anhao:~$ yolo -V
8.1.34
13.1.2. 模型推理测试¶
获取模型(这里获取s尺寸yolov10模型):
wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
然后使用命令测试:
(yolov10) xxx@anhao:~$ yolo predict model=./yolov10s.pt
WARNING ⚠️ 'source' argument is missing. Using default 'source=xxx'.
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 3060 Laptop GPU, 6144MiB)
YOLOv10n summary (fused): 285 layers, 2762608 parameters, 63840 gradients, 8.6 GFLOPs
image 1/2 xxx/bus.jpg: 640x480 4 persons, 1 bus, 55.5ms
image 2/2 xxx/zidane.jpg: 384x640 2 persons, 60.5ms
Speed: 2.9ms preprocess, 58.0ms inference, 5.4ms postprocess per image at shape (1, 3, 384, 640)
Results saved to /xxx/yolov10/runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
结果保存在yolov10工程文件runs/detect/predict目录下。
也可以测试yolov10工程文件中的app.py程序,一个网页显示,直接拖拽图像,然后推理显示结果。
13.2. 板卡上部署测试¶
参考 YOLOv8模型 的适配,修改下yolov10模型输出,然后使用toolkit2工具转换成rknn模型, 最后调用librknnrt库,部署yolov10目标检测模型。
教程测试例程参考下 这里 。
13.2.1. 导出适配的onnx模型¶
拉取已修改的yolov10工程文件:
git clone https://github.com/mmontol/yolov10.git
查看下yolov10模型导出的修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # 省略................
class v10Detect(Detect):
max_det = 300
def __init__(self, nc=80, ch=()):
super().__init__(nc, ch)
c3 = max(ch[0], min(self.nc, 100)) # channels
self.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \
nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \
nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))
self.one2one_cv2 = copy.deepcopy(self.cv2)
self.one2one_cv3 = copy.deepcopy(self.cv3)
def forward(self, x):
if self.export and self.format == 'rknn':
y = []
for i in range(self.nl):
y.append(self.one2one_cv2[i](x[i]))
cls = torch.sigmoid(self.one2one_cv3[i](x[i]))
cls_sum = torch.clamp(cls.sum(1, keepdim=True), 0, 1)
y.append(cls)
y.append(cls_sum)
return y
one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)
if not self.export:
one2many = super().forward(x)
|
上面修改模型将会有9个输出,也可以删除其中的y.append(cls_sum),将会有6个输出,后面部署例程中后处理兼容这两种输出。
接着修改ultralytics/cfg/default.yaml文件,设置模型路径为前面拉取的官方yolov10模型路径:
1 2 3 4 5 6 7 | task: detect # (str) YOLO task, i.e. detect, segment, classify, pose
mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
# Train settings -------------------------------------------------------------------------------------------------------
model: ../yolov10s.pt # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # (str, optional) path to data file, i.e. coco128.yaml
epochs: 100 # (int) number of epochs to train for
|
然后使用命令导出onnx模型:
# 切换到yolov10工程目录
export PYTHONPATH=./
python ./ultralytics/engine/exporter.py
可以使用 Netron 查看下导出的模型。
13.2.2. 导出rknn模型¶
使用toolkit2工具,将前面的onnx模型转换成rknn模型, toolkit2的安装可以参考下 这里 。
一个简单的模型转换程序例程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | # 省略.....
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
#ret = rknn.load_pytorch(model=model_path, input_size_list=[[1, 3, 640, 640]])
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(output_path)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Release
rknn.release()
|
(toolkit2_2.1.0) xxx@anhao:/xxx/yolov10$ python onnx2rknn.py ./yolov10s.onnx rk3588 i8
I rknn-toolkit2 version: 2.1.0+708089d1
--> Config model
done
--> Loading model
I Loading : 100%|██████████████████████████████████████████████| 164/164 [00:00<00:00, 75151.96it/s]
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 606.32it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 291.12it/s]
# 省略........
I rknn building ...
I rknn buiding done.
done
--> Export rknn model
done
13.2.3. RKNPU2部署推理¶
部署测试使用runtime提供的c/c++接口, 如果使用RKNN Toolkit Lite2(python接口)部署测试请参考下 这里 。
# 安装opencv等等
sudo apt update
sudo apt install libopencv-dev git make gcc g++ libsndfile1-dev
# 拉取配套例程,鲁班猫板卡上直接编译
cat@lubancat:~/xxx$ git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
cat@lubancat:~/xxx$ cd lubancat_ai_manual_code/example/yolov10/cpp
# 编译yolov10例程,其中-t指定目标设备,这里测试使用lubancat-4,设置rk3588,如果是lubancat-0/1/2就设置rk356x
# 如果系统内存大于4G的,设置参数-d
cat@lubancat:~/xxx/lubancat_ai_manual_code/example/yolov10/cpp$ ./build-linux.sh -t rk3588 -d
./build-linux.sh -t rk3588 -d
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/xxx/yolov10/cpp/install/rk3588_linux
BUILD_DIR=/xxx/yolov10/cpp/build/build_rk3588_linux
ENABLE_DMA32=TRUE
ENABLE_ZERO_COPY=OFF
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
-- The C compiler identification is GNU 10.2.1
-- The CXX compiler identification is GNU 10.2.1
# 省略.................
[ 93%] Built target yolov10_image_demo
[100%] Linking CXX executable yolov10_videocapture_demo
[100%] Built target yolov10_videocapture_demo
# 省略..........
编译生成yolov10_image_demo和yolov10_videocapture_demo两个例程,一个用于对图像的检测识别, 另外一个可以通过opencv打开摄像头或者视频进行目标检测。
重要
部署使用的librknnrt库的版本需要与模型转换的rknn-Toolkit2版本一致。
编译输出程序在当前目录的build/build_rk3588_linux中,测试yolov10_image_demo例程:
# yolov10_image_demo <model_path> <image_path>
cat@lubancat:~/xxx/install/rk3588_linux$ ./yolov10_image_demo ./model/yolov10s_rk3588_i8.rknn ./model/bus.jpg
load lable ./model/coco_80_labels_list.txt
rknn_api/rknnrt version: 2.1.0 (967d001cc8@2024-08-07T19:28:19), driver version: 0.9.2
model input num: 1, output num: 6
input tensors:
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8,
qnt_type=AFFINE, zp=-128, scale=0.003922, ,size_with_stride=1228800, w_stride=640
output tensors:
index=0, name=502, n_dims=4, dims=[1, 64, 80, 80], n_elems=409600, size=409600, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-56, scale=0.086829, ,size_with_stride=409600, w_stride=0
index=1, name=516, n_dims=4, dims=[1, 80, 80, 80], n_elems=512000, size=512000, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-128, scale=0.003514, ,size_with_stride=512000, w_stride=0
index=2, name=523, n_dims=4, dims=[1, 64, 40, 40], n_elems=102400, size=102400, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-63, scale=0.092087, ,size_with_stride=122880, w_stride=0
index=3, name=537, n_dims=4, dims=[1, 80, 40, 40], n_elems=128000, size=128000, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-128, scale=0.003639, ,size_with_stride=153600, w_stride=0
index=4, name=544, n_dims=4, dims=[1, 64, 20, 20], n_elems=25600, size=25600, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-45, scale=0.068037, ,size_with_stride=40960, w_stride=0
index=5, name=558, n_dims=4, dims=[1, 80, 20, 20], n_elems=32000, size=32000, fmt=NCHW, type=INT8,
qnt_type=AFFINE, zp=-128, scale=0.003850, ,size_with_stride=51200, w_stride=0
model is NHWC input fmt
model input height=640, width=640, channel=3
origin size=640x640 crop size=640x640
input image: 640 x 640, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
scale=1.000000 dst_box=(0 0 639 639) allow_slight_change=1 _left_offset=0 _top_offset=0 padding_w=0 padding_h=0
src width=640 height=640 fmt=0x1 virAddr=0x0x7fa1aa3010 fd=0
dst width=640 height=640 fmt=0x1 virAddr=0x0x7fa1977000 fd=8
src_box=(0 0 639 639)
dst_box=(0 0 639 639)
color=0x72
rga_api version 1.10.1_[0]
bus @ (91 136 555 435) 0.959
person @ (110 235 226 536) 0.909
person @ (212 240 285 509) 0.855
person @ (476 233 559 521) 0.832
write_image path: out.png width=640 height=640 channel=3 data=0x7fa1aa3010
推理结果如上,检测结果图片保存为out.png。
测试yolov10_videocapture_demo例程,该例程使用opencv(opencv4)打开摄像头(教程是测试usb摄像头)或者视频文件, 图像经过RGA处理,送到NPU推理,经过后处理等操作,最终调用Opencv在显示器界面显示结果:
# 确认板卡烧录有带桌面的镜像系统,然后打开桌面终端,执行命令
# ./yolov10_videocapture_demo <model path> <camera device id/video path>
cat@lubancat:~/xxx/install/rk3588_linux$ ./yolov10_videocapture_demo ./model/yolov10s_rk3588_i8.rknn ~/test.mp4
教程测试一个1080p视频,显示结果如下:

需要注意:测试usb摄像头,请确认摄像头的设备号,修改例程中摄像头支持的分辨率和MJPG格式等, 如果是mipi摄像头,需要opencv设置转换成rgb格式以及设置分辨率大小等等。