
8. YOLOv3¶
目标检测是计算机视觉中的一项基本任务,它的目标是在图像或视频中找出所有感兴趣的目标(物体),并确定这些物体的类别和位置。 在实际应用中,目标检测有着广泛的应用,例如安全监控、智能驾驶、电子商务等等。
基于深度神经网络的目标检测,主要分为Anchor-Based和Anchor-Free,其中Anchor-Based方法又可以分为两阶段检测算法和单阶段检测算法。
两阶段目标检测,第一个阶段是使用Anchor(锚框)提取候选目标,然后用分类器对候选目标进行分类,将它们分为不同的类别, 然后第二个阶段使用回归器对每个类别中的物体进行位置回归,以确定它们的位置,代表的算法有R-CNN、Fast R-CNN等。
单阶段目标检测,同时产生候选区域的同时预测出物体的类别和位置,常见的算法有YOLO、SSD等。
Anchor-Free的方法,是不使用预先设定Anchor(锚框),通过预测目标的中心或角点,对目标进行检测。
YOLOv3(You Only Look Once version 3)是一种Anchor-Based的单阶段目标检测模型,是YOLO目标检测算法的一个重要版本。 YOLOv3在YOLOv2的基础上,对网络的主干进行了改良, 利用多尺度特征图进行检测,并改进了多个独立的Logistic回归分类器来取代softmax来预测类别分类。
本章使用Pytorch深度学习框架,简单介绍下yolov3的模型结构、推理测试、训练模型以及在rk356x/rk3588上部署yolov3模型等等。
提示
测试环境:鲁班猫板卡使用Debian或者ubuntu系统,PC系统是ubuntu20.04,rknn-Toolkit2版本1.5.0。
8.1. YOLOv3简单分析¶
Joseph Redmon等人在2015年提出YOLO算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。 YOLOv3原理详细请查看 论文 。
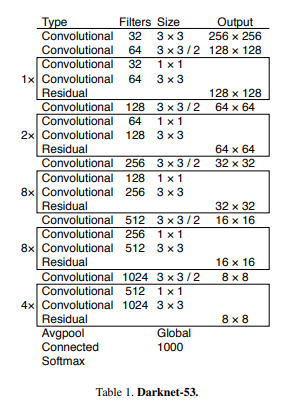
YOLOv3采用Darknet-53作为深度神经网络的主干特征提取网络(来自 论文):
整体网络结构可以简单参考下:
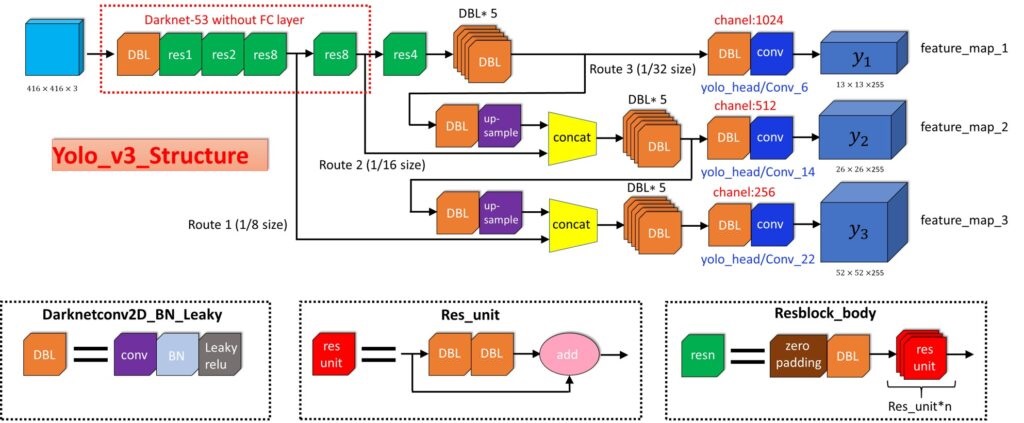
网络结构整体分为三个部分:
Backbone:骨干网络,主要用于特征提取
Neck:在Backbone和Head之间提取不同特征图,用于多尺度检测
Head:检测头,用于预测目标的类别和位置
YOLOv3有三个输出特征层(13x13x255,26x26x255,52x52x255),分别负责检测大中小三个尺度的目标,提升了对小目标的检测能力。
以13x13x255层输出为例,表示网络最后输出13X13个格子,每个格子有三个anchor,每个anchor对应一个预测框框, 每个预测框又有4个位置坐标加上一个置信度参数,再加上coco数据集80个类别,3个anchor总共255个参数,就是13x13x3x(80+5),这层 特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。
8.1.1. yolov3的实现¶
yolov3论文实现使用 Darknet ,Darknet是一个基于C和CUDA的开源深度学习框架。 使用Darknet实现的yolov3代码仓库在 https://github.com/pjreddie/darknet/tree/master 。
YOLOv3的Pytoch实现,其中github收藏较多的有 https://github.com/ultralytics/yolov3 、 https://github.com/eriklindernoren/PyTorch-YOLOv3 等等。
YOLOv3的TensorFlow实现,可以参考下 https://github.com/zzh8829/yolov3-tf2 , PaddlePaddle实现可以直接参考官方的 PaddleDetection 。
本教程测试将基于PyTorch实现的 ultralytics yolov3 仓库,并且使用以前版本(archive分支):
git clone https://github.com/ultralytics/yolov3 -b archive
8.2. ultralytics yolov3测试¶
8.2.1. 环境安装¶
安装相关环境,使用conda创建虚拟环境,可以参考下前面环境搭建章节:
# 使用conda创建一个名为yolov3的环境,并指定python版本
conda create -n yolov3 python=3.8
# 进入环境
conda activate yolov3
获取ultralytics yolov3源码,安装相关环境:
# 获取程序
git clone https://github.com/ultralytics/yolov3 -b archive
# 切换到yolov3目录
cd yolov3
# 安装相关软件库,
pip install -r requirements.txt
# 默认会安装pytorch,支持gpu等,可以自行到Pytorch官网https://pytorch.org/get-started/previous-versions/查看命令安装,下面命令示例是安装cuda11.6的版本:
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116
pytorch和nmupy建议按requirements.txt中的要求安装,如果安装高版本可能有很多小问题(可以从网上搜索到答案)。
8.2.2. 目标检测¶
使用预先训练好的模型进行目标检测,先获取darknet权重:
# 获取darknet权重文件,yolov3-tiny是轻量级的yolov3,,yolov3-spp是添加了spp网络的权重文件
wget -c https://pjreddie.com/media/files/yolov3.weights
wget -c https://pjreddie.com/media/files/yolov3-tiny.weights
wget -c https://pjreddie.com/media/files/yolov3-spp.weights
# 或者获取pytorch 权重文件
# darknet53 weights (first 75 layers only)
# wget -c https://pjreddie.com/media/files/darknet53.conv.74
# 或者通过工程的download_yolov3_weights.sh获取权重
执行目标检测程序,–weights指定权重文件,这里测试yolov3.weights;–cfg指定配置文件,不指定时默认是cfg/yolov3-spp.cfg, 这里测试是cfg/yolov3.cfg;–source指定需要检测的图片路径,或者指定图片文件夹路径。
# 测试单张图片推理
python3 detect.py --source data/samples/bus.jpg --weights weights/yolov3.weights --cfg cfg/yolov3.cfg
# 多张图片推理,推理工程目录data/samples下的所有图片
python3 detect.py --source data/samples --weights weights/yolov3.weights --cfg cfg/yolov3.cfg
单张图片推理输出:
Namespace(agnostic_nms=False, augment=False, cfg='cfg/yolov3.cfg', classes=None, conf_thres=0.3, device='', fourcc='mp4v', half=False, img_size=512,
iou_thres=0.6, names='data/coco.names', output='output', save_txt=False, source='data/samples/bus.jpg', view_img=False, weights='weights/yolov3.weights')
Using CUDA device0 _CudaDeviceProperties(name='NVIDIA GeForce RTX 3060 Laptop GPU', total_memory=6143MB)
~/miniconda3/envs/pytorch-yolov3/lib/python3.8/site-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release,
it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3190.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Model Summary: 222 layers, 6.19491e+07 parameters, 6.19491e+07 gradients, 117.5 GFLOPS
image 1/1 data/samples/bus.jpg: 512x384 4 persons, 1 buss, Done. (0.019s)
Results saved to /mnt/e/wsl_file/wsl_ai/yolov3_ultralytics/archive/yolov3/output
Done. (2.895s)
检查打印出检测到的物体、以及置信度等,预测的输出图像保存在当前目录下的predictions.jpg:

8.2.3. 训练模型¶
可以重新训练自己的yolov3模型,基于自己的数据集,超参数,系列策略等等。 下面我们将基于coco数据集,重新训练yolo模型,你也可以做自己的数据集,然后训练。
工程中提供了一个脚本(get_coco2017.sh)获取coco2017数据集,执行命令获取数据集:
cd data
./get_coco2017.sh
脚本可能由于很多原因会获取不到,可以从配套资料网盘获取数据集,或者从https://cocodataset.org/#download下载,将获取的coco数据集目录放到工程根目录下, 获取的数据集coco目录结构:
.
├── LICENSE
├── README.txt
├── annotations
│ └── instances_val2017.json
├── images
│ ├── train2017 # 训练集图像(118k images,19G)
│ └── val2017 # 验证集图像(5k images,1G)
├── labels
│ ├── train2017
│ └── val2017
├── test-dev2017.txt
├── train2017.txt
└── val2017.txt
7 directories, 6 files
实际测试使用准备的coco64,就是前面coco2017数据集中抽出64张用了训练,仅仅是测试使用。
使用准备的coco64数据集,设置data/coco64.data文件:
classes=80
train=coco64/coco64.txt
valid=coco64/coco64.txt
names=data/coco.names
其中,classes是类别,coco2017数据集有80类别,train是训练用到的图像清单,valid是验证用到的图像清单, 上面train和valid设置相同,仅仅是示例测试。最后的name是类别名称,为了对应的实际类别id。如果是自己的数据集,除了需要生成清单文件和修改classes,还需要修改网络配置文件。
训练执行train.py,执行命令中–data是指定数据配置文件,–weights指定权重文件,–cfg是指定模型网络配置文件, –epochs指定训练循环epoch数,–batch-size设置一次训练的图像分组:
# 这里仅仅训练30 epoch,简单训练
python train.py --data data/coco64.data --weights weights/yolov3.weights --batch-size 16 --cfg cfg/yolov3.cfg --epochs 30 --img-size 416
# 输出
Namespace(adam=False, batch_size=16, bucket='', cache_images=False, cfg='cfg/yolov3.cfg', data='data/coco64.data', device='', epochs=30, evolve=False, freeze_layers=False, img_size=[320, 640], multi_scale=False, name='', nosave=False, notest=False, rect=False, resume=False, single_cls=False, weights='weights/yolov3.weights')
Using CUDA Apex device0 _CudaDeviceProperties(name='NVIDIA GeForce RTX 3060 Laptop GPU', total_memory=6143MB)
Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/
/home/llh/miniconda3/envs/pytorch-yolov3/lib/python3.8/site-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3190.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Model Summary: 222 layers, 6.19491e+07 parameters, 6.19491e+07 gradients, 117.5 GFLOPS
Optimizer groups: 75 .bias, 75 Conv2d.weight, 72 other
/home/llh/miniconda3/envs/pytorch-yolov3/lib/python3.8/site-packages/apex/__init__.py:68: DeprecatedFeatureWarning: apex.amp is deprecated and will be removed by the end of February 2023. Use [PyTorch AMP](https://pytorch.org/docs/stable/amp.html)
warnings.warn(msg, DeprecatedFeatureWarning)
Caching labels coco64/coco64.txt (64 found, 0 missing, 0 empty, 0 duplicate, for
Caching labels coco64/coco64.txt (64 found, 0 missing, 0 empty, 0 duplicate, for
Image sizes 416 - 416 train, 416 test
Using 8 dataloader workers
Starting training for 30 epochs...
Epoch gpu_mem GIoU obj cls total targets img_size
0/29 4.48G 5.1 11.7 1.72 18.5 192 416
Class Images Targets P R mAP@0.5 F1
all 64 544 0.487 0.75 0.717 0.567
#............省略
Epoch gpu_mem GIoU obj cls total targets img_size
29/29 5.9G 3.86 5.09 1.23 10.2 152 416
Class Images Targets P R mAP@0.5 F1
all 64 544 0.379 0.848 0.763 0.506
30 epochs completed in 0.328 hours.
训练的模型权重保存在weights/last.pt,一些训练参数结果保存results.png文件,下面仅仅示例:
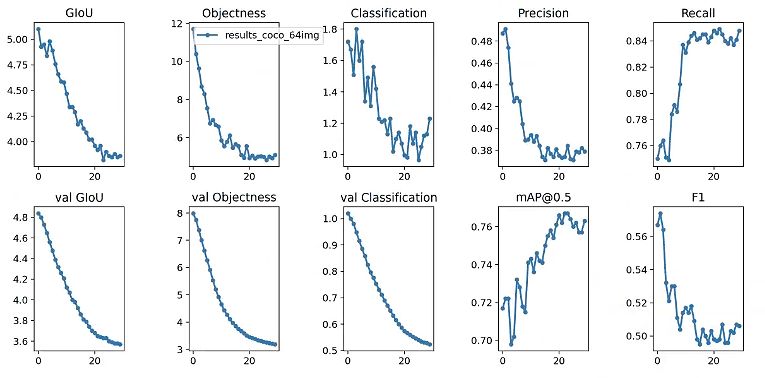
训练可视化:
# 执行命令:
tensorboard --logdir=runs --bind_all
# 输出
TensorFlow installation not found - running with reduced feature set.
TensorBoard 2.14.0 at http://anhao.:6006/ (Press CTRL+C to quit)
浏览器访问IP:6006,就可以看到:

可以查看训练的参数,结果图像等等。
8.2.4. 保存模型¶
前面正常训练完成后,会在weights目录下保存模型权重last.pt,为了在板卡上部署测试, 我们将其转换为darknet权重,主要是通过models.py中定义的的convert函数:
# 命令行使用命令python3,然后加载models,使用函数convert转换,并保存在weights/last.weights
python3
Python 3.8.18 (default, Sep 11 2023, 13:40:15)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> from models import *
>>> convert('cfg/yolov3.cfg', 'weights/last.pt')
8.3. 转换成rknn模型¶
rknn-toolkit2工具支持导入darknet权重和配置文件,然后转换模型成rknn模型。 我们使用前面保存的darknet权重和配置文件,使用rknn.load_darknet导入模型,然后转换成rknn模型,程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | if __name__ == '__main__':
MODEL_PATH = './yolov3.cfg'
WEIGHT_PATH = './last.weights'
RKNN_MODEL_PATH = './yolov3_416.rknn'
im_file = './dog_bike_car_416x416.jpg'
DATASET = './dataset.txt'
# Create RKNN object
rknn = RKNN(verbose=True)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[0, 0, 0], std_values=[255, 255, 255])
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_darknet(model=MODEL_PATH, weight=WEIGHT_PATH)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(im_file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
print('done')
input0_data = outputs[0]
np.save('./darknet_yolov3_416x416_0.npy', input0_data)
input1_data = outputs[1]
np.save('./darknet_yolov3_416x416_1.npy', input1_data)
input2_data = outputs[2]
np.save('./darknet_yolov3_416x416_2.npy', input1_data)
input0_data = input0_data.reshape(SPAN, LISTSIZE, GRID0, GRID0)
input1_data = input1_data.reshape(SPAN, LISTSIZE, GRID1, GRID1)
input2_data = input2_data.reshape(SPAN, LISTSIZE, GRID2, GRID2)
input_data = []
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov3_post_process(input_data)
image = cv2.imread(im_file)
if boxes is not None:
draw(image, boxes, scores, classes)
print('Save results to results.jpg!')
cv2.imwrite('result.jpg', image)
rknn.release()
|
这里简单讲解下后处理部分,模型输出三个特征图(1*255*13*13,1*255*26*26, 1*255*52*52), 经过reshape和transpose转置操作,转换成(13*13*3*85,26*26*3*85, 52*52*3*85),然后传入yolov3_post_process函数。
8.4. 部署运行rknn模型¶
8.4.1. 使用Toolkit Lite2部署测试¶
Toolkit Lite2的使用流程参考下前面 《RKNN Toolkit Lite2介绍》 。 下面是使用前面转换的yolov3模型,具体板端部署推理的程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | if __name__ == '__main__':
host_name = get_host()
if host_name == 'RK3566_RK3568':
rknn_model = RK3566_RK3568_RKNN_MODEL
elif host_name == 'RK3562':
rknn_model = RK3562_RKNN_MODEL
elif host_name == 'RK3588':
rknn_model = RK3588_RKNN_MODEL
else:
print("This demo cannot run on the current platform: {}".format(host_name))
exit(-1)
# Create RKNN object
rknn_lite = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(rknn_model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
# run on RK356x/RK3588 with Debian OS, do not need specify target.
if host_name == 'RK3588':
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)
else:
ret = rknn_lite.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(IMG_PATH)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# Inference
print('--> Running model')
outputs = rknn_lite.inference(inputs=[img])
#np.save('./onnx_yolov3_0.npy', outputs[0])
#np.save('./onnx_yolov3_1.npy', outputs[1])
#np.save('./onnx_yolov3_2.npy', outputs[2])
print('done')
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape(SPAN, LISTSIZE, GRID0, GRID0) # 3*85*13*13
input1_data = input1_data.reshape(SPAN, LISTSIZE, GRID1, GRID1)
input2_data = input2_data.reshape(SPAN, LISTSIZE, GRID2, GRID2)
input_data = []
input_data.append(np.transpose(input0_data, (2, 3, 0, 1))) # 13*13*3*85
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov3_post_process(input_data)
img = cv2.imread(IMG_PATH)
if boxes is not None:
draw(img, boxes, scores, classes)
# show output
print('Save results to results.jpg!')
cv2.imwrite("result.jpg", img)
rknn_lite.release()
|
使用Toolkit Lite2在板端部署推理和使用toolkit2在虚拟机上模拟推理步骤类似,而且对输出后处理的程序也是相同的, 运行输出(测试板卡是lubancat-4):
cat@lubancat:~/yolov3$ python3 yolov3_inference.py
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [11:08:35.597] RKNN Runtime Information: librknnrt version: 1.5.0 (e6fe0c678@2023-05-25T08:09:20)
I RKNN: [11:08:35.597] RKNN Driver Information: version: 0.8.8
I RKNN: [11:08:35.598] RKNN Model Information: version: 4, toolkit version: 1.5.0+1fa95b5c(compiler version: 1.5.0 (e6fe0c678@2023-05-25T16:15:03)), target: RKNPU v2, target platform: rk3588, framework name: DarkNet, framework layout: NCHW, model inference type: static_shape
done
--> Running model
W RKNN: [11:08:35.821] Output(082_convolutional): size_with_stride larger than model origin size, if need run OutputOperator in NPU, please call rknn_create_memory using size_with_stride.
W RKNN: [11:08:35.821] Output(094_convolutional): size_with_stride larger than model origin size, if need run OutputOperator in NPU, please call rknn_create_memory using size_with_stride.
W RKNN: [11:08:35.821] Output(106_convolutional): size_with_stride larger than model origin size, if need run OutputOperator in NPU, please call rknn_create_memory using size_with_stride.
done
class: dog , score: 0.9610940217971802
box coordinate left,top,right,down: [0.17077204585075378, 0.42468398809432983, 0.40588340163230896, 0.9006455832949052]
class: bicycle, score: 0.5884601473808289
box coordinate left,top,right,down: [0.15359708666801453, 0.20998646318912506, 0.7157543668380151, 0.7840401501609728]
class: truck , score: 0.9271844625473022
box coordinate left,top,right,down: [0.5911217331886292, 0.15932360291481018, 0.916921371450791, 0.2754164951351973]
Save results to results.jpg!
结果图片:
