
9. YOLOv5(实例分割)¶
YOLOv5 增加了对实例分割和分类的支持。 实例分割(图像分割)是一项计算机视觉任务,识别图像中的对象及其相关形状,不仅要标注出物体位置,还需要标注出物体的外形轮廓。 实例分割在检测物体对象大小、从背景中裁剪出对象、检测旋转对象等方面非常有用。
YOLOV5 实例分割有五个不同尺寸的模型,其中最小的实例分割模型是yolov5n-seg,只有200万个参数(mask精度只有23.4),适合部署到边缘和移动设备。 其中最准确的模型是yolov5x-seg,但速度也是最慢的。
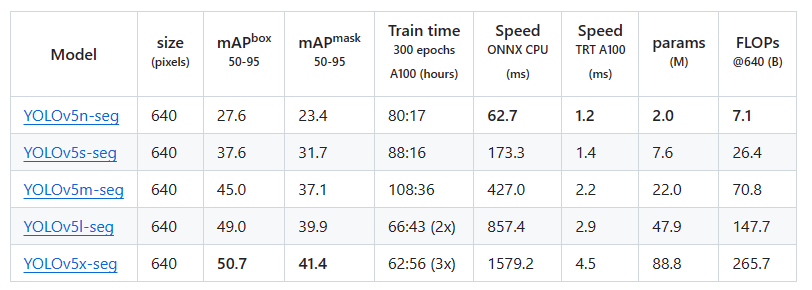
YOLOv5实例分割在COCO数据集上和其他模型的精度和速度对比:
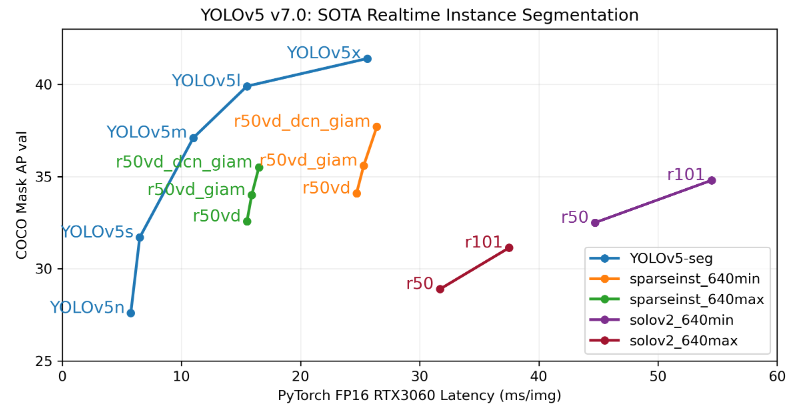
本章将简单测试下YOLOv5-seg模型以及讲解下yolov5-seg模型的输出结果,然后介绍下对rknpu部署优化的airockchip/yolov5仓库, 最后测试下yolov5-seg模型部署到板卡。
9.1. YOLOV5实例分割¶
在PC上创建环境,拉取yolov5仓库源码,安装依赖,然后简单测试YOLOV5实例分割。
# 安装anaconda参考前面环境搭建教程,然后使用conda命令创建环境
conda create -n yolov5 python=3.9
conda activate yolov5
# 拉取最新的yolov5(教程测试时是v7.0),可以指定下版本分支
# git clone https://github.com/ultralytics/yolov5.git -b v7.0
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装依赖库
pip3 install -r requirements.txt
9.1.1. YOLOV5实例分割测试¶
拉取源码后,我们将使用segment/predict.py 对图片或者视频进行简单的实例分割测试。
# segment/predict.py的参数说明,
# --weights 指定模型权重文件,默认使用官方的权重文件,第一次使用时会自动下载权重文件。
# --source 指定测试图片或者视频文件
(yolov5) llh@anhao:~/yolov5$ python segment/predict.py --weights yolov5n-seg.pt --source ../input/images/image_1.jpg
segment/predict: weights=['yolov5n-seg.pt'], source=./data/images/bus.jpg, data=data/coco128.yaml, imgsz=[640, 640],
conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False,
nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/predict-seg,
name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1, retina_masks=False
YOLOv5 🚀 v7.0-253-g63555c8 Python-3.9.18 torch-2.1.2+cu121 CUDA:0 (NVIDIA GeForce RTX 3060 Laptop GPU, 6144MiB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt to yolov5n-seg.pt...
100%|██████████████████████████████████████████████████████████████████████████████████████████| 4.11M/4.11M [00:00<00:00, 7.73MB/s]
Fusing layers...
YOLOv5n-seg summary: 224 layers, 1986637 parameters, 0 gradients, 7.1 GFLOPs
image 1/1 /home/llh/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 1 skateboard, 73.2ms
Speed: 0.7ms pre-process, 73.2ms inference, 320.7ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/predict-seg/exp
测试图片结果保存在runs/predict-seg/exp目录下。

9.1.2. yolov5-seg模型输出¶
yolov5-seg是基于目标检测的代码框架,其训练、测试、验证等代码的入口,在源码segment文件夹下,源码架构和目标检测的一致, 主要修改了数据集、网络部分、loss和评价指标部分。
网络结构上,通过yaml文件搭建网络,分割和检测的模型网络除了head最后一层不同,前面的保持一致, 以yolov5s-seg.yaml和yolov5s.yaml对比为例(YOLOv5 V7.0),如下图所示:
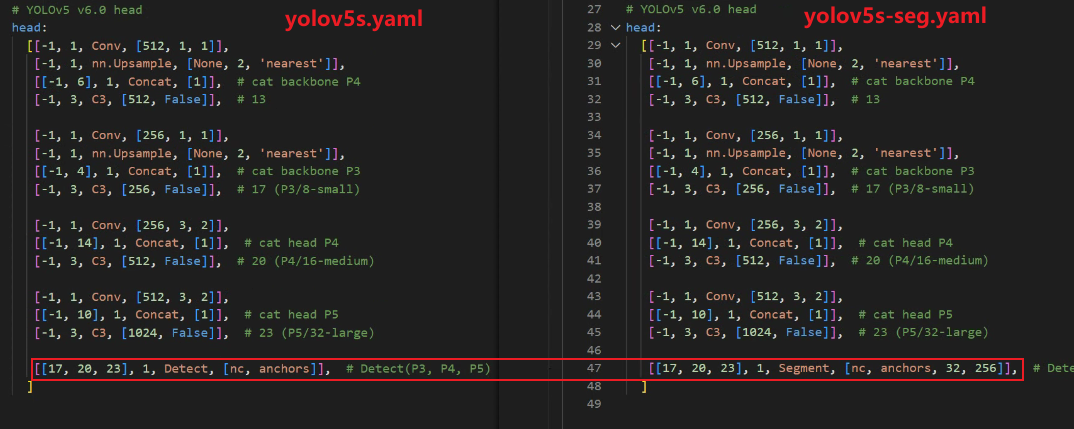
网络中的Segment分割模块继承自目标检测中Detect模块,增加了每个检测框的mask系数, 还在检测的基础上增加了一个“Proto”的神经网络,用于输出检测对象掩码(Mask):
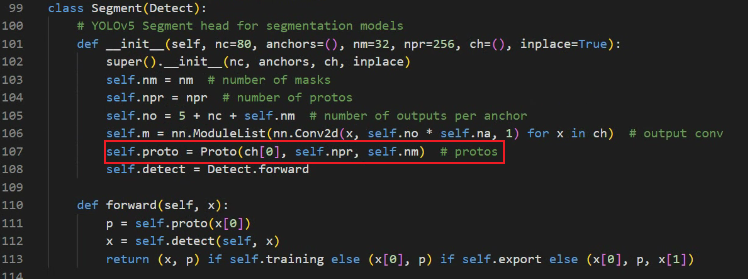
详细请参考源码yolo.py。
再来看下yolov5-seg模型的输出,先导出onnx模型,使用下面命令:
# --weights 指定模型权重文件,默认使用官方的权重文件,第一次使用时会自动下载权重文件。
(yolov5) llh@anhao:~/yolov5$ python export.py --weights yolov5n-seg.pt --include onnx
export: data=data/coco128.yaml, weights=['yolov5s-seg.pt'], imgsz=[640, 640], batch_size=1,
device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, per_tensor=False,
dynamic=False, simplify=False, opset=17, verbose=False, workspace=4, nms=False,
agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-253-g63555c8 Python-3.9.18 torch-2.1.2+cu121 CPU
Fusing layers...
YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs
PyTorch: starting from yolov5s-seg.pt with output shape (1, 25200, 117) (14.9 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 1.1s, saved as yolov5s-seg.onnx (29.5 MB)
Results saved to /home/llh/yolov5
Detect: python segment/predict.py --weights yolov5s-seg.onnx
Validate: python segment/val.py --weights yolov5s-seg.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-seg.onnx')
# WARNING ⚠️ SegmentationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
模型保存在当前目录下yolov5s-seg.onnx,然后使用 Netron 可视化模型:
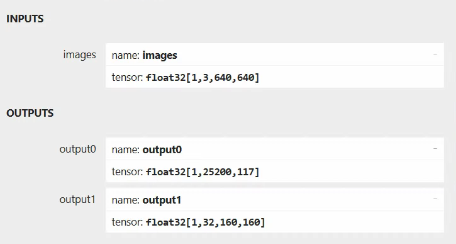
可以看到yolov5-seg的结果分为两部分,”output0”是检测的结果,维度为1*25200*177,第一维度是batch size,第二个维度表示25200条输出(3*[80*80+40*40+20*20]), 第三维度是117(85+32),其中前面85字段包括四个坐标属性(cx、cy、w、h)、一个confidence和80个类别分数,后面32个字段是每个检测框的mask系数。 “output1”是分割结果(mask),维度为32 * 160 * 160。
目标检测部分后处理和yolov5检测是一致的,实例分割部分后处理部分需要将目标框里面的mask系数与原型mask进行加权求和,从而得到实例分割的效果。
9.2. airockchip/yolov5测试¶
测试在rknn上部署yolov5-seg模型,我看可以使用前面ultralytics/yolov5源码修改模型后处理网络结构, 也可以使用rknn官方的 airockchip/yolov5 仓库, 该仓库的yolov5对rknpu设备进行了部署优化:
优化focus/SPPF块,以相同的结果获得更好的性能;
更改输出节点,从模型中删除post_process(检测和分割后处理量化方面不友好);
使用ReLU代替SiLU作为激活层(仅在使用该仓库训练新模型时才会替换)。
我们可以使用该仓库直接训练导出导出适配RKNPU的模型,或者使用ultralytics/yolov5训练模型,使用该仓库导出适配RKNPU的模型。
9.2.1. 导出模型¶
这里测试直接使用ultralytics/yolov5仓库的权重文件,然后通过airockchip/yolov5仓库的export.py导出onnx模型。
# 获取权重文件
# wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt
# 导出onnx模型,不指定--include,默认导出onnx模型
(yolov5) llh@anhao:~/airockchip/yolov5$ python export.py --rknpu --weights yolov5s-seg.pt --include onnx
export: data=data/coco128.yaml, weights=['yolov5s-seg.pt'], imgsz=[640, 640], batch_size=1,
device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False,
simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100,
topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx'], rknpu=True
YOLOv5 🚀 v4.0-1657-gd25a075 Python-3.9.18 torch-2.1.2+cu121 CPU
Fusing layers...
YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs
---> save anchors for RKNN
[[10.0, 13.0], [16.0, 30.0], [33.0, 23.0], [30.0, 61.0], [62.0, 45.0], [59.0, 119.0], [116.0, 90.0], [156.0, 198.0], [373.0, 326.0]]
export segment model for RKNPU
PyTorch: starting from yolov5s-seg.pt with output shape (1, 255, 80, 80) (14.9 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 0.8s, saved as yolov5s-seg.onnx (29.1 MB)
Export complete (2.5s)
Results saved to /home/llh/airockchip/yolov5
Detect: python segment/detect.py --weights yolov5s-seg.onnx
Validate: python segment/val.py --weights yolov5s-seg.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-seg.onnx')
# WARNING ⚠️ SegmentationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
yolov5s-seg.onnx模型保存在当前目录下,并且生成了一个RK_anchors.txt文件,该文件保存了anchors的值,用在后面板卡C++部署。
我们可以使用 Netron 查看下yolov5s-seg.onnx模型,其模型输出如下图所示:
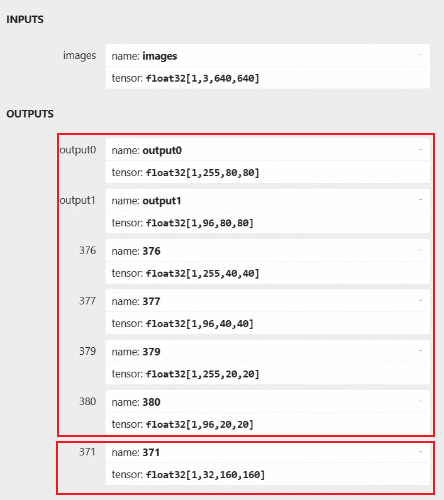
输出主要分为两部分,一部分是检测结果,另一部分是分割结果。由于后处理部分量化方面不是很好,其模型后处理部分放到CPU处理, 模型直接输出三种尺寸的特征图。
以特征图大小80*80为例,相关输出节点有两个(实例分割掩码数据和目标检测分开):1*255*80*80和1*96*80*80, 前一个节点1*[3*(80+5)]*80*80中,3代表了每个网格的3个anchor,(5+80)代表每个anchor包含的信息。其中5表示4个位置坐标(x,y,w,h)和一个置信度, 置信度表示这个网格中可能存在物体的概率,其中80表示coco数据集80个类别的分数;后一个节点1*[3*32]*80*80表示检测框mask系数。
最后的“371”节点是模型分割结果,后处理通过与目标框里面的mask系数矩阵乘法,处理后得到最终的分割效果。
9.2.2. 转换成rknn模型以及简单测试¶
我们接下来使用rknn-toolkit2工具(rknn-toolkit2环境安装请参考下前面章节)将onnx模型转换成rknn模型,并简单测试一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=False)
# 默认平台是rk3588,如果需要其他平台,需要修改platform
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
print('done')
# 默认模型路径是./yolov5s-seg.onnx,如果需要修改,需要修改MODEL_PATH
print('--> Loading model')
ret = rknn.load_onnx(model=MODEL_PATH)
#ret = rknn.load_pytorch(model=MODEL_PATH, input_size_list=[[1, 3, 640, 640]])
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=DEFAULT_QUANT, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
rknn.release()
|
修改onnx2rknn.py程序中的模型路径、导出模型路径以及平台,然后运行程序导出rknn模型(默认开启量化), 默认保存在当前目录/model/yolov5s_seg.rknn。
(toolkit2_1.6) llh@YH-LONG:/home/llh/yolov5-seg$ python onnx2rknn.py
W __init__: rknn-toolkit2 version: 1.6.0+81f21f4d
--> Config model
done
--> Loading model
W load_onnx: It is recommended onnx opset 19, but your onnx model opset is 12!
W load_onnx: Model converted from pytorch, 'opset_version' should be set 19 in torch.onnx.export for successful convert!
Loading : 100%|█████████████████████████████████████████████████| 183/183 [00:00<00:00, 9503.24it/s]
done
--> Building model
W build: found outlier value, this may affect quantization accuracy
const name abs_mean abs_std outlier value
onnx::Conv_499 0.97 1.89 26.467
GraphPreparing : 100%|██████████████████████████████████████████| 210/210 [00:00<00:00, 5598.80it/s]
Quantizating : 100%|█████████████████████████████████████████████| 210/210 [00:01<00:00, 188.84it/s]
W build: The default input dtype of 'images' is changed from 'float32' to 'int8' in rknn model for performance!
Please take care of this change when deploy rknn model with Runtime API!
# 省略
done
--> Export rknn model
done
使用rknn-toolkit2工具的连板测试功能,需要板卡通过usb adb或者网络adb连接主机,确认adb连接正常后,启动板卡端的rknn_server, 具体请简单参考下 前面章节 的操作步骤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | if __name__ == '__main__':
rknn = RKNN()
rknn.list_devices()
# 加载rknn模型
rknn.load_rknn(path=rknn_model_path)
# 设置运行环境,目标默认是rk3588
ret = rknn.init_runtime(target=target, device_id=device_id)
# 输入图像
img_src = cv2.imread(img_path)
if img_src is None:
print("Load image failed!")
exit()
src_shape = img_src.shape[:2]
img, ratio, (dw, dh) = letter_box(img_src, IMG_SIZE)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 推理运行
print('--> Running model')
outputs = rknn.inference(inputs=[img])
print('done')
# 后处理
boxes, classes, scores, seg_img = post_process(outputs, anchors)
if boxes is not None:
real_boxs = get_real_box(src_shape, boxes, dw, dh, ratio)
real_segs = get_real_seg(src_shape, IMG_SIZE, dw, dh, seg_img)
img_p = merge_seg(img_src, real_segs, classes)
draw(img_p, real_boxs, scores, classes)
cv2.imwrite("result.jpg", img_p)
|
测试例程需要修改设备ID、模型路径以及目标平台,运行程序处理结果保存在result.jpg。
(toolkit2_1.6) llh@YH-LONG:/home/llh/yolov5-seg$ python test.py
W __init__: rknn-toolkit2 version: 1.6.0+81f21f4d
*************************
all device(s) with adb mode:
192.168.103.150:5555
*************************
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:36)
D RKNNAPI: ==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 1.6.0 (535b468 build@2023-12-11T09:05:46)
D RKNNAPI: DRV: rknn_server: 1.5.0 (17e11b1 build: 2023-05-18 21:43:39)
D RKNNAPI: DRV: rknnrt: 1.6.0 (9a7b5d24c@2023-12-13T17:31:11)
D RKNNAPI: ==============================================
D RKNNAPI: Input tensors:
D RKNNAPI: index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800,
w_stride = 0, size_with_stride = 0, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
D RKNNAPI: Output tensors:
D RKNNAPI: index=0, name=output0, n_dims=4, dims=[1, 255, 80, 80], n_elems=1632000, size=1632000,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003902
D RKNNAPI: index=1, name=output1, n_dims=4, dims=[1, 96, 80, 80], n_elems=614400, size=614400,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=18, scale=0.018347
D RKNNAPI: index=2, name=376, n_dims=4, dims=[1, 255, 40, 40], n_elems=408000, size=408000,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
D RKNNAPI: index=3, name=377, n_dims=4, dims=[1, 96, 40, 40], n_elems=153600, size=153600,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=32, scale=0.019994
D RKNNAPI: index=4, name=379, n_dims=4, dims=[1, 255, 20, 20], n_elems=102000, size=102000,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003917
D RKNNAPI: index=5, name=380, n_dims=4, dims=[1, 96, 20, 20], n_elems=38400, size=38400,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=35, scale=0.021878
D RKNNAPI: index=6, name=371, n_dims=4, dims=[1, 32, 160, 160], n_elems=819200, size=819200,
w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-110, scale=0.015716
--> Running model
W inference: The 'data_format' is not set, and its default value is 'nhwc'!
done
person @ (744 41 1152 711) 0.841
person @ (143 203 847 714) 0.806
tie @ (434 439 499 709) 0.704
使用rknn-toolkit2工具连接板子测试,还可以进行精度分析,内存评估等操作,具体参考下rknn-toolkit2手册。
9.2.3. 板卡上部署测试¶
接下来将参考 rknn_model_zoo仓库 提供的C++部署例程, 在板卡上进行部署测试,教程测试例程请参考配套例程。
教程测试是在lubancat-4板卡上:
# 安装相关软件等等
sudo apt update
sudo apt install libopencv-dev git cmake make gcc g++ libsndfile1-dev
# 拉取配套例程程序或者rknn_model_zoo仓库程序到板卡
cat@lubancat:~$ git clone https://gitee.com/LubanCat/lubancat_ai_manual_code.git
cat@lubancat:~$ cd lubancat_ai_manual_code/example/yolov5_seg/cpp
# 板卡上直接编译例程(需要安装cmake和gcc), 运行build-linux.sh脚本,-t指定目标板卡(教程测试是lubancat-4,rk3588),
# -d是使能rga2分配内存在小于4G地址, -z是使能使用零拷贝接口(rknn模型i8量化)
cat@lubancat:~/lubancat_ai_manual_code/example/yolov5_seg/cpp$ ./build-linux.sh -t rk3588 -d -z
./build-linux.sh -t rk3588 -d -z
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/home/cat/yolov8/rknn_model_zoo/examples/yolov5_seg/cpp_test/install/rk3588_linux
BUILD_DIR=/home/cat/yolov8/rknn_model_zoo/examples/yolov5_seg/cpp_test/build/build_rk3588_linux
ENABLE_DMA32=TRUE
ENABLE_ZERO_COPY=TRUE
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
-- The C compiler identification is GNU 10.2.1
-- The CXX compiler identification is GNU 10.2.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/aarch64-linux-gnu-gcc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/aarch64-linux-gnu-g++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found OpenCV: /usr (found version "4.5.1")
-- Configuring done
-- Generating done
-- Build files have been written to: /home/cat/yolov8/rknn_model_zoo/examples/yolov5_seg/cpp_test/build/build_rk3588_linux
Scanning dependencies of target rknn_yolov5seg_demo
Scanning dependencies of target yolov5seg_videocapture_demo
[ 20%] Building CXX object CMakeFiles/rknn_yolov5seg_demo.dir/postprocess.cc.o
[ 20%] Building CXX object CMakeFiles/rknn_yolov5seg_demo.dir/yolov5seg_demo.cc.o
[ 40%] Building CXX object CMakeFiles/yolov5seg_videocapture_demo.dir/yolov5seg_videocapture_demo.cc.o
[ 40%] Building CXX object CMakeFiles/yolov5seg_videocapture_demo.dir/postprocess.cc.o
# 省略
最后程序保存在install/rk3588_linux目录下,例程默认将生成两个程序:rknn_yolov5seg_demo 和yolov5seg_videocapture_demo。
运行rknn_yolov5seg_demo例程,程序将使用npu推理处理,并保存结果;
# 查看安装目录下的文件
cat@lubancat:~/lubancat_ai_manual_code/example/yolov5_seg/cpp/install/rk3588_linux$ ls
lib model rknn_yolov5seg_demo yolov5seg_videocapture_demo
# 运行程序,rknn_yolov5seg_demo <model_path> <image_path>
cat@lubancat:~/xxx$ ./rknn_yolov5seg_demo ./model/yolov5s_seg.rknn ./model/bus.jpg
load lable ./model/coco_80_labels_list.txt
rknn_api/rknnrt version: 1.6.0 (9a7b5d24c@2023-12-13T17:31:11), driver version: 0.9.2
model input num: 1, output num: 7
input tensors:
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800,
size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
output tensors:
index=0, name=output0, n_dims=4, dims=[1, 255, 80, 80], n_elems=1632000,
size=1632000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003902
index=1, name=output1, n_dims=4, dims=[1, 96, 80, 80], n_elems=614400,
size=614400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=18, scale=0.018347
index=2, name=376, n_dims=4, dims=[1, 255, 40, 40], n_elems=408000,
size=408000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
index=3, name=377, n_dims=4, dims=[1, 96, 40, 40], n_elems=153600,
size=153600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=32, scale=0.019994
index=4, name=379, n_dims=4, dims=[1, 255, 20, 20], n_elems=102000,
size=102000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003917
index=5, name=380, n_dims=4, dims=[1, 96, 20, 20], n_elems=38400,
size=38400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=35, scale=0.021878
index=6, name=371, n_dims=4, dims=[1, 32, 160, 160], n_elems=819200,
size=819200, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-110, scale=0.015716
model is NHWC input fmt
model input height=640, width=640, channel=3
scale=1.000000 dst_box=(0 0 639 639) allow_slight_change=1 _left_offset=0
_top_offset=0 padding_w=0 padding_h=0
src width=640 height=640 fmt=0x1 virAddr=0x0x7f923a5040 fd=0
dst width=640 height=640 fmt=0x1 virAddr=0x0x7f73b12000 fd=17
src_box=(0 0 639 639)
dst_box=(0 0 639 639)
color=0x72
rga_api version 1.10.0_[2]
rknn_run
person @ (212 242 285 512) 0.871
person @ (111 242 224 534) 0.857
person @ (473 233 558 521) 0.826
bus @ (100 133 547 460) 0.820
person @ (79 328 125 519) 0.491
rknn run and process use 58.080000 ms
结果保存在当前目录out.jpg,例程测试如下图所示:

在桌面终端运行yolov5seg_videocapture_demo例程,将摄像头捕捉的图像进行推理处理,并显示。
# yolov5seg_videocapture_demo <model path> </path/xxxx.mp4> / <0/1/2>
# 教程测试将调用摄像头,命令如下:
cat@lubancat:~/xxx/yolov5_seg/cpp/install/rk3588_linux$ ./yolov5seg_videocapture_demo ./model/yolov5s_seg.rknn 0
[ WARN:0] global ../modules/videoio/src/cap_gstreamer.cpp (961) open OpenCV | GStreamer
warning: Cannot query video position: status=0, value=-1, duration=-1
load lable ./model/coco_80_labels_list.txt
model input num: 1, output num: 7
# 省略.....................
model is NHWC input fmt
model input height=640, width=640, channel=3
scale=1.000000 dst_box=(0 80 639 559) allow_slight_change=1 _left_offset=0
_top_offset=80 padding_w=0 padding_h=160
src width=640 height=480 fmt=0x1 virAddr=0x0x55773e6280 fd=0
dst width=640 height=640 fmt=0x1 virAddr=0x0x7f71673000 fd=21
src_box=(0 0 639 479)
dst_box=(0 80 639 559)
color=0x72
rga_api version 1.10.0_[2]
fill dst image (x y w h)=(0 0 640 640) with color=0x72727272
rknn_run
person @ (359 302 435 409) 0.728
tv @ (584 344 639 403) 0.709
laptop @ (512 372 582 416) 0.560
person @ (323 338 364 403) 0.334
chair @ (443 381 493 407) 0.271
clock @ (545 229 599 283) 0.251
chair @ (426 408 640 478) 0.154
Infer time(ms): 58.269001 ms
scale=1.000000 dst_box=(0 80 639 559) allow_slight_change=1 _left_offset=0
_top_offset=80 padding_w=0 padding_h=160
src width=640 height=480 fmt=0x1 virAddr=0x0x55773e6280 fd=0
dst width=640 height=640 fmt=0x1 virAddr=0x0x7f680b0000 fd=34
src_box=(0 0 639 479)
dst_box=(0 80 639 559)
color=0x72
fill dst image (x y w h)=(0 0 640 640) with color=0x72727272
rknn_run
Infer time(ms): 38.993999 ms
# .....
# 在窗口按下ESC或者在桌面终端ctrl+c退出程序
测试前需要确认摄像头是否连接成功,另外例程会使用opencv,需要确认系统中安装了opencv(opencv4), 如果是使用自行编译的opencv需要修改例程的CMakeLists.txt文件,将opencv库的路径修改正确,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | cmake_minimum_required(VERSION 3.10)
project(rknn_yolov5seg_demo)
set(CMAKE_INSTALL_RPATH "$ORIGIN/lib")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread")
# 查找系统默认opencv
#find_package(OpenCV REQUIRED)
# 查找自行编译安装的OpenCV,请修改下面的OpenCV_DIR路径
set(OpenCV_DIR /path/opencv/lib/cmake/opencv4)
find_package(OpenCV REQUIRED)
file(GLOB OpenCV_FILES "${OpenCV_DIR}/../../libopencv*")
install(PROGRAMS ${OpenCV_FILES} DESTINATION lib)
# 后面省略
# .....
|