4. PP-LitetSeg¶
语义分割是计算机视觉任务之一,可以从像素层次来识别图像,也即为图像中的每个像素指定类别标记,在自动驾驶,医学图像等领域中有广泛的需求。
PP-LitetSeg 是一个新的轻量级实时语义分割模型。 PP-LitetSeg提出了一种灵活且轻量级的解码器 (FLD),以减少先前解码器的计算开销。 为了加强特征表示,使用了一个统一注意力融合模块(UAFM),它利用空间和通道注意力来产生权重,然后将输入特征与权重融合。 此外,提出了一个简单的金字塔池模块(SPPM)以低计算成本聚合全局上下文。
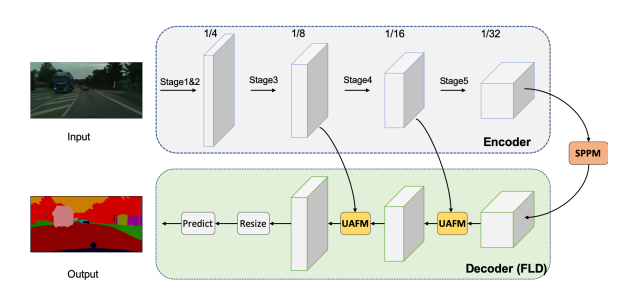
PP-LitetSeg具体详情请查看 PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model 。
本章将简单推理测试下PP-LitetSeg模型,然后在鲁班猫rk系列板卡上部署测试。
4.1. PP-LitetSeg推理测试¶
安装PaddlePaddle和PaddleSeg环境:
# 使用conda创建虚拟环境
conda create -n ppseg python=3.9
conda activate ppseg
# 根据个人环境安装,下面安装PaddlePaddle命令仅仅是参考
python -m pip install paddlepaddle-gpu==2.6.1.post116 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# 准备PaddleSeg,或者pip install PaddleSeg,教程测试是release/2.9.1
git clone -b release/2.9.1 https://github.com/PaddlePaddle/PaddleSeg.git
cd PaddleSeg
pip install -r requirements.txt
PaddlePaddle具体安装请参考下 PaddlePaddle官网
PP-LitetSeg有各种模型,测试使用参考下 README.md 。
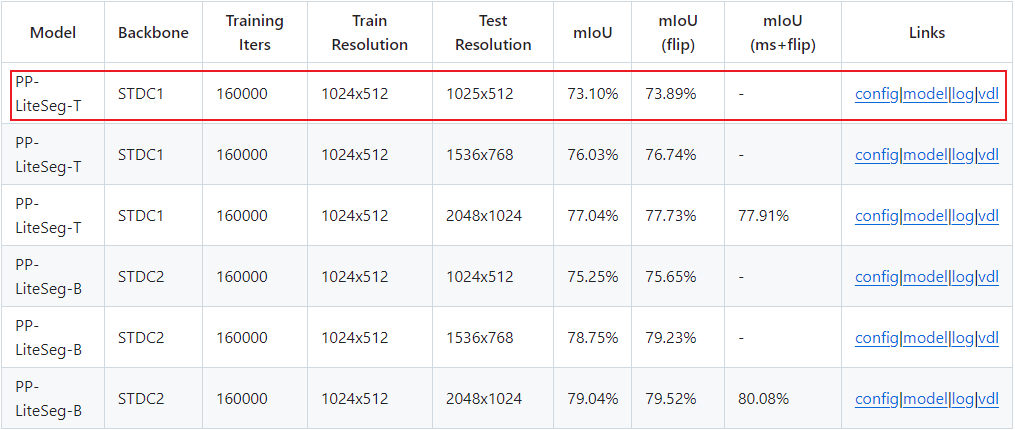
教程测试使用PP-LiteSeg-T模型,基于 Cityscapes 数据集,使用了19个类别标注。 Cityscapes数据集有5000张在城市环境中驾驶场景的图像(2975train,500 val,1525 test) ,有30个像素类别标注,图像分辨率为2048*1024。
获取训练好的模型权重,然后进行简单的推理测试:
# 获取权重文件
wget https://paddleseg.bj.bcebos.com/dygraph/cityscapes/pp_liteseg_stdc1_cityscapes_1024x512_scale0.5_160k/model.pdparams
# 获取测试图片
wget https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
# 推理预测, --model_path指定模型权重路径,--image_path指定待预测的图片路径,--save_dir指定预测结果保存路径
(ppseg)root@xxx/PaddleSeg# python tools/predict.py --config configs/pp_liteseg/pp_liteseg_stdc1_cityscapes_1024x512_scale0.5_160k.yml
--model_path ../model/model.pdparams --image_path ../cityscapes_demo.png --save_dir output/result
# 省略.........
model:
backbone:
in_channels: 3
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
type: STDC1
num_classes: 19
type: PPLiteSeg
W1021 16:35:23.245410 206 gpu_resources.cc:119] Please NOTE: device: 0,
GPU Compute Capability: 8.6, Driver API Version: 12.2, Runtime API Version: 11.7
W1021 16:35:23.245702 206 gpu_resources.cc:149] device: 0, cuDNN Version: 8.5.
[2024/10/11 16:35:32] INFO: Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
[2024/10/11 16:35:32] INFO: There are 265/265 variables loaded into STDCNet.
[2024/10/11 16:35:32] INFO: The number of images: 1
[2024/10/11 16:35:32] INFO: Loading pretrained model from ../model/model.pdparams
[2024/10/11 16:35:33] WARNING: ppseg_head.arm_list.0._scale is not in pretrained model
[2024/10/11 16:35:33] WARNING: ppseg_head.arm_list.1._scale is not in pretrained model
[2024/10/11 16:35:33] WARNING: ppseg_head.arm_list.2._scale is not in pretrained model
[2024/10/11 16:35:33] INFO: There are 367/370 variables loaded into PPLiteSeg.
[2024/10/11 16:35:33] INFO: Start to predict...
1/1 [==============================] - 15s 15s/step
[2024/10/11 16:35:48] INFO: Predicted images are saved in output/result/added_prediction and output/result/pseudo_color_prediction .
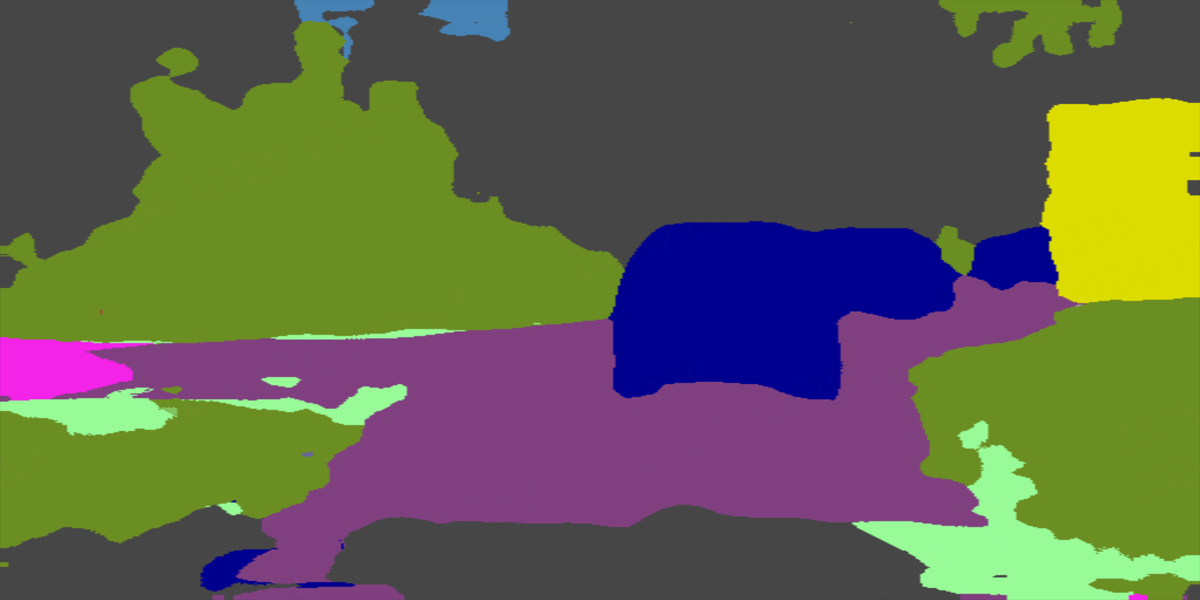
在output/result目录下查看added_prediction测试结果:

也可以自行设置配置文件,训练模型。
4.2. 导出onnx模型¶
使用PaddleSeg工程文件tools/export.py导出模型:
# 获取权重文件
wget https://paddleseg.bj.bcebos.com/dygraph/cityscapes/pp_liteseg_stdc1_cityscapes_1024x512_scale0.5_160k/model.pdparams
# 推理预测, --model_path指定模型权重路径,--image_path指定待预测的图片路径,--save_dir指定预测结果保存路径
(ppseg)root@xxx/PaddleSeg#python tools/export.py --config configs/pp_liteseg/pp_liteseg_stdc1_cityscapes_1024x512_scale0.5_160k.yml
--input_shape 1 3 512 512 --output_op none --model_path ../model/model.pdparams --save_dir ../output/test
# 省略.........
model:
backbone:
in_channels: 3
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
type: STDC1
type: PPLiteSeg
test_config:
aug_eval: true
scales: 0.5
------------------------------------------------
I1021 17:19:34.281154 661 interpretercore.cc:237] New Executor is Running.
[2024/10/11 17:19:35] INFO:
---------------Deploy Information---------------
Deploy:
input_shape:
- 1
- 3
- 512
- 512
model: model.pdmodel
output_dtype: float32
output_op: none
params: model.pdiparams
transforms:
- type: Normalize
[2024/10/11 17:19:36] INFO: The inference model is saved in ../output/test
导出paddle静态图模型,为了能在开发板上部署input_shape设置为1*3*512*512,设置output_op为none。 使用命令导出模型后,在output/test目录下查看导出模型:
output/test
├── deploy.yaml # 部署相关的配置文件,主要说明数据预处理方式等信息
├── model.pdmodel # 预测模型的拓扑结构文件
├── model.pdiparams # 预测模型的权重文件
└── model.pdiparams.info # 参数额外信息,一般无需关注
使用Paddle2onnx工具,将paddle模型转换成onnx模型:
# 切换到output/test目录
cd output/test
# 使用paddle2onnx工具将paddle静态图模型转换成onnx模型
paddle2onnx --model_dir ./ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 11 \
--save_file pp_liteseg_cityscapes_512.onnx
4.3. 转换成rknn模型¶
安装toolkit2工具,然后使用例程python目录下的convert.py将onnx模型转换成rknn模型:
# 获取配套例程(//待加),或者rknn_model_zoo
git clone https://github.com/airockchip/rknn_model_zoo
#
# 切换到例程目录
cd examples/ppseg/python
# 进入toolkit2环境,使用命令导出rknn模型,教程测试lubancat-4,设置平台rk3588(请根据具体板卡芯片设置目标)
# Usage: python3 convert.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
(toolkit2.2) root@xxx:/xxx$ python convert.py ./pp_liteseg_cityscapes_512.onnx rk3588 i8
I rknn-toolkit2 version: 2.2.0
--> Config model
done
--> Loading model
done
--> Building model
I Loading : 100%|██████████████████████████████████████████████| 285/285 [00:00<00:00, 71742.69it/s]
I OpFusing 0: 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 1106.73it/s]
I OpFusing 1 : 67%|██████████████████████████████▊ | 67/100 [00:00<00:00, 525.29it/s]W build:
Resize [Resize.4] convert to Deconvolution for inference speedup, but may cause result driftting.
To disable this optimization, please set 'optimization_level = 2' in 'rknn.config'
I OpFusing 1 : 80%|████████████████████████████████████▊ | 80/100 [00:00<00:00, 603.91it/s]W build:
Resize [Resize.5] convert to Deconvolution for inference speedup, but may cause result driftting.
To disable this optimization, please set 'optimization_level = 2' in 'rknn.config'
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 351.01it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 252.44it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 237.95it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 228.29it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 213.91it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 202.92it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 116.10it/s]
I GraphPreparing : 100%|███████████████████████████████████████| 156/156 [00:00<00:00, 12041.95it/s]
I Quantizating : 100%|████████████████████████████████████████████| 156/156 [00:03<00:00, 42.65it/s]
W build: The default input dtype of 'x' is changed from 'float32' to 'int8' in rknn model for performance!
Please take care of this change when deploy rknn model with Runtime API!
W build: The default output dtype of 'bilinear_interp_v2_6.tmp_0' is changed from 'float32' to 'int8' in rknn model for performance!
Please take care of this change when deploy rknn model with Runtime API!
I rknn building ...
I rknn buiding done.
done
--> Export rknn model
done
4.4. 板卡上部署测试¶
获取部署测试例程,然后板卡上直接编译:
# 安装相关软件等等
sudo apt update
sudo apt install git cmake make gcc g++ libsndfile1-dev
# 获取配套例程,或者rknn_model_zoo
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code.git
#git clone https://github.com/airockchip/rknn_model_zoo
# 切换到例程目录ppseg
# 编译,教程测试lubancat-4,设置平台rk3588(请根据具体板卡芯片设置目标)
./build-linux.sh -t rk3588
运行程序,执行命令:
# 切换到可执行程序目录
# ./rknn_ppseg_demo <model_path> <image_path>
cat@lubancat:~/xxx/install/rk3588_linux$ ./rknn_ppseg_demo ../../pp_liteseg_cityscapes_512.rknn cityscapes_demo.png
model input num: 1, output num: 1
input tensors:
index=0, name=x, n_dims=4, dims=[1, 512, 512, 3], n_elems=786432, size=786432, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-19, scale=0.018054
output tensors:
index=0, name=bilinear_interp_v2_6.tmp_0, n_dims=4, dims=[1, 19, 512, 512], n_elems=4980736, size=4980736, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-32, scale=0.077175
model is NHWC input fmt
model input height=512, width=512, channel=3
convert image use cpu
finish
rknn_run
rknn run cost: 39.433 ms
convert image use cpu
finish
write_image path: ./result.png width=2048 height=1024 channel=3 data=0x555ec4e6f0
测试结果为result.png: