
6. ViT¶
ViT(vision transformer)是谷歌团队在2020年提出的将Transformer应用在图像分类的模型。 ViT是Encoder-only结构,其思想简单有效且具有良好的扩展性,被视为Transformer在计算机视觉领域应用的重要里程碑之一。
模型结构如下图所示,通过实验结果可知,在中等规模的数据集上进行训练时, ViT并未表现出比ResNet更好的性能,但随着数据集规模的增大,ViT表现出了优越的性能。
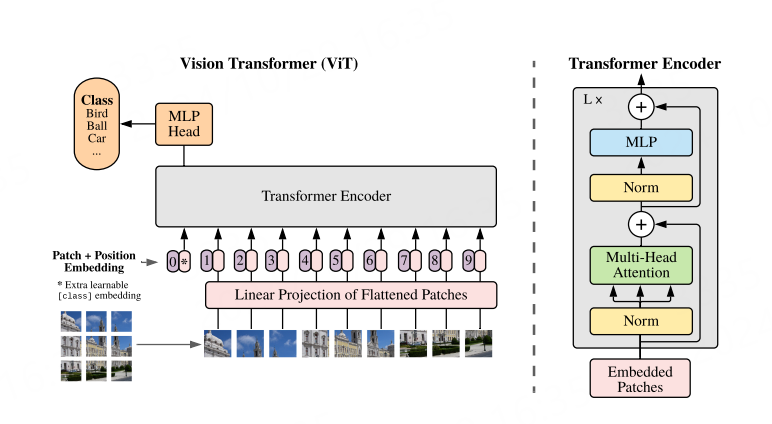
ViT论文: An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale。
本章将使用torchvision中ViT的实(自行测试也可以尝试使用 timm ), 简单测试ViT模型,并将其转换成rknn模型在鲁班猫上部署。
6.1. ViT测试¶
创建一个pytorch环境,详细安装命令参考下 Pytorch官网。
# 使用conda创建虚拟环境
conda create -n vit python=3.9
conda activate vit
# 根据自行的环境安装pytorch,下面是参考命令:
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
# 还有一些库等等
pip install numpy
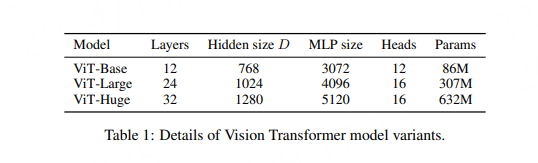
torchvision中ViT的实现源码参考下 这里, 源码中实现了不同大小的模型,本章测试选择的是vit_b_16模型,也就是ViT_Base/16模型,输入图像是224*224,划分16*16 patches。 使用默认的权重 ViT_B_16_Weights.IMAGENET1K_V1 , 该权重是使用 DeiT 训练方法的修改版本从头开始训练。
编程一个简单python程序,对单个图像的简单推理,显示具有最高的置信度的5个类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | # 使用的是torchvision.transforms,需要更快转换速度可以更换成torchvision.transforms.v2
pretreatment = transforms.Compose([
transforms.Resize(256, interpolation=InterpolationMode.BILINEAR, antialias=True),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# labels
with open(CLASS_LABEL_PATH, 'r') as f:
labels = [l.rstrip() for l in f]
# Model // torchvision.models or torch.hub.load
# model = vit_b_16(weights=ViT_B_16_Weights.DEFAULT)
model=vit_b_16(weights=ViT_B_16_Weights.IMAGENET1K_V1)
model.eval()
# pre
raw_image = Image.open(image).convert("RGB")
image = pretreatment(raw_image).unsqueeze(0)
logits = model(image)
probs = F.softmax(logits, dim=1)
# print the top-5 inferences class // topk
scores = np.squeeze(probs.detach().numpy())
a = np.argsort(scores)[::-1]
print('-----TOP 5-----')
for i in a[0:5]:
print('[%d] score=%.6f class="%s"' % (i, scores[i], labels[i]))
print('done')
|
在环境中运行python测试程序:
(vit) llh@llh:/xxx/ViT$ python test_vit_image.py
-----TOP 5-----
[812] score=0.887221 class="n04266014 space shuttle"
[977] score=0.000342 class="n09421951 sandbar, sand bar"
[833] score=0.000304 class="n04347754 submarine, pigboat, sub, U-boat"
[512] score=0.000269 class="n03109150 corkscrew, bottle screw"
[525] score=0.000247 class="n03160309 dam, dike, dyke"
done
6.2. 模型转换¶
在鲁班猫NPU上部署,需要将模型转换成rknn模型。 我们将需要先将ViT_B_16模型转成onnx,然后使用toolkit2工具(toolkit2安装请参考前面章节)将onnx模型转换成rknn模型。
6.2.1. onnx模型¶
编写程序导出onnx模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import torch
from torchvision.models import vit_b_16
from torchvision.models import ViT_B_16_Weights
# model = vit_b_16(weights=ViT_B_16_Weights.DEFAULT)
model = vit_b_16(weights=ViT_B_16_Weights.IMAGENET1K_V1)
model.eval()
output_name = 'vit_b_16.onnx'
torch.onnx.export(
model,
torch.rand(1, 3, 224, 224),
output_name,
opset_version=14,
)
print("generated onnx model named {}".format(output_name))
|
需要注意设置的opset的版本,低版本可能有些算子不支持导出onnx。执行程序,导出vit_b_16的onnx模型:
# 首次将自动下载权重vit_b_16-c867db91.pth,也可以自行手动下载,然后程序中指定
(vit) llh@llh:/xxx/ViT$ python vit_export_onnx.py
# 省略....
Downloading: "https://download.pytorch.org/models/vit_b_16-c867db91.pth" to /xxx/.cache/torch/hub/checkpoints/vit_b_16-c867db91.pth
100%|█████████████████████████████████████████████████████████████████████████████████████| 330M/330M [00:07<00:00, 43.9MB/s]
generated onnx model named vit_b_16.onnx
6.2.2. 转成rknn模型¶
简单编写一个转换程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | # 有省略.......
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[[123.675, 116.28, 103.53]], std_values=[
[58.395, 58.395, 58.395]], target_platform=platform)
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(output_path)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Release
rknn.release()
|
执行程序导出rknn模型,教程测试导出INT8量化的模型,也可以不量化默认fp16。
# 进入toolkit2.2环境,教程测试的是lubancat-4,所以设置平台目标rk3588,lubancat-0/1/2设置目标rk3566/rk3568,lubancat-5设置目标rk3588
# Usage: python3 onnx2rknn.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
(toolkit2.2) llh@llh:/mnt/e/work/AI_project/ViT/rknn$ python onnx2rknn.py ../vit_b_16.onnx rk3588 i8
I rknn-toolkit2 version: 2.2.0
--> Config model
done
--> Loading model
I Loading : 100%|███████████████████████████████████████████████| 169/169 [00:00<00:00, 4538.62it/s]
done
--> Building model
I OpFusing 0: 100%|███████████████████████████████████████████████| 100/100 [00:01<00:00, 79.69it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 35.38it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:04<00:00, 20.64it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:04<00:00, 20.54it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:04<00:00, 20.28it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:04<00:00, 20.04it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:05<00:00, 19.91it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:06<00:00, 16.32it/s]
I GraphPreparing : 100%|████████████████████████████████████████| 202/202 [00:00<00:00, 7073.91it/s]
I Quantizating : 100%|████████████████████████████████████████████| 202/202 [00:05<00:00, 38.15it/s]
W build: The default input dtype of 'x' is changed from 'float32' to 'int8' in rknn model for performance!
Please take care of this change when deploy rknn model with Runtime API!
W build: The default output dtype of '2303' is changed from 'float32' to 'int8' in rknn model for performance!
Please take care of this change when deploy rknn model with Runtime API!
I rknn building ...
I rknn buiding done.
done
--> Export rknn model
done
6.3. 部署测试¶
教程进行简单的部署,测试使用Toolkit Lite2, Toolkit Lite2的安装和使用参考 这里 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # 省略...............
rknn_lite = RKNNLite()
# Load RKNN model
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(rknn_model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
ori_img = cv2.imread('./space_shuttle_224.jpg')
img = cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB)
img = np.expand_dims(img, 0)
# Init runtime environment
print('--> Init runtime environment')
# Run on RK356x / RK3576 / RK3588 with Debian OS, do not need specify target.
if host_name in ['RK3576', 'RK3588']:
# For RK3576 / RK3588, specify which NPU core the model runs on through the core_mask parameter.
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)
else:
ret = rknn_lite.init_runtime()
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn_lite.inference(inputs=[img])
# Show the classification results
show_top5(outputs)
print('done')
rknn_lite.release()
|
修改程序中rknn模型路径和图像路径,然后执行程序(注意检测的图像需要244*244):
# 安装opencv等等相关库
# 测试例程使用的是lubancat-4板卡,系统是ubuntu20.04
cat@lubancat:~/ViT$ python3 rknn_Inference.py
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [15:53:54.437] RKNN Runtime Information, librknnrt version: 2.2.0 (c195366594@2024-09-14T12:18:56)
I RKNN: [15:53:54.437] RKNN Driver Information, version: 0.9.2
I RKNN: [15:53:54.438] RKNN Model Information, version: 6, toolkit version: 2.2.0(
compiler version: 2.2.0 (c195366594@2024-09-14T12:24:14)), target: RKNPU v2, target platform: rk3588,
framework name: ONNX, framework layout: NCHW, model inference type: static_shape
done
--> Running model
-----TOP 5-----
[812] score:0.848256 class:"space shuttle"
[525] score:0.000451 class:"dam, dike, dyke"
[493] score:0.000430 class:"chiffonier, commode"
[833] score:0.000386 class:"submarine, pigboat, sub, U-boat"
[628] score:0.000371 class:"liner, ocean liner"
done