
10. YOLOv5Face(人脸检测)¶
YOLOv5Face 是以YOLOv5为基础来进行改进和再设计以适应人脸检测的模型, 考虑了大人脸、小人脸、Landmark监督等不同的复杂性和应用。
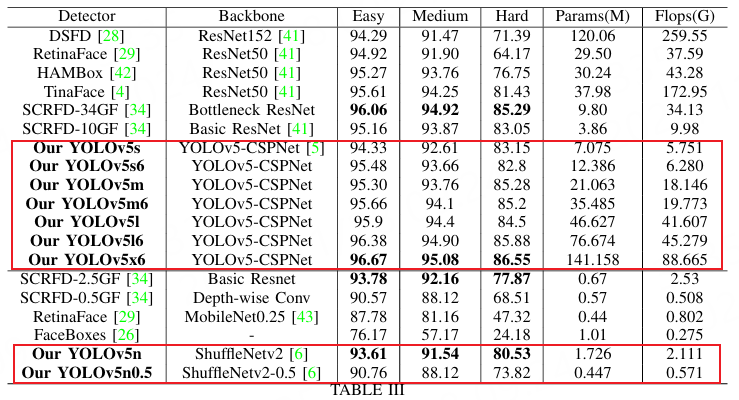
如上图所示,YOLOv5Face设计了一系列不同规模的模型,从大型模型到中型模型,再到超小模型,以满足不同应用中的需要。 除了在YOLOv5中使用的Backbone外,还实现了一个基于ShuffleNetV2的Backbone,它为移动设备提供了最先进的性能和快速的速度;
项目地址: https://github.com/deepcam-cn/yolov5-face (最新的有 yolov7-face 和 yolov8-face )
论文地址: YOLO5Face: Why Reinventing a Face Detector
本章将简单测试yolov5-face模型,然后编写模型程序导出onnx模型,然后使用toolkit2的接口将onnx模型转换成rknn模型, 最后使用RKNPU2接口编写简单测试例程,在鲁班猫板卡上部署yolov5s-face模型。
10.1. yolov5-face简单测试¶
在PC上使用anaconda创建一个虚拟环境(或者在一个安装pytorch的环境中),使用下面命令安装Pytorch相关软件:
# 安装anaconda参考前面环境搭建教程,然后使用conda命令创建环境
conda create -n yolov5face python=3.10
conda activate yolov5face
# 根据自行的环境安装pytorch,详细命令参考https://pytorch.org/get-started/locally/,下面是参考命令:
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
#pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
获取权重文件:
# 从yolov5-face源码仓库README.md中提供的链接,获取yolov5n-face.pt或者yolov5s-face.pt权重文件
yolov5n-face.pt 网盘链接: https://pan.baidu.com/s/1xsYns6cyB84aPDgXB7sNDQ 提取码: lw9j
yolov5s-face.pt 网盘链接: https://pan.baidu.com/s/1fyzLxZYx7Ja1_PCIWRhxbw 提取码: eq0q
# 获取一张测试图像
wget https://github.com/deepcam-cn/yolov5-face/blob/master/torch2trt/sample.jpg
使用yolov5-face提供的工程文件detect_face.py,进行人脸检测模型推理测试:
# 拉取yolov5-face源码
git clone https://github.com/deepcam-cn/yolov5-face.git
cd yolov5-face/
# 测试,--weights指定权重路径,--source指定测试图像路径或者目录等等
(yolov5face) llh@YH-LONG:/xxx/yolov5-face$ python detect_face.py --weights ../yolov5n-face.pt \
--img-size 640 --source ./torch2trt/sample.jpg --save-img
# 省略.............
loading images ./torch2trt/sample.jpg
image 1/1 xxx/yolov5-face/torch2trt/sample.jpg: 8 faces
测试过程中如果出现No module named ‘xxx’,请使用pip安装相关软件库,在run目录下保存了测试结果:

10.2. 模型转换¶
10.2.1. 导出onnx模型¶
参考yolov5-face源码中的export.py, 编写适用于鲁班猫rk板卡上部署的onnx模型, 主要是将一些处理放到部署例程中,以便部署测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | # 部分省略...............
def export_forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
z.append(x[i])
return z
def run(weights='yolov5s-face.pt', img_size=(640, 640)):
t = time.time()
model = attempt_load(weights, map_location=torch.device('cpu')) # load FP32 model
model.eval()
# model
model.model[-1].forward = types.MethodType(export_forward, model.model[-1])
print(f'starting export {weights} to onnx...')
save_path = weights.replace(".pt", ".onnx")
model.fuse() # only for ONNX
output_names = ['output0']
img = torch.zeros(1, 3, img_size[0], img_size[1])
torch.onnx.export(
model, # --dynamic only compatible with cpu
img,
save_path,
verbose=False,
opset_version=12,
do_constant_folding=True,
input_names=['images'],
output_names=output_names)
# Checks
onnx_model = onnx.load(save_path) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
print('ONNX export success, saved as %s' % save_path)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--img_size', nargs='+', type=int, default=[640, 640])
opt = parser.parse_args()
return opt
if __name__ == '__main__':
args = parse_opt()
args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
run(args.weights, args.img_size)
|
将编写的程序export_onnx.py放到前面拉取的yolov5-face源码目录下,然后执行命令:
# --weights指定权重路径,--img_size指定尺寸
(yolov5face) llh@YH-LONG:/xxx/yolov5-face$ python yolov5face_export.py --weights ../yolov5n-face.pt --img 640
Fusing layers...
# 省略...............................
ONNX export success, saved as ../yolov5n-face.onnx
Export complete (0.76s). Visualize with https://github.com/lutzroeder/netron.
使用 netron 工具查看模型输入输出:
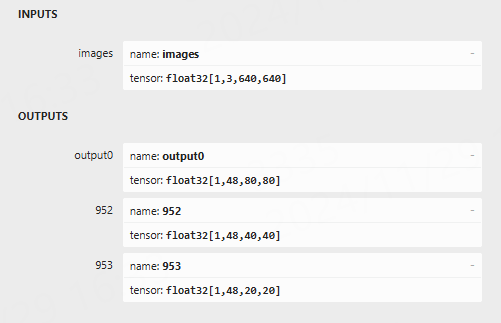
需要注意:如果自行修改yolov5-face模型输出shape,后面部署例程也要一并修改。
另外,教程部署测试是yolov5n-face/yolov5s-face模型,输出是没有P6(关于P6输出请参考yolov5-face 论文), 如果测试使用yolov5n6-face/yolov5s6-face带有P6的模型,也要修改后面的部署例程。
10.2.2. 转换成rknn模型¶
适用toolkit2工具,简单编写程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(output_path)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Release
rknn.release()
|
使用配套例程的onnx2rknn.py将前面导出的yolov5n-face.onnx模型转换成rknn模型(教程测试lubancat-4板卡):
# Usage: python3 onnx2rknn.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)
# 请根据实际测试板卡设置platform参数,教程测试以lubancat4为例,设置参数为rk3588,设置rknn模型保存路径为当前目录下yolov5n_face_i8.rknn
(toolkit2_2.3) llh@YH-LONG:/xxx/$ python onnx2rknn.py ../yolov5n-face.onnx rk3588 i8 yolov5n_face_i8.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|█████████████████████████████████████████████| 170/170 [00:00<00:00, 105916.77it/s]
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 955.45it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 804.37it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 269.44it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 231.96it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 221.65it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 137.20it/s]
# 省略...............................................
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
最后导出rknn模型在指定的当前目录下,名称为yolov5n_face_i8.rknn。
10.3. 模型部署¶
在鲁班猫板卡上直接拉取配套例程,将前面转换出的yolov5n_face_i8.rknn模型 复制xxxx/example/yolov5face/model目录下,然后直接编译:
# 安装相关软件等等
sudo apt update
sudo apt install libopencv-dev git cmake make gcc g++ libsndfile1-dev
cat@lubancat:~/xxx$ git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
cat@lubancat:~/xxx$ cd lubancat_ai_manual_code/example/yolov5face/cpp
# 编译例程,先将前面转换出的yolov5n_face_i8.rknn模型复制到model目录下
# 教程测试lubancat-4板卡,设置-t参数为rk3588,如果是lubancat-0/1/2,设置rk356x,如果是lubancat-3,设置rk3576
cat@lubancat:~/xxx/yolov5face/cpp$ ./build-linux.sh -t rk3588
./build-linux.sh -t rk3588
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/xxx/examples/yolov5face/cpp/install/rk3588_linux
BUILD_DIR=/xxx/examples/yolov5face/cpp/build/build_rk3588_linux
ENABLE_DMA32=TRUE
DISABLE_RGA=OFF
BUILD_TYPE=Release
ENABLE_ASAN=OFF
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
# 省略......................
[ 72%] Built target imageutils
[100%] Built target rknn_yolov5face_demo
[ 18%] Built target fileutils
[ 36%] Built target imageutils
[ 54%] Built target imagedrawing
[ 81%] Built target rknn_yolov5face_demo
[100%] Built target audioutils
Install the project...
# 省略......................
如果板卡系统是Debian10,会出现错误提示cmake版本低于要求版本,该例程可以手动改下CMakeLists.txt文件中的 cmake_minimum_required(VERSION 3.15) 来降低版本要求,
或者手动拉取下最新cmake源码编译安装:
git clone https://github.com/Kitware/CMake.git
cd CMake
./bootstrap
make && sudo make install
编译完成后,切换到install/rk3588_linux目录,然后简单测试:
# 测试例程
cat@lubancat:~/xxx/install/rk3588_linux$ ./rknn_yolov5face_demo ./model/yolov5n_face_i8.rknn ./model/sample.jpg
model input num: 1, output num: 3
input tensors:
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
output tensors:
index=0, name=output0, n_dims=4, dims=[1, 48, 80, 80], n_elems=307200, size=307200, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=67, scale=0.102861
index=1, name=952, n_dims=4, dims=[1, 48, 40, 40], n_elems=76800, size=76800, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=72, scale=0.077146
index=2, name=953, n_dims=4, dims=[1, 48, 20, 20], n_elems=19200, size=19200, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=71, scale=0.073914
model is NHWC input fmt
model input height=640, width=640, channel=3
origin size=1024x768 crop size=1024x768
input image: 1024 x 768, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
-- read_image use: 5.037000 ms
scale=0.625000 dst_box=(0 80 639 559) allow_slight_change=1 _left_offset=0 _top_offset=80 padding_w=0 padding_h=160
rga_api version 1.10.1_[0]
fill dst image (x y w h)=(0 0 640 640) with color=0x72727272
rknn_run
-- inference and postprocess yolov5face model use: 30.084000 ms
face @ (316 99 417 232) 0.890
face @ (704 166 806 302) 0.883
face @ (358 262 499 435) 0.882
face @ (564 310 708 478) 0.881
face @ (153 321 308 515) 0.874
face @ (504 115 627 272) 0.867
face @ (156 129 283 284) 0.866
face @ (830 307 960 452) 0.850
write_image path: result.png width=1024 height=768 channel=3 data=0x558894fd70
测试结果保存在读取目录下:

以上是在鲁班猫板卡上简单部署测试YOLOv5-face人脸检测模型,仅供参考学习,可以自行去优化。