
5. MobileNetV2¶
MobileNet ,它是谷歌研究人员于2017年开发的一种CNN架构,用于将计算机视觉有效地融入手机和 机器人等小型便携式设备中,而不会显著降低准确性。后续进一步为了解决实际应用中的一些问题,推出了v2,v3版本。
MobileNet 提出了一种深度可分离卷积(Depthwise Separable Convolutions), 该卷积不同于标准卷积,可以大幅度减小模型规模的同时保证模型性能下降很小。
深度可分离卷积分为两个操作:深度卷积(DW)和逐点卷积(PW)。
深度卷积(DW)和标准卷积的不同之处在于,对于标准卷积,其卷积核是应用于所有的输入通道,而DW卷积针对每个输入通道采用不同的卷积核,也就是说,一个卷积核对应一个输入通道。
逐点卷积(PW)实际上就是普通的卷积,只不过其采用1x1的卷积核。
MobileNet 设计了两个控制网络大小全局超参数(宽度乘系数和分辨率乘系数), 通过这两个超参数来进行速度和准确率的权衡,使用者可以根据设备的限制调整网络。
MobileNetV2 在MobileNet的基础上,提出了线性Bottlenecks(Linear Bottlenecks)和倒残差结构(Inverted residual)。 其模型结构如下:
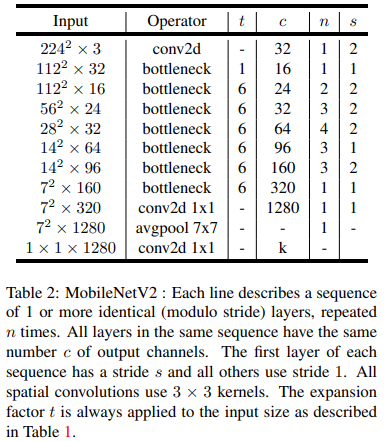
MobileNetV2网络构建,我们可以参考下PyTorch中torchvision的 实现 , TensorFlow的 实现 或者 paddlepaddle的 实现 。
本章将使用PyTorch深度学习框架,简单测试MobileNetv2,完成一个花卉分类任务,并在鲁班猫上部署测试该模型。
提示
测试环境:鲁班猫板卡使用Debian10/11,PC是ubuntu20.04系统, PyTorch版本是2.1.0,torchvision版本是0.16.0,rknn-Toolkit2版本1.5.0。
5.1. MobileNetv2¶
MobileNetv2测试使用花卉数据集,可以从下面网址下载(或者从网盘获取):
wget https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
该数据集总共有包括3700张图像,包括五种类别的花卉,分别是daisy、dandelion、roses、sunflowers、tulips。
5.1.1. 自定义数据集¶
下载的花卉数据集,同一类别的图片放在同一个目录下,而且目录的名称就是其类别。 我们可以直接使用torchvision提供的datasets.ImageFolder加载数据。
# 加载数据
flower_dataset = torchvision.datasets.ImageFolder(root="path/flower_photos",
transform=data_transform)
也可以自定义数据集的加载,通过torch.utils.data中的Dataset和DataLoader, 下面将参考torchvision.datasets.ImageFolder的实现,自定义一个数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | class FlowerData(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
# 类别
classes = sorted(entry.name for entry in os.scandir(self.root_dir) if entry.is_dir())
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
self.classes = classes
self.class_to_idx = class_to_idx
self.images = self.get_images(self.root_dir, self.class_to_idx)
def __len__(self):
return len(self.images)
def __getitem__(self,index):
path, target = self.images[index]
with open(path, "rb") as f:
img = Image.open(f)
image = img.convert("RGB")
if self.transform:
image = self.transform(image) #对数据进行变换
return image,target
# 读取图像
def get_images(self, directory, class_to_idx):
images = []
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
path = os.path.join(root, fname)
item = path, class_index
images.append(item)
return images
|
将自定义一个FlowerData类继承Dataset,我们必须实现下面三个函数:
def __init__ 初始化;
def __getitem__ 获取数据,根据样本索引返回数据,可以设置数据转换等;
def __len__ 返回数据集的长度,最终训练时用到的数据集的样本个数。
之后我们实例化自定义的数据集,通过torch.utils.data.DataLoader加载数据集,并进行数据增强和划分等操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | data_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# 初始化自定义FlowerData类,设置数据集所在路径以及变换
flower_data = FlowerData('../flower_photos',transform=data_transform)
print("Dataset class: {}".format(flower_data.class_to_idx))
# 数据集随机划分训练集(80%)和验证集(20%)
train_size = int(len(flower_data) * 0.8)
validate_size = len(flower_data) - train_size
train_dataset, validate_dataset = torch.utils.data.random_split(flower_data, [train_size, validate_size])
print("using {} images for training, {} images for validation.".format(len(train_dataset),len(validate_dataset)))
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process \n'.format(nw))
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw)
validate_loader = DataLoader(validate_dataset, batch_size=1, shuffle=True, num_workers=nw)
|
我们通过torch.utils.data.random_split将数据划分为训练集(80%)和验证集(20%), 然后使用DataLoader加载数据集。
5.1.2. MobileNetv2网络¶
MobileNetv2网络结构的说明和解释请参考 论文 和网上相关资料。
MobileNetv2网络实现可以直接使用torchvision提供的models.MobileNetV2,也可以自行构建, 接下来将参考 torchvision.models.MobileNetV2 的实现,来构建下MobileNetv2网络。
先将卷积与激活封装在一起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #定义卷积、批量归一化和激活函数,可以应用于普通卷积和dw卷积
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(
in_channel,
out_channel,
kernel_size,
stride,
padding,
groups=groups,
bias=False
),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
|
在上面的卷积中,如果groups参数为1,则是普通卷积,若groups与输入channel一致, 则是一个输入channel只会与单独的kerner进行卷积,这样就是分组卷积。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # 定义倒残差结构
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
# 通过1×1卷积对通道进行扩张。
hidden_channel = in_channel * expand_ratio
# 当步长等于1,且输入通道等于输出通道时,使用捷径分支
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
# 这里判断是因为第一个bottleneck的t为1,也就是并没有使用1×1的卷积进行升维
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# pw-linear 1x1
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
# 最后一个1×1卷积使用的是线性激活函数,直接连接,所以省略
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
|
MobileNetv2网络:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | # 定义MobileNet-v2网络结构
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
# 倒残差结构参数设置
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# 第一个卷积层(非倒残差结构)
features.append(ConvBNReLU(3, input_channel, stride=2))
# 倒残差结构块
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
# 只有第一次时步长为s,后面重复步长都为1
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# 1x1 conv after bottleneck
features.append(ConvBNReLU(input_channel, last_channel, 1))
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
|
5.1.3. 模型训练和验证¶
模型初始化,使用pytorch提供的MobileNetv2预训练权重(基于ImageNet-1K数据集),然后冻结特征提取的参数,只训练部分网络层,也就是 迁移学习 。 可以利用前人花大量时间训练好的参数, 能帮助我们在模型的训练上节省大把的时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | # 如果支持GPU,则使用默认GPU训练否则cpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 超参数
batch_size = 32
epochs = 10
learning_rate = 0.0001
# 加载数据集等等
# .........省略........具体参考例程
# 实例化模型,设置类别个数num_classes
net = MobileNetV2(num_classes=5).to(device)
# 使用pytorch提供的预训练权重 https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
model_weight_path = "./mobilenet_v2-b0353104.pth"
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path, map_location=device)
# 删除参数 (如果修改了模型结构,可以直接剔除预训练权重中不属于state_dict的参数,然后更新state_dict)
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
net.load_state_dict(pre_dict, strict=False)
# 通过requires_grad == False的方式来冻结特征提取层权重,仅训练后面的池化和全连接层
for param in net.features.parameters():
param.requires_grad = False
# 使用交叉熵损失函数
loss_function = nn.CrossEntropyLoss()
# 使用adam优化器, 仅仅对最后池化和classifier层进行优化
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=learning_rate)
# 输出网络结构
#print(summary(net, (3, 224, 224)))
# 训练和验证模型
fit(epochs, net, loss_function, optimizer, train_loader, validate_loader, device)
|
如果使用torchvision中的MobileNetV2,只需要在模型训练文件导入MobileNetV2,不使用自定义的MobileNetV2。
# 添加下面
from torchvision.models import MobileNetV2
# 注释掉自定义的MobileNetV2
# from model import MobileNetV2
模型训练和验证,torchvision官方提供了相关训练脚本,我们也可以自行实现下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | def fit(epochs, model, loss_function, optimizer, train_loader, validate_loader, device):
t0 = time.time()
best_acc = 0.0
save_path = './MobileNetV2.pth'
train_steps = len(train_loader)
model.to(device)
for epoch in range(epochs):
# 训练
model.train()
running_loss = 0.0
train_acc = 0.0
train_bar = tqdm(train_loader, total=train_steps) # 进度条
for step, (images, labels) in enumerate(train_bar):
optimizer.zero_grad() # grad zero
logits = model(images.to(device)) # Forward
loss = loss_function(logits, labels.to(device)) # loss
loss.backward() # Backward
optimizer.step() # optimizer.step
_, predict = torch.max(logits, 1)
train_acc += torch.sum(predict == labels.to(device))
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)
train_accurate = train_acc / len(train_loader.dataset)
# 验证
model.eval()
val_acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, total=len(validate_loader)) # 进度条
for val_data in val_bar:
val_images, val_labels = val_data
outputs = model(val_images.to(device))
_, val_predict = torch.max(outputs, 1)
val_acc += torch.sum(val_predict == val_labels.to(device))
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs)
val_accurate = val_acc / len(validate_loader.dataset)
print('[epoch %d] train_loss: %.3f - train_accuracy: %.3f - val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, train_accurate, val_accurate))
# 保存精度最好的模型
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(model.state_dict(), save_path)
print("\n{} epochs completed in {:.0f}m {:.0f}s.".format(epochs,(time.time() - t0) // 60,
(time.time() - t0) % 60))
|
执行train.py,训练和验证模型,简单测试10 epochs :
(pytorch) llh@anhao:~$ python train.py
using cuda:0 device.
Dataset class: {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
using 2936 images for training, 734 images for validation.
Using 8 dataloader workers every process
train epoch[1/10] loss:1.037: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:08<00:00, 10.49it/s]
valid epoch[1/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.12it/s]
[epoch 1] train_loss: 1.358 - train_accuracy: 0.538 - val_accuracy: 0.755
train epoch[2/10] loss:0.697: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 16.88it/s]
valid epoch[2/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.39it/s]
[epoch 2] train_loss: 0.999 - train_accuracy: 0.780 - val_accuracy: 0.817
train epoch[3/10] loss:0.710: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 16.15it/s]
valid epoch[3/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.44it/s]
[epoch 3] train_loss: 0.820 - train_accuracy: 0.813 - val_accuracy: 0.826
train epoch[4/10] loss:0.898: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 16.98it/s]
valid epoch[4/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.05it/s]
[epoch 4] train_loss: 0.718 - train_accuracy: 0.819 - val_accuracy: 0.841
train epoch[5/10] loss:0.627: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 16.27it/s]
valid epoch[5/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.06it/s]
[epoch 5] train_loss: 0.658 - train_accuracy: 0.818 - val_accuracy: 0.842
train epoch[6/10] loss:0.490: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 15.82it/s]
valid epoch[6/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.20it/s]
[epoch 6] train_loss: 0.595 - train_accuracy: 0.839 - val_accuracy: 0.851
train epoch[7/10] loss:0.568: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 17.09it/s]
valid epoch[7/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 12.32it/s]
[epoch 7] train_loss: 0.561 - train_accuracy: 0.841 - val_accuracy: 0.851
train epoch[8/10] loss:0.549: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:06<00:00, 15.01it/s]
valid epoch[8/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 12.70it/s]
[epoch 8] train_loss: 0.547 - train_accuracy: 0.836 - val_accuracy: 0.862
train epoch[9/10] loss:0.705: 100%|███████████████████████████████████████████████████████████████████████████████████| 92/92 [00:06<00:00, 14.85it/s]
valid epoch[9/10]: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.01it/s]
[epoch 9] train_loss: 0.515 - train_accuracy: 0.856 - val_accuracy: 0.861
train epoch[10/10] loss:0.466: 100%|██████████████████████████████████████████████████████████████████████████████████| 92/92 [00:05<00:00, 15.98it/s]
valid epoch[10/10]: 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:01<00:00, 13.98it/s]
[epoch 10] train_loss: 0.498 - train_accuracy: 0.848 - val_accuracy: 0.879
10 epochs completed in 1m 19s.
训练会保存精度最高的MobileNetV2.pth模型权重文件,最后没有模型预测推理,后面使用Toolkit2在板卡上进行推理测试。
5.1.4. torchscript模型保存¶
在模型训练时保存了MobileNetV2.pth模型权重文件。后面我们想要在鲁班猫板卡上部署, 需要导出torchscript的模型,这里重新保存下模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import torch
import os
from model import MobileNetV2
if __name__ == '__main__':
# 模型初始化
model = MobileNetV2(num_classes=5)
# 加载权重
model.load_state_dict(torch.load("./MobileNetV2.pth"))
model.eval()
# 保存模型
trace_model = torch.jit.trace(model, torch.Tensor(1, 3, 224, 224))
trace_model.save('./MobileNetV2.pt')
|
5.2. 板端部署测试¶
5.2.1. 转换成rknn模型¶
我们使用 RKNN Toolkit2 工具,将导出的模型转换出rknn模型,并进行简单模型测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | if __name__ == '__main__':
model = './MobileNetV2.pt'
input_size_list = [[1, 3, 224, 224]]
# Create RKNN object
# rknn = RKNN(verbose=True)
rknn = RKNN()
# Pre-process config, 这里默认设置rk3588
print('--> Config model')
rknn.config(mean_values=[[128, 128, 128]], std_values=[[128, 128, 128]], target_platform='rk3588')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
# ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
ret = rknn.build(do_quantization=False)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn('./MobileNetV2.rknn')
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
rknn.release()
|
运行程序,导出rknn模型:
W __init__: rknn-toolkit2 version: 1.5.0+1fa95b5c
--> Config model
done
--> Loading model
PtParse: 100%|██████████████████████████████████████████████████| 937/937 [00:00<00:00, 2565.97it/s]
Loading : 100%|█████████████████████████████████████████████████| 332/332 [00:00<00:00, 1200.23it/s]
done
--> Building model
done
--> Export rknn model
done
对模型进行简单评估测试:
5.2.2. 使用Toolkit Lite2部署测试¶
教程进行简单的部署,测试使用Toolkit Lite2, Toolkit Lite2的安装和使用参考 这里 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | if __name__ == '__main__':
rknn_lite = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(RK3588_RKNN_MODEL)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
ori_img = cv2.imread('./tulips.jpg')
img = cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224,224))
# init runtime environment
print('--> Init runtime environment')
# run on RK356x/RK3588 with Debian OS, do not need specify target.
#ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)
ret = rknn_lite.init_runtime()
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn_lite.inference(inputs=[img])
print(outputs[0][0])
show_outputs(softmax(np.array(outputs[0][0])))
print('done')
rknn_lite.release()
|
简单测试(lubancat-4):
cat@lubancat:~$ python3 test.py
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [13:35:33.654] RKNN Runtime Information: librknnrt version: 1.5.0 (e6fe0c678@2023-05-25T08:09:20)
I RKNN: [13:35:33.654] RKNN Driver Information: version: 0.8.8
I RKNN: [13:35:33.655] RKNN Model Information: version: 4, toolkit version: 1.5.0+1fa95b5c(compiler version: 1.5.0
(e6fe0c678@2023-05-25T16:15:03)), target: RKNPU v2, target platform: rk3588, framework name: PyTorch,
framework layout: NCHW, model inference type: static_shape
done
--> Running model
[-2.6914062 -3.6875 -1.65625 -1.5166016 1.9921875]
Class Prob
tulips: 93.6%
sunflowers: 2.8%
roses: 2.44%
daisy: 0.865%
dandelion: 0.32%
done