
16. CLIP¶
CLIP (Contrastive Language-Image Pre-Training) 模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。
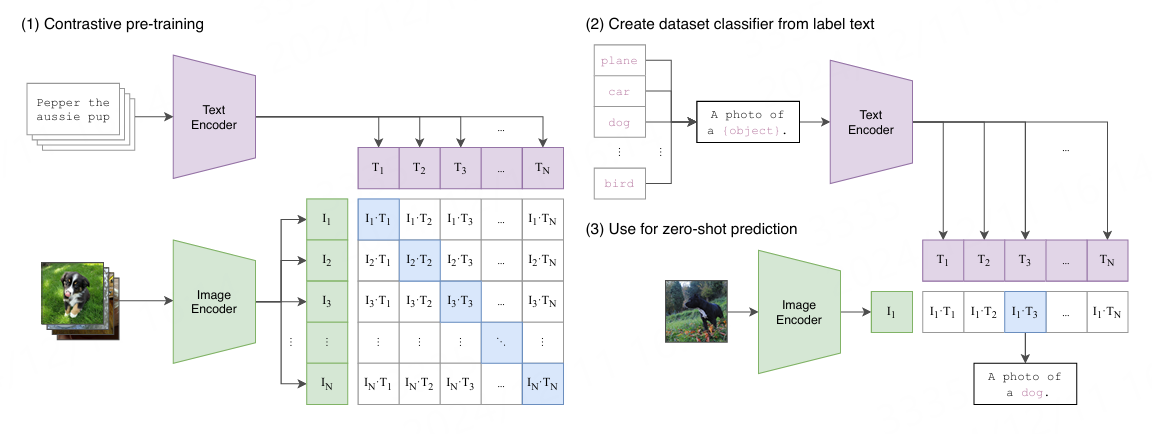
CLIP的主要结构是一个文本编码器Text Encoder和一个图像编码器Image Encoder, 然后计算文本向量和图像向量的相似度来预测是否匹配。
CLIP用文本作为监督信号来训练可迁移的视觉模型, 使得最终模型的zero-shot效果堪比ResNet50,泛化性非常好。CLIP模型在多个领域表现出色:
zero-shot图像分类,即直接推理,用见过的图片特征去判断没见过的图片的类别;
zero-shot目标检测,即检测训练数据集没有包含的类别;
StyleCLIP,可以通过文字的改变引导图像的生成;
CLIP视频检索,可以通过输入文本直接找到视频中出现的对应物体;
等等….
本章将在鲁班猫rk系列板卡上简单测试 CLIP 、 Chinese-CLIP 和 MobileCLIP 模型, 测试中使用的文件都在配套例程。
16.1. CLIP推理¶
教程测试CLIP模型是使用 Huggingface Transformers 提供的 clip-vit-base-patch32 。
在个人PC上,先使用conda创建虚拟环境,安装相关pytorch等等库:
# 使用conda创建虚拟环境
conda create -n clip python=3.9
conda activate clip
# 根据自行的环境安装pytorch,详细命令参考https://pytorch.org/get-started/locally/,下面是参考命令:
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
# 配置pip源(可选)
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装Huggingface Transformers
pip install transformers
参考Huggingface模型示例简单测试模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # 省略.............
from PIL import Image
import requests
from transformers import AutoProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(
text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True
)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(probs)
|
(clip) llh@llh:/xxx/clip$ python test_clip.py
config.json: 100%|█████████████████████████████████████████████████████████████████████| 4.19k/4.19k [00:00<00:00, 728kB/s]
pytorch_model.bin: 100%|████████████████████████████████████████████████████████████| 605M/605M [00:16<00:00, 36.4MB/s]
preprocessor_config.json: 100%|██████████████████████████████████████████████████████████████████| 316/316 [00:00<00:00, 62.5kB/s]
tokenizer_config.json: 100%|██████████████████████████████████████████████████████████████████████| 592/592 [00:00<00:00, 757kB/s]
vocab.json: 100%|█████████████████████████████████████████████████████████████████████████████| 862k/862k [00:00<00:00, 1.42MB/s]
merges.txt: 100%|██████████████████████████████████████████████████████████████████████| 525k/525k [00:00<00:00, 12.4MB/s]
tokenizer.json: 100%|████████████████████████████████████████████████████████████████████| 2.22M/2.22M [00:00<00:00, 2.26MB/s]
special_tokens_map.json: 100%|██████████████████████████████████████████████| 389/389 [00:00<00:00, 501kB/s]
tensor([[0.9949, 0.0051]], grad_fn=<SoftmaxBackward0>)
16.2. CLIP模型部署¶
在鲁班猫RK系列板卡上部署clip模型,需要先使用Huggingface的工具 optimum 导出onnx模型,然后使用 使用toolkit2工具转换成rknn模型。
16.2.1. 转换成onnx模型¶
测试 clip-vit-base-patch32 模型转换成onnx。
# 安装optimum exporters依赖模块
pip install optimum[exporters]
# 导出onnx模型,将会自动下载的openai/clip-vit-base-patch32 ,最后指定转换后的模型保存在clip-vit-base-patch32-onnx目录下
(clip) llh@llh:/xxx/clip$ optimum-cli export onnx --model openai/clip-vit-base-patch32 --opset 18 ./clip-vit-base-patch32-onnx
导出的onnx模型保存在指定的目录clip-vit-base-patch32-onnx下,名称为model.onnx。
然后需要将模型截取出文本侧和图像侧模型,参考 rknn_model_zoo 中clip示例的truncated_onnx.py文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import onnx
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Export clip onnx model', add_help=True)
parser.add_argument('--model', type=str, required=True,
help='onnx model path')
args = parser.parse_args()
output_path = './clip_text.onnx'
input_names = ['input_ids', 'attention_mask']
output_names = ['text_embeds']
onnx.utils.extract_model(args.model, output_path, input_names, output_names)
output_path = './clip_images.onnx'
input_names = ['pixel_values']
output_names = ['image_embeds']
onnx.utils.extract_model(args.model, output_path, input_names, output_names)
|
# 执行程序
cd clip-vit-base-patch32-onnx
python ./truncated_onnx.py --model ./model.onnx
执行程序后,会在当前目录下生成clip_images.onnx和clip_text.onnx文件。
16.2.2. 转换成rknn模型¶
接着使用toolkit2工具,将前面的clip_images.onnx和clip_text.onnx模型文件转换成rknn模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # 省略.............
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(target_platform=platform)
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path,
inputs=['input_ids', 'attention_mask'],
input_size_list=[[TEXT_BATCH_SIZE, SEQUENCE_LEN], [TEXT_BATCH_SIZE, SEQUENCE_LEN]])
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# 省略.............
|
convert_text.py将文本侧模型转换成rknn,需要注意设置的inputs和input_size_list,文本侧模型设置batch固定大小为1,序列长度为20。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # 省略.............
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(target_platform=platform,
mean_values=[[0.48145466*255, 0.4578275*255, 0.40821073*255]],
std_values=[[0.26862954*255, 0.26130258*255, 0.27577711*255]])
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path,
inputs=['pixel_values'],
input_size_list=[[1, 3, IMAGE_SIZE[0], IMAGE_SIZE[1]]])
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# 省略.............
|
convert_images.py将图像侧模型转换成rknn,需要注意设置的inputs和input_size_list,图像侧模型设置batch固定大小为1,分辨率为224*224。
切换到toolkit2环境,然后执行程序:
# Usage: python3 convert_text.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
# 运行文本侧模型转换程序,测试lubancat-4/5指定平台rk3588,lubancat-3设置rk3576等等,指定最后导出的rknn模型路径等
(toolkit2_2.3) llh@llh:/xxx/clip$ python convert_text.py ./clip_text.onnx rk3588 fp ./clip_text.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
W load_onnx: If you don't need to crop the model, don't set 'inputs'/'input_size_list'/'outputs'!
I Loading : 100%|███████████████████████████████████████████████| 197/197 [00:00<00:00, 3138.90it/s]
done
--> Building model
# 省略............
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 393.32it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 133.26it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 61.58it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 59.97it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 57.92it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 57.49it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 56.40it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 53.64it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 52.98it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 47.30it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
# 运行图像侧模型转换程序,测试lubancat-4/5指定平台rk3588,lubancat-3设置rk3576等等,指定最后导出的rknn模型路径等
(toolkit2_2.3) llh@llh:/xxx/clip$ python convert_images.py ./clip_images.onnx rk3588 fp ./clip_images.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
W load_onnx: If you don't need to crop the model, don't set 'inputs'/'input_size_list'/'outputs'!
I Loading : 100%|███████████████████████████████████████████████| 200/200 [00:00<00:00, 2670.08it/s]
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 421.53it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 88.17it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 52.58it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 51.53it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 49.89it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 49.57it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 48.85it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 47.26it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 46.83it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 36.74it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
在当前目录下生成clip_images.rknn和clip_text.rknn模型文件。
16.2.3. 板卡上部署测试¶
获取测试例程:
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
板卡上直接编译例程(教程测试lubancat-4):
sudo apt update
sudo apt install libboost-all-dev
# 切换到例程目录
cd lubancat_ai_manual_code/example/clip
# 复制前面转换出的rknn模型到model目录下
# 编译例程
cat@lubancat:~/xxx/clip$ ./build-linux.sh -t rk3588
./build-linux.sh -t rk3588
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/home/cat/xxx/clip/cpp/install/rk3588_linux
BUILD_DIR=/home/cat/xxx/clip/cpp/build/build_rk3588_linux
DISABLE_RGA=OFF
BUILD_TYPE=Release
ENABLE_ASAN=OFF
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
-- The C compiler identification is GNU 10.2.1
-- The CXX compiler identification is GNU 10.2.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
# 省略..............
[ 95%] Built target clip_demo
[100%] Linking CXX executable cn_clip_demo
[100%] Built target cn_clip_demo
[ 8%] Built target imageutils
[ 17%] Built target fileutils
[ 56%] Built target cn_clip_demo
[ 82%] Built target clip_demo
[ 91%] Built target audioutils
[100%] Built target imagedrawing
# 省略..............
生成的可执行文件在install/rk3588_linux目录下,有两个可执行文件,一个是CLIP部署例程(clip_demo), 一个是后面Chinese-CLIP模型部署的例程(cn_clip_demo),这里测试CLIP模型例程。
./clip_demo <image_model_path> <image_path> <text_model_path> <text_path>
# 第一个参数指rknn图像侧模型,第二个参数是输入的图像,第三个参数是rknn文本侧模型,第四个参数是输入文本
cat@lubancat:~/xxx/install/rk3588_linux$ ./clip_demo ./model/clip_images.rknn ./model/dog_224x224.jpg ./model/clip_text.rknn ./model/text.txt
--> init clip image model
# 省略...........
num_lines=2
rga_api version 1.10.1_[0]
-- inference_clip_model use: 195.167999 ms
--> rknn clip demo result
images: ./model/dog_224x224.jpg
text : a photo of a dog
score : 0.989
程序指定标签文件(text.txt)用于构建每个类别的描述文本,测试例程中只有两个A photo of cat和A photo of dog,将这些文本送入Text Encoder得到对应的文本特征。
将要预测的图像(dog_224x224.jpg )送入Image Encoder得到图像特征,然后与前面的2个文本特征计算缩放的余弦相似,然后选择相似度最大的文本对应的类别作为图像分类预测结果。
上面测试可以看到图像分类输出结果“a photo of a dog ”和“0.989”,下面我们换一张有猫的图片,然后重新测试:
cat@lubancat:~/xxx/install/rk3588_linux$ ./clip_demo ./model/clip_images.rknn ./model/000000039769.jpg ./model/clip_text.rknn ./model/text.txt
--> init clip image model
# 省略.................
--> inference clip image model
--> rknn clip demo result
images: ./000000039769.jpg
text : a photo of a cat
score : 0.994
也可以自行往text.txt添加其他类别,格式是:a photo of a {label},然后测试。
16.3. Chinese-CLIP模型部署¶
Chinese-CLIP 是CLIP模型的中文版本, 针对中文领域数据以及在中文数据上实现效果做了优化。
Chinese-CLIP项目地址:https://github.com/OFA-Sys/Chinese-CLIP。
16.3.1. 转换出onnx模型¶
Chinese-CLIP 提供了API、训练代码和测试代码,部署代码等等, 参考工程目录deploy下的pytorch_to_onnx.py,将模型转换成onnx模型。
准备Chinese-CLIP环境:
# 进入前面创建的虚拟环境(安装了pytorch、onnx等等相关库)
conda activate clip
# 获取Chinese-CLIP工程文件
(clip) llh@llh:/xxx$ git clone https://github.com/OFA-Sys/Chinese-CLIP.git
# 切换到Chinese-CLIP工程目录
(clip) llh@llh:/xxx$ cd Chinese-CLIP
(clip) llh@llh:/xxx/Chinese-CLIP$
# 创建build文件,设置相关环境变量,安装相关库等等
(clip) llh@llh:/xxx/Chinese-CLIP$ mkdir build
(clip) llh@llh:/xxx/Chinese-CLIP$ pip install onnxmltools onnxconverter_common
(clip) llh@llh:/xxx/Chinese-CLIP$ export PYTHONPATH=${PYTHONPATH}:$(pwd)/cn_clip
# 也可以直接安装,然后使用接口
# pip install cn_clip
Chinese-CLIP目前开源5个不同规模,其模型信息和下载方式见 Chinese-CLIP README页面。
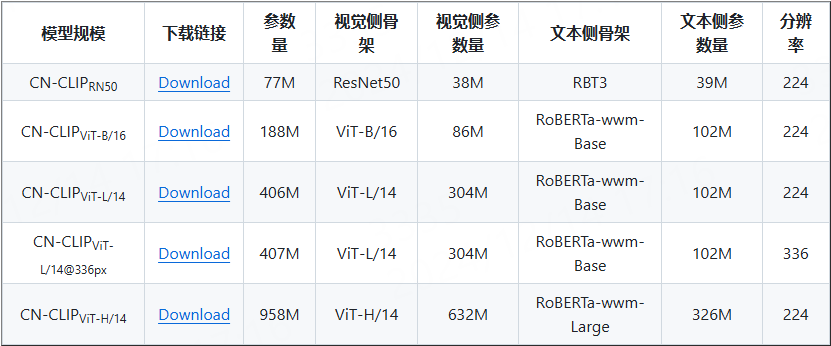
教程测试CN-CLIPViT-B/16模型,获取预训练模型后使用deploy/pytorch_to_onnx.py例程转换出onnx模型, deploy/pytorch_to_onnx.py文件的使用,详细说明请查看下工程文件 deployment.md。
# 获取预训练的ckpt文件
wget https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/checkpoints/clip_cn_vit-b-16.pt
# 然后修改deploy/pytorch_to_onnx.py中opset版本,改为14以上
opset_version=14,
# 修改deploy/pytorch_to_onnx.py导出的img和text的fp16onnx模型,不使用extra_file
# convert vision FP16 ONNX model based on the FP32 model
vision_fp16_onnx_path = f"{args.save_onnx_path}.img.fp16.onnx"
vision_fp32_onnx_model = load_model(vision_fp32_onnx_path)
vision_fp16_onnx_model = convert_float_to_float16(vision_fp32_onnx_model, keep_io_types=True, disable_shape_infer=True)
+ onnx.save(vision_fp16_onnx_model, f"{args.save_onnx_path}.img.fp16.onnx")
- # save_model(vision_fp16_onnx_model,
- # vision_fp16_onnx_path,
- # location="{}.extra_file".format(os.path.split(vision_fp16_onnx_path)[1]),
- # save_as_external_data=True,
- # all_tensors_to_one_file=True,
- # size_threshold=1024,
- # convert_attribute=True)
# 详细修改的deploy/pytorch_to_onnx.py请参考配套例程的pytorch_to_onnx.py
# 将配套例程的pytorch_to_onnx.py复制到Chinese-CLIP工程文件中
# 执行deploy/pytorch_to_onnx.py,其中--model-arch指定模型规模
# --pytorch-ckpt-path指定Pytorch模型ckpt路径
# 参数onvert-text和convert-vision指定是否转换文本侧和图像侧模型
# --context-length参数设置文本侧模型,文本序列长度,默认是52
(clip) llh@llh:/xxx/Chinese-CLIP$ python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch ViT-B-16 \
--pytorch-ckpt-path ../clip_cn_vit-b-16.pt \
--save-onnx-path ./build/vit-b-16 \
--convert-text --convert-vision \
--context-length 12
# 省略..................................................................................
Finished PyTorch to ONNX conversion...
>>> The text FP32 ONNX model is saved at ./build/vit-b-16.txt.fp32.onnx
>>> The text FP16 ONNX model is saved at ./build/vit-b-16.txt.fp16.onnx with extra file ./build/vit-b-16.txt.fp16.onnx.extra_file
>>> The vision FP32 ONNX model is saved at ./build/vit-b-16.img.fp32.onnx
>>> The vision FP16 ONNX model is saved at ./build/vit-b-16.img.fp16.onnx with extra file ./build/vit-b-16.img.fp16.onnx.extra_file
转换出的onnx模型保存在指定的路径build/目录下,将会生成多个onnx文件, 在后面部署阶段,我们将使用vit-b-16.txt.fp16.onnx和vit-b-16.img.fp16.onnx文件。
16.3.2. 导出rknn模型¶
接着使用toolkit2工具,将前面的vit-b-16.txt.fp16.onnx和vit-b-16.img.fp16.onnx模型文件转换成rknn模型, 参考前面CLIP的转换程序,并简单修改。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # 省略.............
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(target_platform=platform)
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# 省略.............
|
convert_cn_clip_text.py将vit-b-16.txt.fp16.onnx文本侧模型转换成rknn。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | # 省略.............
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()
# Create RKNN object
rknn = RKNN(verbose=False)
# Pre-process config
print('--> Config model')
rknn.config(target_platform=platform,
mean_values=[[0.48145466*255, 0.4578275*255, 0.40821073*255]],
std_values=[[0.26862954*255, 0.26130258*255, 0.27577711*255]])
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# 省略.............
|
convert_cn_clip_images.py将vit-b-16.img.fp16.onnx图像侧模型转换成rknn, 需要注意图像侧模型设置batch固定大小为1,分辨率为224*224。
# 切换到toolkit2环境,然后执行程序,转换模型
#
# Usage: python3 convert_cn_clip_text.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
# 运行文本侧模型转换程序,测试lubancat-4/5指定平台rk3588,lubancat-3设置rk3576等等,指定最后导出的rknn模型路径等
(toolkit2_2.3) llh@llh:/xxx/clip$ python convert_cn_clip_text.py ./vit-b-16.txt.fp16.onnx rk3588 fp ./vit-b-16.txt.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|███████████████████████████████████████████████| 198/198 [00:00<00:00, 4121.31it/s]
W load_onnx: Please note that some float16/float64 data types in the model have been modified to float32!
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 260.97it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 99.85it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 61.78it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 61.35it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 60.14it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 59.06it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 58.33it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 47.60it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
# 运行图像侧模型转换程序,测试lubancat-4/5指定平台rk3588,lubancat-3设置rk3576等等,指定最后导出的rknn模型路径等
(toolkit2_2.3) llh@llh:/xxx/clip$ python convert_cn_clip_images.py ./vit-b-16.img.fp16.onnx rk3588 fp ./vit-b-16.img.rknn
在toolkit2环境中执行程序,将在当前目录下生成vit-b-16.img.rknn和vit-b-16.txt.rknn模型文件。
16.3.3. 部署测试Chinese-CLIP模型¶
获取部署例程,Chinese-CLIP模型部署例程和前面部署CLIP例程在一个工程中。
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
板卡上直接编译例程(教程测试lubancat-4):
sudo apt update
sudo apt install libboost-all-dev
# 复制前面转换出的rknn模型到model目录下
# 切换到例程目录
cd lubancat_ai_manual_code/examples/clip/cpp
# 编译
cat@lubancat:~/xxx/clip$ ./build-linux.sh -t rk3588
生成的可执行文件在install/rk3588_linux目录下,执行程序cn_clip_demo:
./clip_demo <image_model_path> <image_path> <text_model_path> <text_path>
# 第一个参数指rknn图像侧模型,第二个参数是输入的图像,第三个参数是rknn文本侧模型,第四个参数是输入文本
cat@lubancat:~/xxx/install/rk3588_linux$ ./cn_clip_demo ./model/vit-b-16.img.rknn ./model/pokemon.jpg ./model/vit-b-16.txt.rknn ./model/cn_text.txt
--> init cn_clip image model
model input num: 1, output num: 1
input tensors:
index=0, name=image, n_dims=4, dims=[1, 224, 224, 3], n_elems=150528, size=301056, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=unnorm_image_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model is NHWC input fmt
input image height=224, input image width=224, input image channel=3
--> init cn_clip text model
model input num: 1, output num: 1
input tensors:
index=0, name=text, n_dims=2, dims=[1, 52], n_elems=52, size=416, fmt=UNDEFINED, type=INT64, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=unnorm_text_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model is UNDEFINED input fmt
input text batch size=1, input sequence length=52
origin size=224x224 crop size=224x224
input image: 224 x 224, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
--> inference cn_clip image model
rga_api version 1.10.1_[0]
rknn_run
--> inference cn_clip text model
--> rknn clip demo result
images: ./model/pokemon.jpg
text : 皮卡丘
score : 1.000
# 测试有小狗的照片
cat@lubancat:~/xxx/install/rk3588_linux$ ./cn_clip_demo ./model/vit-b-16.img.rknn ./model/dog_224x224.jpg ./model/vit-b-16.txt.rknn ./model/cn_text.txt
--> init cn_clip image model
model input num: 1, output num: 1
input tensors:
index=0, name=image, n_dims=4, dims=[1, 224, 224, 3], n_elems=150528, size=301056, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=unnorm_image_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model is NHWC input fmt
input image height=224, input image width=224, input image channel=3
--> init cn_clip text model
model input num: 1, output num: 1
input tensors:
index=0, name=text, n_dims=2, dims=[1, 52], n_elems=52, size=416, fmt=UNDEFINED, type=INT64, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=unnorm_text_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model is UNDEFINED input fmt
input text batch size=1, input sequence length=52
origin size=224x224 crop size=224x224
input image: 224 x 224, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
num_lines=6
--> inference cn_clip image model
rga_api version 1.10.1_[0]
--> inference cn_clip text model
--> rknn CN_CLIP demo result
images: ./model/dog_224x224.jpg
text : 狗狗
score : 1.000
以上就是在lubancat上简单部署Chinese-CLIP模型,详情请查看配套例程,可自行修改优化。
16.4. MobileCLIP¶
CLIP的对比预训练表现出了出色的零样本性能,并提高了在各种下游任务上的鲁棒性。 然而,这些模型利用基于Transformer的大型编码器,具有显著的内存和延迟开销,这给移动设备上的部署带来了挑战。
MobileCLIP 是一个针对运行时性能进行优化的新的高效图像文本模型系列,并提出一种新颖且高效的训练方法,即多模态强化训练, 在零样本分类和检索等任务上性能表现SOTA。
github:https://github.com/apple/ml-mobileclip
论文:https://arxiv.org/abs/2311.1704
16.4.1. MobileCLIP使用¶
安装MobileCLIP环境。
conda create -n clipenv python=3.10
conda activate clipenv
git clone https://github.com/apple/ml-mobileclip.git
cd ml-mobileclip
pip install -e .
获取预训练模型,教程测试mobileclip_s0.pt。
# 获取mobileclip_s0.pt
wget https://docs-assets.developer.apple.com/ml-research/datasets/mobileclip/mobileclip_s0.pt
# mobileclip_s1.pt
wget https://docs-assets.developer.apple.com/ml-research/datasets/mobileclip/mobileclip_s1.pt
参考 README.md ,简单测试MobileCLIP,需要根据实际路径修改预训练模型路径。
import torch
from PIL import Image
import mobileclip
model, _, preprocess = mobileclip.create_model_and_transforms('mobileclip_s0', pretrained='/path/to/mobileclip_s0.pt')
tokenizer = mobileclip.get_tokenizer('mobileclip_s0')
image = preprocess(Image.open("docs/fig_accuracy_latency.png").convert('RGB')).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
测试将使用ml-mobileclip/docs/fig_accuracy_latency.png图像,测试输出:
(clipenv) llh@llh:/xxx/ml-mobileclip$ python test.py
# 省略.........
with torch.no_grad(), torch.cuda.amp.autocast():
Label probs: tensor([[1.0000e+00, 1.5044e-06, 5.7435e-07]])
16.4.2. 模型转换¶
MobileCLIP转成onnx模型,将分成两部分TextEncoder和ImageEncoder导出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | model, _, preprocess = mobileclip.create_model_and_transforms('mobileclip_s0', pretrained='./mobileclip_s0.pt')
tokenizer = mobileclip.get_tokenizer('mobileclip_s0')
text_encoder = model.text_encoder
# text onnx
text_input = tokenizer("a photo of a cat", return_tensors="pt")
text_onnx_path = "text_encoder.onnx"
torch.onnx.export(text_encoder,
(text_input),
text_onnx_path,
input_names=['text'],
output_names=['text_features'],
export_params=True,
opset_version=13,
verbose=False)
# onnx Checks
#model_onnx = onnx.load(text_onnx_path) # load onnx model
#onnx.checker.check_model(model_onnx) # check onnx model
# Save the image_encoder model
image_encoder = model.image_encoder
# image onnx
image = preprocess(Image.open("docs/fig_accuracy_latency.png").convert('RGB')).unsqueeze(0)
image_onnx_path = "image_encoder.onnx"
torch.onnx.export(image_encoder,
(image),
image_onnx_path,
input_names=['image'],
output_names=['image_features'],
export_params=True,
opset_version=13,
verbose=False)
#model_onnx = onnx.load(image_onnx_path) # load onnx model
#onnx.checker.check_model(model_onnx) # check onnx model
|
(clipenv) llh@llh:/xxx/ml-mobileclip$ python export_onnx.py
导出onnx模型,会在当前目录下生成text_encoder.onnx和image_encoder.onnx。
使用toolkit2根据将onnx模型转成rknn模型,测试程序请参考配套例程。
# 导出text_encoder.rknn
(toolkit2.3) llh@llh:/xxx/ml-mobileclip$ python convert_text.py ./text_encoder.onnx rk3588 fp ../text_encoder.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|██████████████████████████████████████████████████| 71/71 [00:00<00:00, 829.01it/s]
done
--> Building model
W build: The dataset='datasets/subset.txt' is ignored because do_quantization = False!
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 484.17it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 296.55it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 160.64it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 156.91it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 151.67it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 150.63it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 148.24it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 146.25it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 144.67it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 118.27it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
# 导出text_encoder.rknn
(toolkit2.3) llh@llh:/xxx/ml-mobileclip$ python convert_image.py ./image_encoder.onnx rk3588 fp ../image_encoder.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|██████████████████████████████████████████████| 227/227 [00:00<00:00, 28183.02it/s]
done
--> Building model
W build: The dataset='datasets/subset.txt' is ignored because do_quantization = False!
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 672.19it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 345.30it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 172.85it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 158.18it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 153.59it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 148.81it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 145.66it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 141.29it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 137.08it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 90.94it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
模型导出生成image_encoder.rknn和text_encoder.rknn,后面部署会将其复制到板卡上。
16.4.3. 部署测试¶
板卡上部署使用rknpu2的接口,然后获取部署例程,将前面导出的image_encoder.rknn和text_encoder.rknn模型复制 到lubancat_ai_manual_code/examples/mobileclip/model目录下。
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code.git
板卡上本地编译例程(教程测试lubancat-4):
# 安装相关库等
sudo apt update
sudo apt install libopencv-dev git make gcc g++ libsndfile1-dev
sudo apt install libboost-all-dev
# 复制前面转换出的rknn模型到model目录下
# 切换到例程目录
cd lubancat_ai_manual_code/examples/mobileclip/cpp
查看和修改model/text.txt输入文本:
a diagram
a dog
a cat
本地编译
cat@lubancat:~/xxx/mobileclip$ ./build-linux.sh -t rk3588
/build-linux.sh -t rk3588
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/home/cat/lubancat_ai_manual_code/example/mobileclip/cpp/install/rk3588_linux
BUILD_DIR=/home/cat/lubancat_ai_manual_code/example/mobileclip/cpp/build/build_rk3588_linux
DISABLE_RGA=OFF
BUILD_TYPE=Release
DISABLE_LIBJPEG=ON
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
-- The C compiler identification is GNU 13.3.0
-- The CXX compiler identification is GNU 13.3.0
-- Detecting C compiler ABI info
# 省略.................
[ 69%] Built target mobileclip
[ 84%] Built target imagedrawing
[100%] Built target audioutils
Install the project...
# 省略..........................
生成的可执行文件在install/rk3588_linux目录下,执行程序mobileclip_demo:
./mobileclip <image_model_path> <image_path> <text_model_path> <text_path>
# 第一个参数指rknn图像侧模型,第二个参数是输入的图像,第三个参数是rknn文本侧模型,第四个参数是输入文本
cat@lubancat:~/xxx/install/rk3588_linux$ ./mobileclip ../model/image_encoder.rknn ./model/dog_224x224.jpg ./model/text_encoder.rknn ./model/text.txt
model input num: 1, output num: 1
Input Tensor 0: index=0, name=image, n_dims=4, dims=[1, 256, 256, 3], n_elems=196608, size=393216, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1
Output Tensor 0: index=0, name=image_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1
Model Input Format: NHWC Height: 256 Width: 256 Channel: 3
model input num: 1, output num: 1
Input Tensor 0: index=0, name=text, n_dims=2, dims=[1, 77], n_elems=77, size=616, fmt=UNDEFINED, type=INT64, qnt_type=AFFINE, zp=0, scale=1
Output Tensor 0: index=0, name=text_features, n_dims=2, dims=[1, 512], n_elems=512, size=1024, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1
Model Input Format: UNDEFINED Batch Size: 1 Sequence Length: 77
-- Image inference time use: 30.646000 ms
-- text_features time use: 32.178001 ms
-- Similarity calculation time use: 0.016000 ms
Image: ./model/dog_224x224.jpg
Text: a diagram, Prob: 0.000001
Text: a dog, Prob: 0.999791
Text: a cat, Prob: 0.000208
以上就是在lubancat上简单测试mobileclip_s0模型,详情请查看配套例程,可自行修改优化。