
6. RKLLM¶
RKLLM 软件堆栈可以帮助用户快速将大语言模型部署到rk芯片上。
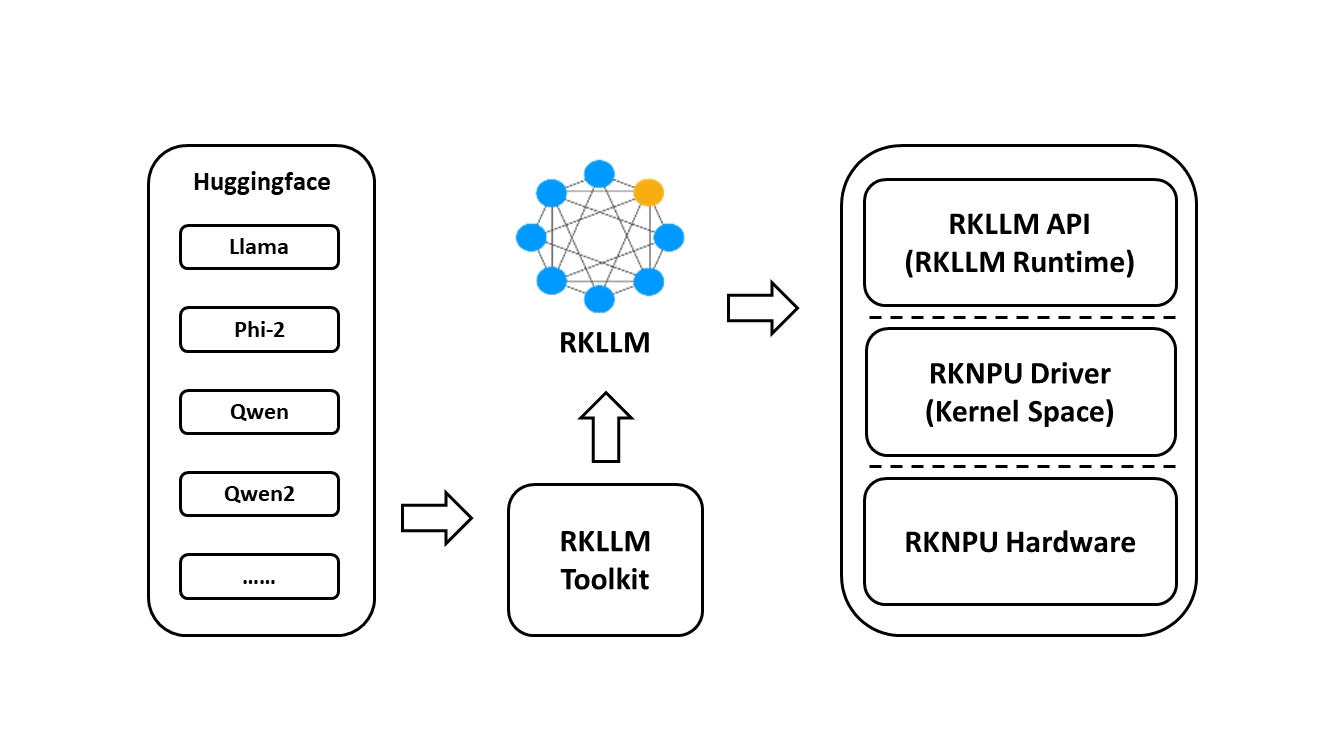
为了使用RKNPU,用户需要首先在计算机上安装RKLLM-Toolkit工具,将训练后的模型转换为RKLLM格式模型,然后在开发板上使用RKLLM C API进行推理。
RKLLM Toolkit是一个软件开发工具包,供用户在PC上进行模型转换和量化。 RKLLM Runtime为Rockchip NPU平台提供了C/C++编程接口,帮助用户部署RKLLM模型,加速LLM应用程序的实现。
RKLLM的整体开发步骤主要分为:模型转换和板端部署运行。
模型转换是使用RKLLM-Toolkit将预训练的大语言模型将会被转换为RKLLM格式。
板端部署运行是调用RKLLM Runtime库加载RKLLM模型到Rockchip NPU平台,然后进行推理等操作。
RKLLM支持RK3562, RK3576,RK3588等硬件平台,请使用 LubanCat-3/4/5系列板卡 。
重要
请注意教程测试RKLLM-Toolkit是1.3.0版本,测试lubancat-4板卡,系统使用Ubuntu,教程测试相关文件从配套例程获取。
6.1. RKLLM-Toolkit¶
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件。通过该 工具提供的接口可以便捷地完成模型转换和模型量化。
6.1.1. RKLLM-Toolkit安装¶
拉取RKLLM源码以及目录文件说明:
# 拉取源码
git clone https://github.com/airockchip/rknn-llm.git
# 目录说明
.
├── benchmark.md # 相关模型的测试性能
├── CHANGELOG.md # 更新日志
├── doc # RKLLM用户手册
├── examples # 模型转换示例
├── LICENSE
├── README.md
├── res
├── rkllm-runtime # 板端部署的库和例程
├── rkllm-toolkit # rkllm-toolkit包
├── rknpu-driver # RKNPU驱动
└── scripts # 固定cpu、ddr、npu频率的脚本
8 directories, 4 files
使用conda创建一个rkllm1.3.0环境(conda安装参考下前面章节):
# 创建RKLLM_Toolkit环境
conda create -n rkllm1.3.0 python=3.10
conda activate rkllm1.3.0
# 切换到前面拉取工程的rkllm-toolkit目录下
cd rknn-llm/rknn-toolkit/
# 安装rkllm_toolkit(文件请根据具体版本修改),会自动下载RKLLM-Toolkit工具所需要的相关依赖包。
(rkllm1.3.0) llh@llh:/xxx/rknn-llm/rkllm-toolkit$ pip3 install rkllm_toolkit-1.3.0-cp310-cp310-linux_x86_64.whl
简单检测下安装的RKLLM-Toolkit,正常是没有错误输出:
(rkllm1.3.0) llh@llh:/xxx$ python3
Python 3.10.18 (main, Jun 5 2025, 13:14:17) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from rkllm.api import RKLLM
>>>
6.1.2. RKLLM-Toolkit测试¶
RKLLM-Toolkit提供模型的转换、量化功能, 将Hugging Face格式或者GGUF格式的大语言模型转换为RKLLM模型,然后使用RKLLM Runtime的接口实现板端推理。
目前支持的模型有 LLAMA models, TinyLLAMA models, Qwen2/Qwen2.5/Qwen3, Phi2/Phi3, ChatGLM3-6B, Gemma2/Gemma3, InternLM2 models, MiniCPM3/MiniCPM4, TeleChat2, Qwen2-VL-2B-Instruct/Qwen2-VL-7B-Instruct/Qwen2.5-VL-3B-Instruct, MiniCPM-V-2_6,DeepSeek-R1-Distill,Janus-Pro-1B,InternVL2-1B,SmolVLM,RWKV7, 最新支持情况请查看 rknn-llm。
这里简单测试 Qwen3-0.6B 模型, 测试直接使用RKLLM-Toolkit转换成rkllm模型, 也可以先使用AutoGPTQ量化模型后,再转换为rkllm模型,如果用户修改了模型结构,RKLLM-Toolkit还支持自定义模型转换, 具体请参考 rknn-llm文档 ;
# 从modelscope获取Qwen3-0.6B
git clone https://www.modelscope.cn/models/Qwen/Qwen3-0.6B
git clone https://github.com/airockchip/rknn-llm
cd rknn-llm/examples/rkllm_api_demo/export/
模型导出程序是export_rkllm.py,位于rknn-llm/examples/rkllm_api_demo/export/目录下。
from rkllm.api import RKLLM
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
'''
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
Download the DeepSeek R1 model from the above url.
'''
modelpath = '/path/to/DeepSeek-R1-Distill-Qwen-1.5B'
llm = RKLLM()
# Load model
# Use 'export CUDA_VISIBLE_DEVICES=0' to specify GPU device
# device options ['cpu', 'cuda']
# dtype options ['float32', 'float16', 'bfloat16']
# Using 'bfloat16' or 'float16' can significantly reduce memory consumption but at the cost of lower precision
# compared to 'float32'. Choose the appropriate dtype based on your hardware and model requirements.
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cuda', dtype="float32", custom_config=None, load_weight=True)
# ret = llm.load_gguf(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)
# Build model
dataset = "./data_quant.json"
# Json file format, please note to add prompt in the input,like this:
# [{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手KK!"},...]
# Different quantization methods are optimized for different algorithms:
# w8a8/w8a8_gx is recommended to use the normal algorithm.
# w4a16/w4a16_gx is recommended to use the grq algorithm.
qparams = None # Use extra_qparams
target_platform = "RK3588"
optimization_level = 1
quantized_dtype = "W8A8"
quantized_algorithm = "normal"
num_npu_core = 3
ret = llm.build(do_quantization=True, optimization_level=optimization_level, quantized_dtype=quantized_dtype,
quantized_algorithm=quantized_algorithm, target_platform=target_platform, num_npu_core=num_npu_core, extra_qparams=qparams, dataset=dataset, hybrid_rate=0, max_context=4096)
if ret != 0:
print('Build model failed!')
exit(ret)
# Export rkllm model
ret = llm.export_rkllm(f"./{os.path.basename(modelpath)}_{quantized_dtype}_{target_platform}.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)
1、调用RKLLM-Toolkit提供的接口,初始化RKLLM对象,然后调用rkllm.load_huggingface()函数加载模型;
2、通过rkllm.build()函数对RKLLM模型的构建,需要设置参数do_quantization是否量化, 设置目标平台等等,详细参数请参考 rknn-llm文档 ;
3、最后通过rkllm.export_rkllm()函数将模型导出为RKLLM模型文件。
在运行export_rkllm.py程序之前,可以先根据模型特点与使用场景准备生成量化的校准样本, 运行程序generate_quant_data.py生成量化校正数据集,该数据集用于后面模型量化,如果没有相关数据,可以不设置rkllm.build()的dataset参数。
运行export_rkllm.py,转换模型为RKLLM模型:
# 先修改export_rkllm.py中的模型的路径:
modelpath = '/path/to/Qwen/Qwen3-0.6B'
# 例程测试lubancat-4 rk3588
(rkllm1.3.0) llh@anhao:/xxx$ python3 export_rkllm.py
INFO: rkllm-toolkit version: 1.3.0
Building model: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 427/427 [00:03<00:00, 121.62it/s]
Optimizing model: 64%|███████████████████████████████████████████████████████████▏ | 274/427 [00:00<00:00, 274.88it/s]
# 省略.............
INFO: Setting eos to [151645, 151643]
INFO: Setting bos to 151643
INFO: Setting add_bos_token to False
Converting model: 100%|█████████████████████████████████████████████████████████████████████| 311/311 [00:00<00:00, 3814118.55it/s]
INFO: Setting max_context_limit to 4096
INFO: Exporting the model, please wait ....
[=================================================>] 597/597 (100%)
INFO: Model saved to Qwen3-0.6B.rkllm!
RKLLM模型转换成功后,会在当前目录生成qwen.rkllm文件,然后将该文件到板卡系统中(用于后面部署测试)。
教程测试的Qwen3-0.6B.rkllm可以从 网盘资料 获取(提取码:hslu), 在鲁班猫->1-野火开源图书_教程文档->AI教程相关源文件->rkllm目录下。
6.2. RKLLM Runtime¶
RKLLM Runtime库是RKLLM-Toolkit的运行时库,主要提供加载RKLLM模型、进行推理等操作。
6.2.1. RKLLM模型推理示例¶
在板卡上获取RKLLM文件,或者复制前面获取的文件复制到板卡上,教程测试是直接到板卡上编译, 如果是交叉编译请获取下 交叉编译器 , 然后设置交叉编译器路径,其他类似。
git clone https://github.com/airockchip/rknn-llm
cd rknn-llm/examples/rkllm_api_demo/deploy
部署例程如下(部分):
// 省略..........................
while (true)
{
std::string input_str;
printf("\n");
printf("user: ");
std::getline(std::cin, input_str);
if (input_str == "exit")
{
break;
}
if (input_str == "clear")
{
ret = rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr);
if (ret != 0)
{
printf("clear kv cache failed!\n");
}
continue;
}
for (int i = 0; i < (int)pre_input.size(); i++)
{
if (input_str == to_string(i))
{
input_str = pre_input[i];
cout << input_str << endl;
}
}
rkllm_input.input_type = RKLLM_INPUT_PROMPT;
rkllm_input.role = "user";
rkllm_input.prompt_input = (char *)input_str.c_str();
printf("robot: ");
// 若要使用普通推理功能,则配置rkllm_infer_mode为RKLLM_INFER_GENERATE或不配置参数
rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL);
}
rkllm_destroy(llmHandle);
return 0;
RKLLM板端推理整体调用流程:
1、定义回调函数callback();
2、定义RKLLM模型参数结构体RKLLMParam,设置采样参数,推理参数,聊天模板等等,详细参数请解释参考 rknn-llm文档 ;
3、rkllm_init()初始化RKLLM模型;
4、rkllm_run()进行模型推理,通过回调函数callback()对模型实时传回的推理结果进行处理;
5、最后调用rkllm_destroy()释放RKLLM模型和资源。
如果不是本地编译,需要修改例程中build-linux.sh文件的编译器路径 GCC_COMPILER_PATH=aarch64-linux-gnu ,指定交叉编译器的路径。
GCC_COMPILER_PATH=aarch64-linux-gnu
#GCC_COMPILER_PATH=~/opts/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu
C_COMPILER=${GCC_COMPILER_PATH}-gcc
CXX_COMPILER=${GCC_COMPILER_PATH}-g++
STRIP_COMPILER=${GCC_COMPILER_PATH}-strip
然后执行build-linux.sh编译例程:
cat@lubancat:~$ sudo apt update
cat@lubancat:~$ sudo apt install gcc g++ cmake
# 鲁班猫4板卡上本地编译
cat@lubancat:~/xxx/deploy$ chmod +x build-linux.sh
cat@lubancat:~/xxx/deploy$ ./build-linux.sh
-- The C compiler identification is GNU 13.3.0
-- The CXX compiler identification is GNU 13.3.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/aarch64-linux-gnu-gcc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/aarch64-linux-gnu-g++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done (1.3s)
-- Generating done (0.0s)
-- Build files have been written to: /home/cat/rkllm/deploy/build/build_linux_aarch64_Release
[ 50%] Building CXX object CMakeFiles/llm_demo.dir/src/llm_demo.cpp.o
[100%] Linking CXX executable llm_demo
[100%] Built target llm_demo
[100%] Built target llm_demo
Install the project...
-- Install configuration: "Release"
-- Installing: /home/cat/rkllm/deploy/install/demo_Linux_aarch64/./llm_demo
-- Set non-toolchain portion of runtime path of "/home/cat/rkllm/deploy/install/demo_Linux_aarch64/./llm_demo" to ""
-- Installing: /home/cat/rkllm/deploy/install/demo_Linux_aarch64/lib/librkllmrt.so
cat@lubancat:~/rkllm/deploy$
编译完成后,会在当前目录下的install/build_linux_aarch64_Release输出可执行文件llm_demo。 执行RKLLM模型推理:
# 切换到install/build_linux_aarch64_Release目录下
cd install/build_linux_aarch64_Release/
# 临时设置rkllm runtime库路径,也可以将librkllmrt.so文件复制到系统库/usr/lib下
export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
# 或者将librkllmrt.so复制到系统库路径下
# sudo cp ./lib/librkllmrt.so /usr/lib/
# 将前面RKLLM-Toolkit测试小节转换出的rkllm模型复制到板卡,设置模型路径,执行rkllm推理
# Usage: ./llm_demo model_path max_new_tokens max_context_len
./llm_demo ~/Qwen-1_8B-Chat-q.rkllm 256 256
# 如果需要查看性能
export RKLLM_LOG_LEVEL=1
测试输出:
# 测试lubancat-4
# Usage: ./llm_demo model_path max_new_tokens max_context_len
cat@lubancat:/xxx/install/build_linux_aarch64_Release$ export RKLLM_LOG_LEVEL=1
cat@lubancat:~/xxx/install/demo_Linux_aarch64$ ./llm_demo ~/Qwen3-0.6B.rkllm 256 256
rkllm init start
I rkllm: rkllm-runtime version: 1.3.0, rknpu driver version: 0.9.8, platform: RK3588
I rkllm: loading rkllm model from /home/cat/Qwen3-0.6B.rkllm
I rkllm: rkllm-toolkit version: 1.3.0, max_context_limit: 4096, npu_core_num: 3, target_platform: RK3588, model_dtype: W8A8
I rkllm: Enabled cpus: [4, 5, 6, 7]
I rkllm: Enabled cpus num: 4
rkllm init success
**********************可输入以下问题对应序号获取回答/或自定义输入********************
[0] 现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?
[1] 有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?
*************************************************************************
user: 1
有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?
robot: 我们来分析这个问题:
- 有 **28** 个小朋友排成一排。
- 左边开始数,第 **10** 位是学豆。
我们要找出从 **右边开始数** 的位置。
---
### 步骤如下:
1. 总共有 28 位小朋友。
2. 第 10 位是从左边开始数的。
3. 所以,从右边开始数的位置就是:
$$
28 - 10 + 1 = \boxed{19}
$$
---
### ✅ 答案:
**从右边开始数是第 19 位。**
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Model init time (ms) 950.67
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Stage Total Time (ms) Tokens Time per Token (ms) Tokens per Second
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Prefill 134.21 41 3.27 305.50
I rkllm: Generate 5967.97 143 41.73 23.96
I rkllm: --------------------------------------------------------------------------------------
I rkllm: Peak Memory Usage (MB)
I rkllm: 784.37
I rkllm: --------------------------------------------------------------------------------------
user: