
19. Whisper¶
Whisper 是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练, 能够在英语语音识别上达到接近人类水平的鲁棒性和准确性,Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。
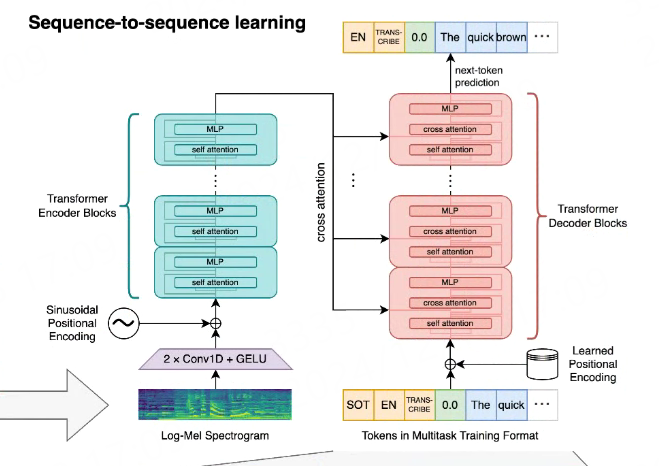
Whisper是一个简单的端到端方法,采用了encoder-decoder结构的Transformer模型, 将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
github地址:https://github.com/openai/whisper
本章将简单测试Whisper模型,然后在鲁班猫rk系列板卡上部署(使用npu)。
19.1. Whisper简单使用¶
在PC上创建一个虚拟环境,安装pytorch环境,然后简单使用Whisper。
# 使用conda创建虚拟环境
conda create -n whisper python=3.10
conda activate whisper
# 根据自行的环境安装pytorch,详细命令参考https://pytorch.org/get-started/locally/,下面是参考命令:
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
# 配置pip源(可选)
# pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
拉取whisper源码,安装相关依赖库:
# 教程测试时是v20240930版本
git clone https://github.com/openai/whisper
cd whisper
pip install -r requirements.txt
简单编程测试,在whisper目录下创建一个test_whisper.py文件 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import whisper
import numpy as np
model = whisper.load_model("base")
print(
f"Model is {'multilingual' if model.is_multilingual else 'English-only'} "
f"and has {sum(np.prod(p.shape) for p in model.parameters()):,} parameters."
)
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("../audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
|
运行测试程序:
# 随便获取一段mp3测试文件
# audio.mp3
# 测试例程,测试的是base模型,例程将会自动下载该模型
(whisper) llh@llh:/xxx/whisper$ python test_model.py
checkpoint = torch.load(fp, map_location=device)
Model is multilingual and has 71,825,920 parameters.
torch.Size([80, 3000])
Detected language: zh
各位觀眾 晚上好晚上好今天是12月29號 星期四 農曆12月初期歡迎收看新聞聯播節目首先為您介紹今天節目的主要內容
19.2. Whisper部署测试¶
在鲁班猫RK系列板卡上部署Whisper模型,需要先使用将其导出onnx模型,然后使用 使用toolkit2工具转换成rknn模型,最后通过rknpu2提供的接口在板卡上部署。
19.2.1. 导出onnx模型¶
参考 rknn_model_zoo 中的转换程序export_onnx.py,导出onnx模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Export whisper onnx model', add_help=True)
parser.add_argument('--model_type', type=str, required=True, default= 'base',
help='model type, could be tiny, base, small, medium, ...')
parser.add_argument('--n_mels', type=int, required=False, default= 80, help='number of mels')
args = parser.parse_args()
print('whisper available_models: ', whisper.available_models())
model = setup_model(args.model_type)
x_mel, encoder_output, x_tokens = setup_data(model, args.n_mels)
save_encoder_model_path = "./whisper_encoder_{}.onnx".format(args.model_type)
save_decoder_model_path = "./whisper_decoder_{}.onnx".format(args.model_type)
torch.onnx.export(
model.encoder,
(x_mel),
save_encoder_model_path,
input_names=["x"],
output_names=["out"],
opset_version=12
)
torch.onnx.export(
model.decoder,
(x_tokens, encoder_output),
save_decoder_model_path,
input_names=["tokens", "audio"],
output_names=["out"],
opset_version=12
)
simplify_onnx_model(save_encoder_model_path)
print("\nThe encoder model is saved in:", save_encoder_model_path)
simplify_onnx_model(save_decoder_model_path)
print("The decoder model is saved in:", save_decoder_model_path)
|
执行export_onnx.py程序,参数–model_type指定模型类型,只支持tiny, base或者medium。
测试使用v20231117版本的whisper,如果使用最新版本v20240930版本等等,需要关闭scaled_dot_product_attention等。
# 获取whisper
git clone https://github.com/openai/whisper -b v20231117
# 将export_onnx.py复制到Whisper工程目录下(如果是直接命令安装whisper,则不需要)
# 根据自己的需要修改onnx模型保存路径,然后执行程序
(whisper) llh@llh:/xxx/whisper$ python export_onnx.py --model_type base
whisper available_models: ['tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'medium.en',
'medium', 'large-v1', 'large-v2', 'large-v3', 'large', 'large-v3-turbo', 'turbo']
# 省略.................
The encoder model is saved in: ./whisper_encoder_base.onnx
The decoder model is saved in: ./whisper_decoder_base.onnx
默认导出的onnx模型是输入30秒语音,保存为whisper_encoder_base.onnx和whisper_decoder_base.onnx, 如果是要导出20秒需要修改:
# 1.修改whisper/audio.py文件中的参数CHUNK_LENGTH
CHUNK_LENGTH = 30
-->> CHUNK_LENGTH = 20
# 2.修改whisper/model.py文件的positional_embedding部分
assert x.shape[1:] == self.positional_embedding.shape, "incorrect audio shape"
-->> # assert x.shape[1:] == self.positional_embedding.shape, "incorrect audio shape"
x = (x + self.positional_embedding).to(x.dtype)
-->> x = (x + self.positional_embedding[-x.shape[1]:,:]).to(x.dtype)
修改之后,重新执行前面命令导出onnx模型。
需要注意后面c++部署程序默认以20秒的base模型为例,测试其他模型需要修改process.h文件中CHUNK_LENGTH和ENCODER_OUTPUT_SIZE, 例如:测试30秒的语音base模型,修改CHUNK_LENGTH = 30,ENCODER_OUTPUT_SIZE = CHUNK_LENGTH * 50 * 512。
19.2.2. 转换成rknn模型¶
使用toolkit2工具,简单编程,将onnx模型转换成rknn模型,注意输入输出的配置。
下面是转换whisper_encoder模型成rknn模型:
# Usage: python3 convert_30.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
# platform choose from [rk3562,rk3566,rk3568,rk3576,rk3588]
# dtype choose from [fp] for [rk3562,rk3566,rk3568,rk3576,rk3588]
(toolkit2_2.3) llh@llh:/xxx/whisper$ python convert.py whisper_encoder_base_20s.onnx rk3588 fp whisper_encoder_base_20s.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|█████████████████████████████████████████████████| 93/93 [00:00<00:00, 4742.50it/s]
W load_onnx: The config.mean_values is None, zeros will be set for input 0!
W load_onnx: The config.std_values is None, ones will be set for input 0!
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 186.41it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 149.50it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 114.74it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 114.03it/s]
I OpFusing 2 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 112.61it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 110.45it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 109.44it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:02<00:00, 36.66it/s]
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
下面是转换whisper_decoder模型成rknn模型:
# Usage: python3 convert_30.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
# platform choose from [rk3562,rk3566,rk3568,rk3576,rk3588]
# dtype choose from [fp] for [rk3562,rk3566,rk3568,rk3576,rk3588]
(toolkit2_2.3) llh@llh:/xxx/rknn$ python convert.py whisper_decoder_base_20s.onnx rk3588 fp whisper_decoder_base_20s.rknn
I rknn-toolkit2 version: 2.3.0
--> Config model
done
--> Loading model
I Loading : 100%|███████████████████████████████████████████████| 147/147 [00:00<00:00, 2243.25it/s]
W load_onnx: The config.mean_values is None, zeros will be set for input 1!
W load_onnx: The config.std_values is None, ones will be set for input 1!
done
--> Building model
# 省略..................................................
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 120.33it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 94.34it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 65.60it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 65.24it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 64.41it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 61.98it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 61.37it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 50.24it/s]
I rknn building ...
E RKNN: [17:34:18.571] channel is too large, may produce thousands of regtask, fallback to cpu!
E RKNN: [17:34:18.571] channel is too large, may produce thousands of regtask, fallback to cpu!
E RKNN: [17:34:18.571] channel is too large, may produce thousands of regtask, fallback to cpu!
E RKNN: [17:34:18.571] channel is too large, may produce thousands of regtask, fallback to cpu!
E RKNN: [17:34:18.613] channel is too large, may produce thousands of regtask, fallback to cpu!
I rknn building done.
done
--> Export rknn model
done
19.2.3. 部署测试¶
在鲁班猫板卡上,获取部署例程:
# 例程可能没有及时更新,请等待.
# git clone xxxxxx
# 或者直接使用rknn_model_zoo的whisper,详细使用请查看工程的README文件
git clone https://github.com/airockchip/rknn_model_zoo.git
直接编译例程:
# 板卡系统安装相关库
sudo apt update
sudo apt install libfftw3-dev libsndfile1-dev libsdl2-dev
# 将前面转换好的模型放在例程model路径中
# 编译例程,如果是lubancat4/5设置参数-t rk3588 , 如果是lubancat-3设置rk3576
cat@lubancat:~/xxx/examples/whisper/cpp$ ./build-linux.sh -t rk3588
./build-linux.sh -t rk3588
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/home/cat/xxx/examples/whisper/cpp/install/rk3588_linux
BUILD_DIR=/home/cat/xxx/examples/whisper/cpp/build/build_rk3588_linux
DISABLE_RGA=OFF
BUILD_TYPE=Release
ENABLE_ASAN=OFF
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
===================================
-- 64bit
-- OpenCV_DIR=/home/cat/xxxx/examples/whisper/cpp/../../../3rdparty/opencv/opencv-linux-aarch64/share/OpenCV
-- OpenCV_LIBS=opencv_calib3dopencv_coreopencv_features2dopencv_imgcodecsopencv_imgprocopencv_video
-- Configuring done
-- Generating done
-- Build files have been written to: /home/cat/xxxx/examples/whisper/cpp/build/build_rk3588_linux
[ 16%] Built target imagedrawing
[ 58%] Built target fileutils
[ 66%] Built target imageutils
[ 66%] Built target audioutils
[ 75%] Linking CXX executable rknn_whisper_demo
[100%] Built target rknn_whisper_demo
[ 16%] Built target fileutils
[ 33%] Built target audioutils
[ 66%] Built target rknn_whisper_demo
[ 83%] Built target imageutils
[100%] Built target imagedrawing
Install the project...
# 省略...........................
测试对语音文件的识别,切换到install/rk3588_linux目录下,然后执行rknn_whisper_demo例程:
# 测试英语语言识别
# ./rknn_whisper_demo <encoder_path> <decoder_path> <task> <audio_path>
cat@lubancat:~/xxx/install/rk3588_linux$ ./rknn_whisper_demo ./whisper_encoder_base_20s.rknn .//whisper_decoder_base_20s.rknn en model/test_en.wav
-- read_audio & convert_channels & resample_audio use: 3.202000 ms
-- read_mel_filters & read_vocab use: 43.681999 ms
model input num: 1, output num: 1
input tensors:
index=0, name=x, n_dims=3, dims=[1, 80, 2000], n_elems=160000, size=320000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=out, n_dims=3, dims=[1, 1000, 512], n_elems=512000, size=1024000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
-- init_whisper_encoder_model use: 73.750000 ms
model input num: 2, output num: 1
input tensors:
index=0, name=tokens, n_dims=2, dims=[1, 12], n_elems=12, size=96, fmt=UNDEFINED, type=INT64, qnt_type=AFFINE, zp=0, scale=1.000000
index=1, name=audio, n_dims=3, dims=[1, 1000, 512], n_elems=512000, size=1024000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=out, n_dims=3, dims=[1, 12, 51865], n_elems=622380, size=1244760, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
-- init_whisper_decoder_model use: 168.871994 ms
-- inference_whisper_model use: 2586.520020 ms
Whisper output: Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.
Real Time Factor (RTF): 2.587 / 5.855 = 0.442
# 测试中文语言识别
cat@lubancat:~/xxx/install/rk3588_linux$ ./rknn_whisper_demo ./whisper_encoder_base_20s.rknn .//whisper_decoder_base_20s.rknn zh model/test_zh.wav
-- read_audio & convert_channels & resample_audio use: 2.080000 ms
-- read_mel_filters & read_vocab use: 39.435001 ms
model input num: 1, output num: 1
input tensors:
index=0, name=x, n_dims=3, dims=[1, 80, 2000], n_elems=160000, size=320000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=out, n_dims=3, dims=[1, 1000, 512], n_elems=512000, size=1024000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
-- init_whisper_encoder_model use: 90.671997 ms
model input num: 2, output num: 1
input tensors:
index=0, name=tokens, n_dims=2, dims=[1, 12], n_elems=12, size=96, fmt=UNDEFINED, type=INT64, qnt_type=AFFINE, zp=0, scale=1.000000
index=1, name=audio, n_dims=3, dims=[1, 1000, 512], n_elems=512000, size=1024000, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=out, n_dims=3, dims=[1, 12, 51865], n_elems=622380, size=1244760, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
-- init_whisper_decoder_model use: 159.106995 ms
-- inference_whisper_model use: 2239.787109 ms
Whisper output: 对我做了介绍,我想做的是大家如果对我的研究感兴趣
Real Time Factor (RTF): 2.240 / 5.611 = 0.399
以上就是鲁班猫rk系列板卡上简单测试whisper的步骤,测试例程请参考 https://github.com/airockchip/rknn_model_zoo。