
3. 手写数字识别¶
本章使用PaddlePaddle深度学习框架,以手写数字识别为例,简单介绍下:
介绍下分类问题以及卷积神经网络等相关知识
如何使用paddlepaddle构建和优化一个神经网络
如何将训练的模型转换为rknn模型
如何在板卡上部署模型
提示
测试环境:鲁班猫板卡系统使用Debian或者ubuntu,PC端是ubuntu20.04,rknn-Toolkit2版本1.5.0。
3.1. 卷积神经网络¶
卷积神经网络(convolutional neural network,CNN)是目前计算机视觉中使用最普遍的模型结构。 基于卷积神经网络架构的模型在计算机视觉领域中占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关问题都以这种方法为基础。
3.2. 训练MINST手写数字识别模型¶
手写数字识别是一个典型的图像分类问题, 图像分类是卷积神经网络的一项重要应用,根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心, 是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。 图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别, 互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
常见的图像分类的卷积神经网络:LeNet、AlexNet、VGG、GoogLeNet、ResNet等等。
下面训练一个手写数字识别模型然后在板端部署的完整过程:
准备数据集
构建神经网络模型
训练模型
评估模型
导出模型和模型转换,模拟推理
板端部署推理
下面我们将按照上面步骤,在板卡上训练手写数字识别模型, 具体操作可以参考 handwritten.ipynb 。
3.2.1. 准备数据集¶
MNIST数据集是机器学习中常见的数据集,可以从该网址下载: http://yann.lecun.com/exdb/mnist/ , 该数据集包含四个文件:
t10k-images-idx3-ubyte.gz,是训练集的图片,总共10 000张。
t10k-labels-idx1-ubyte.gz,是训练集图片的标签(label),从0~9的数字,总共10 000条。
train-images-idx3-ubyte.gz,是训练集的图片,总共60 000张。
train-labels-idx1-ubyte.gz,是训练集图片的标签(label),从0~9的数字,总共60 000条。
使用PaddlePaddle深度学习框架,可以直接使用自带的API接口,下载MNIST数据集并读取该数据集(其他深度度学习框架也类似)。 默认会下载到用户目录下的缓存数据集路径下(~/.cache/paddle/dataset/mnist/)。
通常将样本集合分成训练集、校验集和测试集。
训练集,用于训练模型的参数,即训练过程中主要完成的工作。
校验集,用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。
测试集,用于模拟模型在应用后的真实效果。因为测试集没有参与任何模型优化或参数训练的工作,所以它对模型来说是完全未知的样本。 在不以校验数据优化网络结构或模型超参数时,校验数据和测试数据的效果是类似的,均更真实的反映模型效果。
这里将导入训练和测试数据,也就是只分为训练集和测试集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 导入必要的paddle模块
# paddle.nn 是组网相关的API
# paddle.vision 视觉领域相关API,包括常见的数据集,相关处理等
# paddle.io 输入输出相关API,主要是数据集的导入读取等
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear
import paddle.nn.functional as F
from paddle.vision.transforms import Normalize
import numpy as np
import os
# 下载数据集并初始化,导入训练和测试数据集,并对数据进行处理
transform = Normalize(mean=[127.5], std=[127.5])
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
|
3.2.2. 模型设计¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # 定义模型结构
# 多层卷积神经网络实现
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 定义一层全连接层,输出维度是10
self.fc = Linear(in_features=980, out_features=10)
# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出
# 卷积层激活函数使用Relu,全连接层激活函数使用softmax
def forward(self, inputs, label):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
|
模型定义前面部分使用paddle.nn 提供的Conv2D和MaxPool2D函数,网络第一层是卷积层,
3.2.3. 模型训练¶
先使用 paddle.io.DataLoader API读取数据,该接口实现异步数据读取, 数据会由Python线程预先读取,并异步送入一个队列中,读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取,数据读取和模型训练并行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | def train(model):
model.train()
# 调用加载数据的函数,设置mini-batch 中样本个数为100,设置shuffle=True打乱顺序
train_loader = paddle.io.DataLoader(train_dataset, batch_size=100, shuffle=True)
# 四种优化算法的设置方案,可以逐一尝试效果
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())
# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 10
iter=0
iters=[]
losses=[]
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
# 准备数据
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
# 前向计算的过程,同时计算分类准确率
predicts, acc = model(images, labels)
#predicts = model(images)
# 计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
# 每训练了100批次的数据,打印下当前Loss的情况
if batch_id % 100 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.item(), acc.item()))
iters.append(iter)
losses.append(avg_loss.item())
iter = iter + 100
# 后向传播,更新参数的过程
avg_loss.backward()
# 最小化loss,更新参数
opt.step()
# 清除梯度
opt.clear_grad()
# 保存模型参数
paddle.save(model.state_dict(), './paddle/mnist.pdparams')
return iters, losses
# 创建模型
model = MNIST()
#paddle.summary(model, (1, 1, 28, 28))
# 启动训练过程
#开启GPU
#use_gpu = True
#paddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')
iters, losses = train(model)
# 画出训练过程中Loss的变化曲线
plt.figure()
plt.title("train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, losses,color='red',label='train loss')
plt.grid()
plt.show()
|
上面程序如果取消paddle.summary(model, (1, 1, 28, 28))的注释,会打印网络结构:
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-3 [[1, 1, 28, 28]] [1, 20, 28, 28] 520
MaxPool2D-3 [[1, 20, 28, 28]] [1, 20, 14, 14] 0
Conv2D-4 [[1, 20, 14, 14]] [1, 20, 14, 14] 10,020
MaxPool2D-4 [[1, 20, 14, 14]] [1, 20, 7, 7] 0
Linear-2 [[1, 980]] [1, 10] 9,810
===========================================================================
Total params: 20,350
Trainable params: 20,350
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.19
Params size (MB): 0.08
Estimated Total Size (MB): 0.27
---------------------------------------------------------------------------
不开启打印网络结构,直接训练显示的Loss的变化曲线:
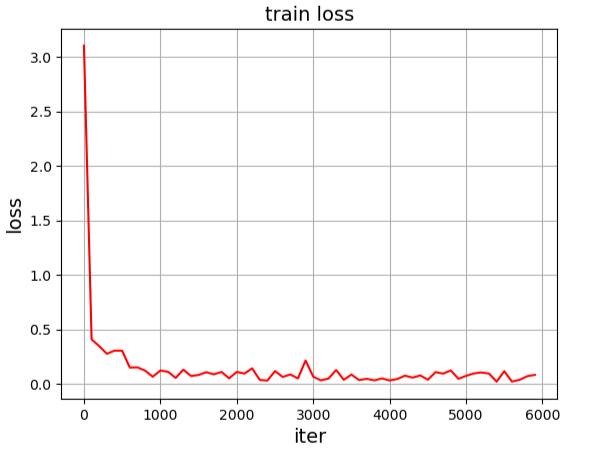
3.2.4. 模型测试¶
这里用测试集来简单评估下模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # 定义预测函数
def evaluation(model):
# 加载模型参数
params_file_path = './paddle/mnist.pdparams'
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
eval_loader = paddle.io.DataLoader(test_dataset)
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
predicts, acc = model(images, labels)
loss = F.cross_entropy(input=predicts, label=labels)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 计算多个batch的平均损失和准确率
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
model = MNIST()
evaluation(model)
|
测试输出:
loading mnist model from ./paddle/mnist.pdparams
loss=0.05035130242863519, acc=0.9844
3.3. 导出rknn模型和模拟推理测试¶
Paddle模型不能直接转换成rknn模型,需要先转换为onnx模型,然后使用rknn-toolkit2转换模型成rknn模型。
1、将我们训练的模型保存为onnx模型
1 2 3 4 5 6 | # 需要保存的路径,当前onnx目录下
save_path = 'onnx/handwritten'
# 为模型指定输入的形状和数据类型
x_spec = paddle.static.InputSpec([1, 1, 28, 28], 'float32', 'x')
# 生成ONNX模型
paddle.onnx.export(model, save_path, input_spec=[x_spec], opset_version=11)
|
转换成功后,会在当前onnx目录下生成handwritten.onnx模型文件,运行输出:
2023-09-09 09:03:22 [INFO] Static PaddlePaddle model saved in onnx/paddle_model_static_onnx_temp_dir.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: onnx/paddle_model_static_onnx_temp_dir/model.pdmodel
[Paddle2ONNX] Paramters file path: onnx/paddle_model_static_onnx_temp_dir/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2023-09-09 09:03:22 [INFO] ONNX model saved in onnx/handwritten.onnx.
2、 使用rknn-toolkit2转换模型成rknn模型,并进行简单推理测试
我们将在PC端,使用安装了rknn-toolkit2的环境中进行转换,rknn-toolkit2的安装参考下前面章节。 本例中rknn-toolkit2的转换模型和推理的流程:
创建RKNN对象,初始化RKNN环境;
设置模型预处理参数,通过模拟器运行模型时需要调用config接口设置模型的预处理参数;
导入模型,使用load_onnx接口导入模型;
构建RKNN模型,调用build接口构建RKNN模型;
调用export_rknn接口导出RKNN模型,同时可以使用init_runtime初始化运行环境,在模拟器上模拟推理;
初始化运行环境后,可以调用inference接口进行模拟推理;
最后调用release接口释放RKNN对象。
测试文件的主体部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | if __name__ == '__main__':
# 创建RKNN对象
rknn = RKNN()
# 配置,这里测试lubancat-4指定平台是rk3588,如果是lubancat0/1/2指定平台rk3566、rk3568
print('--> Config model')
rknn.config(mean_values=[[127.5]], std_values=[[127.5]], target_platform='rk3588')
print('done')
# 导入onnx模型
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# 构建模型,这里QUANTIZE_ON=False,不使用量化
print('--> Building model')
#ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
ret = rknn.build(do_quantization=QUANTIZE_ON)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# 导出rknn模型
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# 读取图像
img = cv2.imread(IMG_PATH)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
img = np.expand_dims(img, 0)
img = np.expand_dims(img, 0)
# 模拟推理
print('--> Running model')
outputs = rknn.inference(inputs=[img], data_format='nchw')
print('done')
# 打印输出结果
print("outputs: ", outputs)
print("本次预测的数字是:", np.argmax(outputs))
rknn.release()
|
运行onnx_to_rknn.py显示:
W __init__: rknn-toolkit2 version: 1.5.0+1fa95b5c
--> Config model
done
--> Loading model
W load_onnx: It is recommended onnx opset 12, but your onnx model opset is 11!
Loading : 100%|█████████████████████████████████████████████████████| 7/7 [00:00<00:00, 9288.24it/s]
done
--> Building model
done
--> Export rknn model
done
--> Init runtime environment
W init_runtime: Target is None, use simulator!
done
--> Running model
Analysing : 100%|███████████████████████████████████████████████████| 8/8 [00:00<00:00, 4285.92it/s]
Preparing : 100%|███████████████████████████████████████████████████| 8/8 [00:00<00:00, 1258.94it/s]
done
outputs: [array([[ 8.6328125 , -0.21862793, 3.5253906 , 0.38549805, -1.8681641 ,
-0.39990234, 1.3476562 , -0.90722656, -1.328125 , 0.8574219 ]],
dtype=float32)]
本次预测的数字是: 0
转换出的handwritten.rknn文件,将保存到变量RKNN_MODEL指定的目录下。
3.4. 板端部署推理¶
前面小节我们使用rknn-toolkit2工具,转换出来handwritten.rknn文件,那如何在板卡端部署? 我们可以使用RKNN API接口(C/C++)或者RKNN Toolkit Lite2接口(Python),这些接口的使用参考下前面章节, 下面我们演示下在鲁班猫板卡上部署模型。
1、使用Toolkit Lite2部署测试
Toolkit Lite2的使用流程参考下前面 《RKNN Toolkit Lite2介绍》 。 下面是手写数字识别模型在板端部署推理的程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | # 创建RKNNLite对象
# rknn_lite = RKNNLite(verbose=True)
rknn_lite = RKNNLite()
# 调用load_rknn接口导入RKNN模型,需要对应平台(rk356x/rk3588)的模型
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(rknn_model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
# 调用init_runtime接口初始化运行时环境
print('--> Init runtime environment')
ret = rknn_lite.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# 读取图像,对图像数据预处理
img = cv2.imread(IMG_PATH)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = cv2.resize(img,(28,28))
img = np.expand_dims(img, 0)
# runing model
print('--> Running model')
outputs = rknn_lite.inference(inputs=[img])
# 输出结果
print("outputs: ", outputs)
print("板端本次预测的数字是:", np.argmax(outputs))
# 调用release接口释放RKNNLite对象
rknn_lite.release()
|
在板卡上运行输出(lubancat-4):
cat@lubancat:~/handwritten$ python3 rknn_inference.py
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [14:15:06.736] RKNN Runtime Information: librknnrt version: 1.5.0 (e6fe0c678@2023-05-25T08:09:20)
I RKNN: [14:15:06.736] RKNN Driver Information: version: 0.8.8
I RKNN: [14:15:06.736] RKNN Model Information: version: 4, toolkit version: 1.5.0+1fa95b5c(compiler version: 1.5.0 (e6fe0c678@2023-05-25T16:15:03)),
target: RKNPU v2, target platform: rk3588, framework name: ONNX, framework layout: NCHW, model inference type: static_shape
done
--> Running model
outputs: [array([[ 8.640625 , -0.20239258, 3.53125 , 0.3876953 , -1.8496094 ,
-0.40698242, 1.3486328 , -0.91503906, -1.3388672 , 0.8515625 ]],
dtype=float32)]
板端本次预测的数字是: 0
2、使用RKNN API部署测试
在板端部署手写数字识别模型,使用RKNN API 接口,具体调用流程参考下 《RKNN API》 。 这里简单测试,使用通用API接口,主要部分代码如下(详细查看下配套例程,配套例程可能没有及时更新):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | // .....前面省略
/*-------------------------------------------
Main Functions
-------------------------------------------*/
int main(int argc, char** argv)
{
// ....省略
// 初始化rknn,导入rknn模型
printf("Loading mode %s ...\n", model_name);
int model_data_size = 0;
unsigned char* model_data = load_model(model_name, &model_data_size);
ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
// 打印输出RKNN驱动版本,API版本
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("sdk version: %s driver version: %s\n", version.api_version, version.drv_version);
// 查询模型输入和输出,并打印输出
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
}
// .....中间部分省略....
// 读取图像
printf("Read %s ...\n", image_name);
cv::Mat orig_img = cv::imread(image_name, 1);
if (!orig_img.data) {
printf("cv::imread %s fail!\n", image_name);
return -1;
}
cv::Mat img;
cv::cvtColor(orig_img, img, cv::COLOR_RGB2GRAY);
img_width = img.cols;
img_height = img.rows;
printf("img width = %d, img height = %d\n", img_width, img_height);
// 重新设置图像尺寸,例程测试就简单使用opencv
if (img_width != width || img_height != height) {
printf("resize with Opencv! \n");
cv::Mat resize_image;
cv::resize(img, resize_image, cv::Size(width, height), cv::INTER_LINEAR);
inputs[0].buf = (void*)resize_image.data;
} else {
inputs[0].buf = (void*)img.data;
}
// 设置输入输出
rknn_inputs_set(ctx, io_num.n_input, inputs);
rknn_output outputs[1];
outputs[0].want_float = 1;
// 运行推理,得到推理结果
gettimeofday(&start_time, NULL);
ret = rknn_run(ctx, NULL);
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
gettimeofday(&stop_time, NULL);
printf("once run use %f ms\n", (__get_us(stop_time) - __get_us(start_time)) / 1000);
// 打印输出
float* buffer = (float*)outputs[0].buf;
printf("outputs: ");
for (int i = 0; i < 10; i++) {
printf("%.6f ", buffer[i]);
}
printf("\n");
// 输出预测的值
findMaxAndPosition(buffer, 10);
// 释放
ret = rknn_destroy(ctx);
if (model_data) {
free(model_data);
}
return 0;
}
|
复制配套文件到板卡上,编译源码(配套例程没有适配在PC上交叉编译,有需要可以自行修改CMakeFiles.txt和添加库文件等), 编译使用板卡默认安装的rknn库,如果需要更新库或者添加头文件,参考下前面 《RKNN API》 。
执行命令编译程序:
# 切换到手写数字例程handwritten/c++目录下,然后编译,这里测试是lubancat-4板卡
cat@lubancat:~/lubancat-ai/handwritten/c++$ mkdir build && cd build
cat@lubancat:~/lubancat-ai/handwritten/c++/build$ cmake ../
-- The C compiler identification is GNU 10.2.1
-- The CXX compiler identification is GNU 10.2.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found OpenCV: /usr (found version "4.5.1")
-- Configuring done
-- Generating done
-- Build files have been written to: /home/cat/lubancat-ai/handwritten/c++/build
# 然后执行make命令编译,生成文件handwritten
cat@lubancat:~/lubancat-ai/handwritten/c++/build$ make
Scanning dependencies of target handwritten
[ 50%] Building CXX object CMakeFiles/handwritten.dir/main.cc.o
[100%] Linking CXX executable handwritten
[100%] Built target handwritten
cat@lubancat:~/lubancat-ai/handwritten/c++/build$
执行部署输出(lubancat-4):
# 根据板卡不同,选择不同的模型
cat@lubancat:~/lubancat-ai/handwritten/c++/build$ ./handwritten ../../model/RK3588/handwritten.rknn ../0.jpg
Loading mode ../../model/RK3588/handwritten.rknn ...
sdk version: 1.5.0 (e6fe0c678@2023-05-25T08:09:20) driver version: 0.8.8
model input num: 1, output num: 1
index=0, name=x, n_dims=4, dims=[1, 28, 28, 1], n_elems=784, size=1568, w_stride = 32, size_with_stride=1792, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
index=0, name=linear_2.tmp_1, n_dims=2, dims=[1, 10], n_elems=10, size=20, w_stride = 0, size_with_stride=20, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model is NHWC input fmt
model input height=28, width=28, channel=1
Read ../0.jpg ...
img width = 219, img height = 217
resize with Opencv!
once run use 0.188000 ms
outputs: 8.632812 -0.218262 3.525391 0.385742 -1.869141 -0.399170 1.348633 -0.907715 -1.328125 0.857910
本次预测的数字是: 0