
2. Qwen2-VL¶
Qwen2-VL是一个基于视觉-语言预训练的多模态模型,支持图像和文本的联合输入,输出是文本形式。
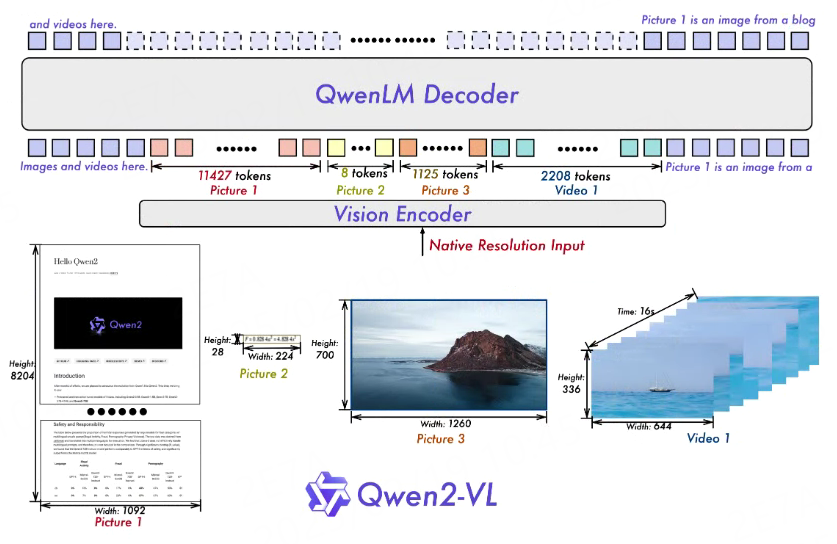
Github地址:https://github.com/QwenLM/Qwen2-VL
将在鲁班猫板卡上部署Qwen2-VL-2B-Instruct模型,对输入图像进行描述。
重要
请注意教程测试RKLLM是 1.2.1 版本,测试lubancat-4板卡。
2.1. Qwen2-VL使用¶
Qwen2-VL系列的2B和7B模型及其量化模型可以在Hugging Face或者ModelScope上找到, 请参考 Qwen/Qwen2-VL-2B-Instruct 。
接下来将使用HF Transformers参考 Qwen/Qwen2-VL-2B-Instruct Model Card中的描述测试Qwen2-VL。 安装测试环境:
# 在PC上简单创建一个测试环境
conda create -n qwen2_vl python=3.10
conda activate qwen2_vl
# 自行安装transformers和torch
(qwen2_vl) llh@llh:/xxx$ pip install transformers torch torchvision
# 安装qwen-vl-utils 工具包(可选)
(qwen2_vl) llh@llh:/xxx$ pip install qwen-vl-utils
拉取模型文件:
# 安装git-lfs
git lfs install
# sudo apt update && sudo apt install git-lfs
# 获取Qwen2-VL-2B-Instruct模型文件
git clone https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct
# 从镜像网址获取(可选)
git clone https://hf-mirror.com/Qwen/Qwen2-VL-2B-Instruct
# 或者获取Qwen2-VL-7B-Instruct模型文件
git clone https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
# 从镜像网址获取(可选)
git clone https://hf-mirror.com/Qwen/Qwen2-VL-7B-Instruct
测试程序,可以自行修改图像路径等等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | from PIL import Image
import requests
import torch
from torchvision import io
from typing import Dict
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
# Load the model in half-precision on the available device(s)
path = "path/to/Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(
path, torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(path)
# Image
#url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
#image = Image.open(requests.get(url, stream=True).raw)
image = Image.open('./data/demo.jpg')
conversation = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": "描述这幅图像"},
],
}
]
# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>
# Describe this image.<|im_end|>\n<|im_start|>assistant\n'
inputs = processor(
text=[text_prompt], images=[image], padding=True, return_tensors="pt"
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
output_text = processor.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
print(output_text)
|
执行程序,将输出对图像的文本描述:
# 修改程序中模型的路径为前面拉取模型文件的路径
(qwen2_vl) llh@llh:/xxx$ python infer.py
Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'mrope_section'}
`Qwen2VLRotaryEmbedding` can now be fully parameterized by passing the model config through the `config` argument. All other arguments will be removed in v4.46
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████| 2/2 [01:16<00:00, 38.45s/it]
['这幅图像描绘了一位宇航员在月球表面休息的场景。宇航员穿着白色的宇航服,坐在一个绿色的冷藏箱旁边,手里拿着一瓶绿色的啤酒。
背景中可以看到地球和星空,显示出宇航员在月球上的孤独和宁静。
月球表面的岩石和沙子,以及远处的地球,都清晰可见。整体画面充满了科幻和探索的氛围。']
2.2. 模型转换¶
Qwen2-VL模型是ViT加Qwen2的串联结构,为了部署模型,将模型分成两部分。 模型转换程序参考 rknn-llm 工程文件中的例程。
2.2.1. 导出vision的onnx模型¶
# 获取rknn-llm 例程
git clone https://github.com/airockchip/rknn-llm
# 切换到example目录下
cd rknn-llm/examples/Qwen2-VL-2B_Demo
# 修改export/export_vision.py 中模型默认路径,或者下面指定--path参数
argparse.add_argument('--path', type=str, default='/xxx/models/Qwen2-VL-2B-Instruct', help='model path', required=False)
# 第一步:生成相关文件,根据实际需要设置batch,height和width
(tansformer) llh@llh:/xxx/Qwen2-VL-Instruct$ python export/export_vision.py --step 1 --batch 1 --height 392 --width 392
The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored.
`Qwen2VLRotaryEmbedding` can now be fully parameterized by passing the model config through the `config` argument.
All other arguments will be removed in v4.46
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████| 2/2 [00:08<00:00, 4.30s/it]
==========================================================
Generating the rotary_pos_emb and cu_seqlens done.
# 第二步:生成onnx模型,设置savepath参数指定保存路径和名称,其他的参数和前面一步系统
(tansformer) llh@llh:/xxx/rkllm/Qwen2-VL-Instruct$ python export/export_vision.py --step 0 --savepath ./onnx/qwen2-vl-vision.onnx \
--batch 1 --height 392 --width 392
The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored.
`Qwen2VLRotaryEmbedding` can now be fully parameterized by passing the model config through the `config` argument.
All other arguments will be removed in v4.46
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████| 2/2 [00:08<00:00, 4.14s/it]
==========================================================
Exporting the vision part of /xxx/Qwen2-VL-2B-Instruct to onnx format.
#省略......
会在指定的目录下生成qwen2-vl-vision.onnx文件,以及权重文件。
2.2.2. 将vision模型转换成rknn模型¶
将前面生成的qwen2-vl-vision.onnx文件经过Toolkit2工具导出rknn模型, rknn-Toolkit2环境安装参考下前面 Toolkit2章节 。
# 教程测试lubancat-4,如果是鲁班猫3需要修改target_platform = rk3576和模型路径model_path
(toolkit2_2.3)llh@llh:/xxx$ python export/export_vision_rknn.py --path /xxx/qwen2-vl-vision.onnx --target-platform rk3588
I rknn-toolkit2 version: 2.3.2
# 省略..............
I Loading : 100%|█████████████████████████████████████████████████| 551/551 [00:11<00:00, 49.71it/s]
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 123.51it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:03<00:00, 26.07it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:12<00:00, 7.78it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:13<00:00, 7.56it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:13<00:00, 7.32it/s]
I OpFusing 0 : 100%|██████████████████████████████████████████████| 100/100 [00:24<00:00, 4.16it/s]
I OpFusing 1 : 100%|██████████████████████████████████████████████| 100/100 [00:24<00:00, 4.09it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:50<00:00, 1.97it/s]
I Saving : 100%|██████████████████████████████████████████████████| 327/327 [00:20<00:00, 15.84it/s]
I rknn building ...
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x5048, shift = 19, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 0, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 16, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x5048, shift = 19, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 0, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 16, limit: 0x1fff, value: 0x2b18
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x5048, shift = 19, limit: 0x1fff, value: 0x3fe0
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 0, limit: 0x1fff, value: 0x3fe0
E RKNN: [12:00:44.324] REGTASK: The bit width of field value exceeds the limit, target: v2, offset: 0x4038, shift = 16, limit: 0x1fff, value: 0x3fe0
E RKNN: [12:00:53.018] Unkown op target: 0
E RKNN: [12:00:53.019] Unkown op target: 0
I rknn building done.
将会在rknn目录下生成qwen2_vl_2b_vision_rk3588.rknn文件。
2.2.3. 导出rkllm模型¶
使用rkllm-toolkit工具导出rkllm模型,rkllm环境安装参考下 前面 RKLLM章节 或者查看 Rockchip_RKLLM_SDK_CN_xxx.pdf 文档。
先对原始数据进行处理,将原始的json格式转化为模型接受的形式,作为量化数据。
# 如果不想使用量化数据,后面模型导出步骤中需要修改rkllm.build函数的参数,删除dataset=dataset
# 如果有GPU请设置GPU
# 修改path为前面拉取Qwen2-VL-2B-Instruct模型文件的路径,不然会自动下载模型
(rkllm1.2.1) llh@llh:/xxx/Qwen2-VL-Instruct$ python data/make_input_embeds_for_quantize.py --path /xxx/models/Qwen2-VL-2B-Instruct
Loading checkpoint shards: 100%|███████████████████████████████████████| 2/2 [00:00<00:00, 4.60it/s]
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model.
`use_fast=True` will be the default behavior in v4.52,
even if the model was saved with a slow processor. This will result in minor differences in outputs.
You'll still be able to use a slow processor with `use_fast=False`.
inputs_embeds torch.Size([1, 242, 1536])
inputs_embeds torch.Size([1, 249, 1536])
inputs_embeds torch.Size([1, 318, 1536])
inputs_embeds torch.Size([1, 279, 1536])
inputs_embeds torch.Size([1, 334, 1536])
inputs_embeds torch.Size([1, 354, 1536])
inputs_embeds torch.Size([1, 130, 1536])
inputs_embeds torch.Size([1, 123, 1536])
inputs_embeds torch.Size([1, 346, 1536])
inputs_embeds torch.Size([1, 238, 1536])
inputs_embeds torch.Size([1, 181, 1536])
inputs_embeds torch.Size([1, 181, 1536])
inputs_embeds torch.Size([1, 265, 1536])
inputs_embeds torch.Size([1, 265, 1536])
inputs_embeds torch.Size([1, 226, 1536])
inputs_embeds torch.Size([1, 227, 1536])
inputs_embeds torch.Size([1, 280, 1536])
inputs_embeds torch.Size([1, 300, 1536])
inputs_embeds torch.Size([1, 334, 1536])
inputs_embeds torch.Size([1, 386, 1536])
100%|████████████████████████████████████████████████| 20/20 [00:08<00:00, 2.47it/s]
Done
导出rkllm模型,注意自行修改模型的路径和目标平台等参数,默认是rk3588(lubancat-4/5系列板卡)。
# 修改模型路径和llm.build的target_platform='rk3588'和quantized_dtype='w8a8'
# 如果使用空的量化数据集,就删除export/export_rkllm.py程序中的 “dataset=dataset”
# 执行程序加载模型导出rkllm模型
(rkllm1.2.1) llh@llh:/mnt/e/work/rkllm/Qwen2-VL-Instruct$ python export/export_rkllm.py --path /xxx/Qwen2-VL-2B-Instruct \
--target-platform rk3588 --num_npu_core 3 --quantized_dtype w8a8 --device cpu --savepath ./rknn/qwen2-vl-llm_rk3588.rkllm
INFO: rkllm-toolkit version: 1.2.1
Sliding Window Attention is enabled but not implemented for `eager`; unexpected results may be encountered.
WARNING: rkllm-toolkit only exports Qwen2ForCausalLM of Qwen2VLForConditionalGeneration!
Building model: 100%|███████████████████████████████████████████████████████████████████████████████████| 371/371 [00:08<00:00, 45.18it/s]
Downloading data files: 100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 823.54it/s]
Extracting data files: 100%|████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 102.33it/s]
Generating train split: 20 examples [00:02, 8.29 examples/s]
Optimizing model: 100%|███████████████████████████████████████████████████████████████████| 28/28 [24:18<00:00, 52.10s/it]
INFO: Setting chat_template to "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n[content]<|im_end|>\n<|im_start|>assistant\n"
INFO: Setting token_id of eos to 151645
INFO: Setting token_id of pad to 151643
INFO: Setting token_id of bos to 151643
Converting model: 100%|████████████████████████████████████████████████████████████████| 339/339 [00:00<00:00, 2039984.30it/s]
INFO: Setting max_context_limit to 4096
INFO: Exporting the model, please wait ....
[=================================================>] 597/597 (100%)
INFO: Model has been saved to ./rknn/qwen2-vl-llm_rk3588.rkllm!
会在指定的目录下生成qwen2-vl-llm_rk3588.rkllm文件。
2.3. 部署测试¶
板卡上获取rkllm工程文件:
sudo apt update
sudo apt install cmake gcc g++ make
# 板卡上获取测试例程(教程测试lubancat-4)
git clone https://github.com/airockchip/rknn-llm
# 切换到例程目录
cd rknn-llm/examples/Qwen2-VL-2B_Demo/deploy
本地编译脚本,修改编译器为板卡默认编译器:
# 本地编译,改build-linux.sh中编译器
GCC_COMPILER=aarch64-linux-gnu
板卡上编译测试例程:
cat@lubancat:~/xxx/examples/Qwen2-VL_Demo/deploy$ ./build-linux.sh
-- The C compiler identification is GNU 13.3.0
-- The CXX compiler identification is GNU 13.3.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
# 省略..............
-- Build files have been written to: /home/cat/rkllm/rknn-llm/examples/Qwen2-VL_Demo/deploy/build
[ 12%] Building CXX object CMakeFiles/llm.dir/src/llm.cpp.o
[ 75%] Built target llm
[ 87%] Linking CXX executable imgenc
[100%] Linking CXX executable demo
[100%] Built target imgenc
[100%] Built target demo
[ 37%] Built target imgenc
[ 62%] Built target llm
[100%] Built target demo
# 省略..............
-- Installing: /home/cat/rkllm/rknn-llm/examples/Qwen2-VL_Demo/deploy/install/demo_Linux_aarch64/./demo.jpg
切换到install/demo_Linux_aarch64/目录下执行程序demo例程,用户输入“<image>请描述图像”,例程将对下面的测试图像进行描述:

# 将前面导出的qwen2_vl_2b_vision_rk3588.rknn和qwen2-vl-llm_rk3588.rkllm模型传输到板卡
# 执行demo程序, 设置qwen2_vl_2b_vision_rk3588.rknn和qwen2-vl-llm_rk3588.rkllm的模型路径
# Usage: ./demo image_path encoder_model_path llm_model_path max_new_tokens max_context_len
cat@lubancat:~/xxx/install/demo_Linux_aarch64$ export LD_LIBRARY_PATH=./lib
cat@lubancat:~/xxx/install/demo_Linux_aarch64$ ./demo demo.jpg ~/qwen2-vl-vision_rk3588.rknn \
~/qwen2-vl-llm_rk3588.rkllm 128 512 3
I rkllm: rkllm-runtime version: 1.2.1, rknpu driver version: 0.9.8, platform: RK3588
I rkllm: loading rkllm model from /home/cat/qwen2-vl-llm_rk3588.rkllm
I rkllm: rkllm-toolkit version: 1.2.1, max_context_limit: 4096, npu_core_num: 3, target_platform: RK3588, model_dtype: W8A8
I rkllm: Enabled cpus: [4, 5, 6, 7]
I rkllm: Enabled cpus num: 4
I rkllm: Using mrope
rkllm init success
main: LLM Model loaded in 2293.79 ms
===the core num is 3===
model input num: 1, output num: 1
input tensors:
index=0, name=onnx::Expand_0, n_dims=4, dims=[1, 392, 392, 3], n_elems=460992, size=921984, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=6460, n_dims=2, dims=[196, 1536, 0, 0], n_elems=301056, size=602112, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model input height=392, width=392, channel=3
main: ImgEnc Model loaded in 2228.01 ms
I rkllm: reset chat template:
I rkllm: system_prompt: <|im_start|>system\nYou are a helpful assistant.<|im_end|>\n
I rkllm: prompt_prefix: <|im_start|>user\n
I rkllm: prompt_postfix: <|im_end|>\n<|im_start|>assistant\n
W rkllm: Calling rkllm_set_chat_template will disable the internal automatic chat template parsing, including enable_thinking.
Make sure your custom prompt is complete and valid.
**********************可输入以下问题对应序号获取回答/或自定义输入********************
[0] <image>What is in the image?
[1] <image>这张图片中有什么?
*************************************************************************
user: <image>请描述这张图像
robot: 这是一张科幻风格的图片,描绘了一名宇航员在月球表面休息的情景。宇航员穿着白色的太空服,
戴着头盔,手里拿着一瓶绿色的啤酒,似乎正在享受这一刻。背景是广阔的月球景观,可以看到地球和其他星星。
月球表面看起来荒凉而干燥,远处有一座孤独的建筑或结构。整体画面充满了未来感和神秘感。