
15. YOLO26¶
Ultralytics YOLO26 是YOLO系列实时目标检测器的最新版本, 专为边缘和低功耗设备而设计 。 它采用流线型设计,去除了不必要的复杂性,同时融入了有针对性的创新,实现了更快、更轻量、更易于部署的部署方案。
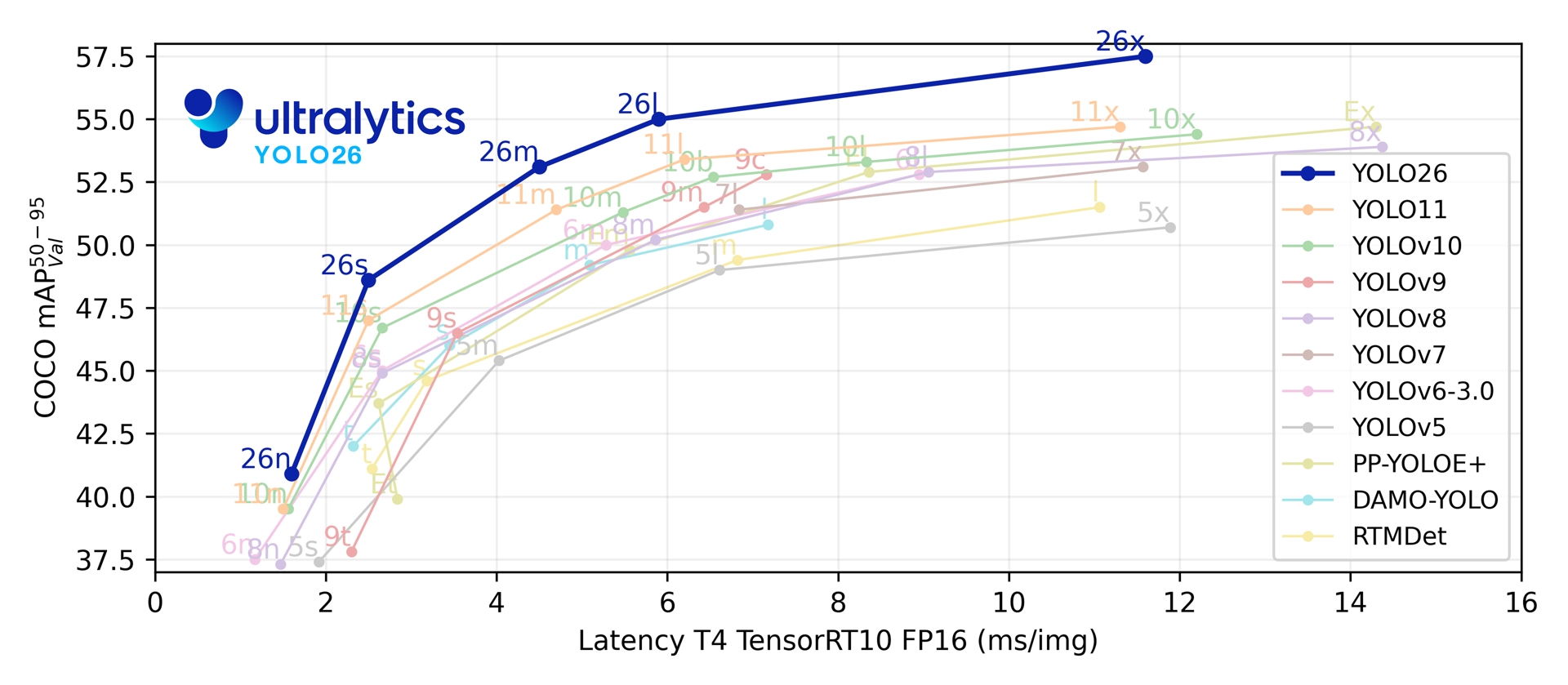
YOLO26的特点:
端到端的无NMS推理和去除DFL模块 移除DFL,无NMS推理,大幅简化部署流程、降低延迟,提升系统稳定性,拓宽了对边缘和低功耗设备的支持。
支持多任务统一架构 支持分类、检测、分割、姿态估计、旋转框检测五大任务,极大简化开发与维护成本。
训练优化: 引入了MuSGD优化器,该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。
任务特定优化: 实例分割中引入语义分割损失以改善模型收敛,以及升级的原型模块,该模块利用多尺度信息以获得卓越的掩膜质量。
本章将简单测试YOLO26的 目标检测 、 实例分割 、 姿态检测 、 旋转目标检测 模型,然后在鲁班猫rk系列板卡上部署。
15.1. YOLO26目标检测¶
在个人PC上使用Anaconda创建一个yolo26开发环境,然后简单测试yolo26目标检测。
conda create -n yolo26 python=3.10
conda activate yolo26
# 配置pip源(可选)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装
pip install ultralytics
# 或者从源码安装
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -e .
# 检测版本
(yolo26) llh@llh:/xxx$ yolo version
8.4.2
使用yolo命令或者python程序测试 YOLO26目标检测 。
# 使用yolo命令测试yolo26n.pt模型
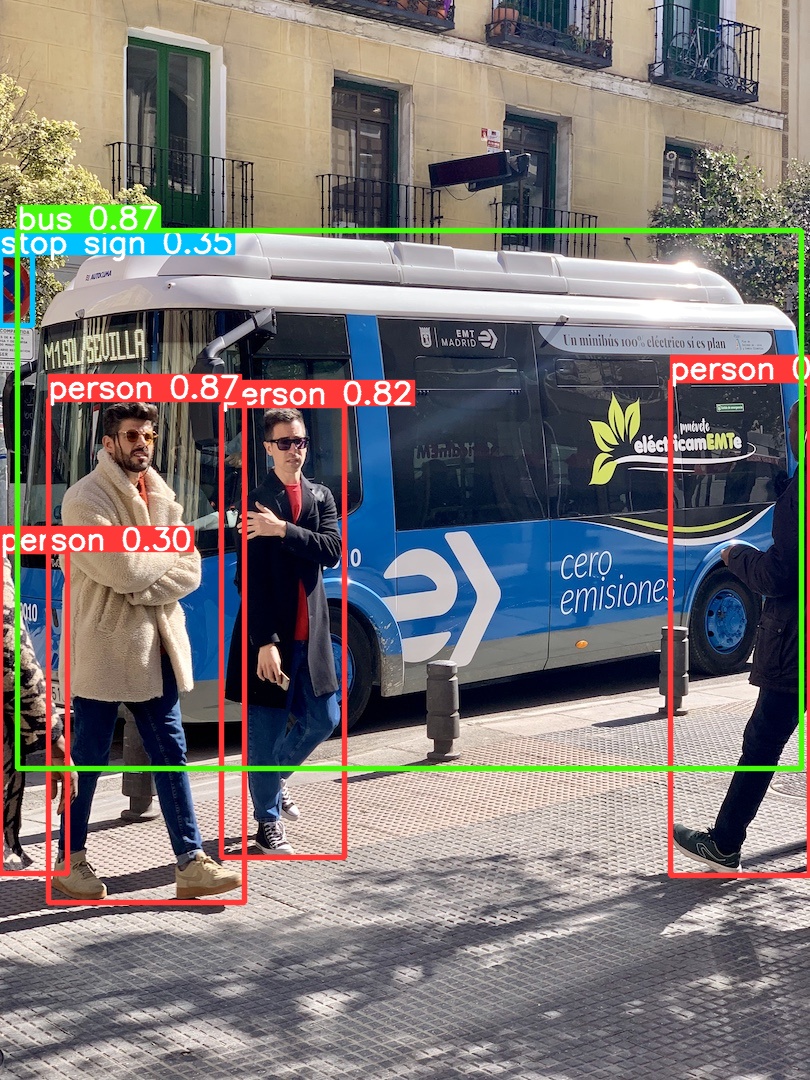
(yolo26) llh@llh:/xxx$ yolo detect predict model=yolo26n.pt source='https://ultralytics.com/images/bus.jpg'
Ultralytics 8.4.2 🚀 Python-3.10.15 torch-2.5.1 CUDA:0 (NVIDIA GeForce RTX 4070 Ti SUPER, 16376MiB)
YOLO26n summary (fused): 122 layers, 2,408,932 parameters, 0 gradients, 5.4 GFLOPs
Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg': 100% ━━━━━━━━━━━━ 134.2KB 931.7KB/s 0.1s
image 1/1 /mnt/e/work/yolo26/bus.jpg: 640x480 4 persons, 1 bus, 68.7ms
Speed: 3.0ms preprocess, 68.7ms inference, 14.0ms postprocess per image at shape (1, 3, 640, 480)
Results saved to /mnt/e/work/yolo26/runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
VS Code: view Ultralytics VS Code Extension ⚡ at https://docs.ultralytics.com/integrations/vscode
将会拉取yolo26n.pt文件,运行推理,结果保存在runs/detect/predict目录下,使用图像查看器查看:
15.1.1. 模型转换¶
1、导出onnx模型
简单修改 Ultralytics YOLO26 模型, 简单修改模型输出结构,便于部署,还可以自行新增置信度的总和,用于后处理阶段加速阈值筛选(需要自行修改后处理程序)。
主要的修改如下(详情请参考 YOLO26 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | class Detect(nn.Module):
# 省略......................
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module = None, cls_head: torch.nn.Module = None
) -> dict[str, torch.Tensor]:
"""Concatenates and returns predicted bounding boxes and class probabilities."""
if box_head is None or cls_head is None: # for fused inference
return dict()
+ if self.export and self.format == "rknn": # for RKNN export
+ z = []
+ for i in range(self.nl):
+ z.append(torch.cat((box_head[i](x[i]), cls_head[i](x[i]).sigmoid()), 1))
+ return z
#if self.export and self.format == "rknn": # for RKNN export
# y = []
# for i in range(self.nl):
# y.append(box_head[i](x[i]))
# cls = torch.sigmoid(cls_head[i](x[i]))
# cls_sum = torch.clamp(cls.sum(1, keepdim=True), 0, 1)
# y.append(cls)
# y.append(cls_sum) # 可选
# return y
bs = x[0].shape[0] # batch size
boxes = torch.cat([box_head[i](x[i]).view(bs, 4 * self.reg_max, -1) for i in range(self.nl)], dim=-1)
scores = torch.cat([cls_head[i](x[i]).view(bs, self.nc, -1) for i in range(self.nl)], dim=-1)
return dict(boxes=boxes, scores=scores, feats=x)
|
# 获取修改过后的程序
git clone https://github.com/mmontol/ultralytics.git
# 修改./ultralytics/cfg/default.yaml 中model文件路径,默认为yolo26n.pt,若自己训练模型,请调接至对应的路径。支持检测、分割、姿态、旋转框检测模型。
# 导出onnx模型
export PYTHONPATH=./
python ./ultralytics/engine/exporter.py
Downloading https://github.com/ultralytics/assets/releases/download/v8.4.0/yolo26n.pt to 'x/yolo26/yolo26n.pt': 100% ━━━━━━━━━━━━ 5.3MB 746.5KB/s 7.3s
Ultralytics 8.4.2 🚀 Python-3.11.11 torch-2.4.0+cu121 CPU (Intel Core(TM) i7-14700F)
WARNING ⚠️ Rockchip RKNN export requires a missing 'name' arg for processor type. Using default name='rk3588'.
YOLO26n summary (fused): 122 layers, 2,408,932 parameters, 0 gradients
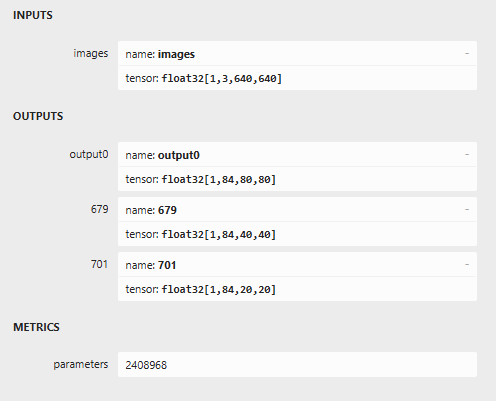
PyTorch: starting from 'x/yolo26/yolo26n.pt' with input shape (16, 3, 640, 640)
BCHW and output shape(s) ((16, 84, 80, 80), (16, 84, 40, 40), (16, 84, 20, 20)) (5.3 MB)
RKNN: starting export with onnx 1.17.0 opset 19...
RKNN: export success ✅ 0.5s, saved as 'x/yolo26/yolo26n.onnx' (9.3 MB)
Export complete (1.9s)
Results saved to x/yolo26
Predict: yolo predict task=detect model=x/yolo26/yolo26n.onnx imgsz=640
Validate: yolo val task=detect model=x/yolo26/yolo26n.onnx imgsz=640 data=/home/lq/codes/ultralytics/ultralytics/cfg/datasets/coco.yaml
Visualize: https://netron.app
导出的onnx模型会在同目录下,使用 netron 查看其模型输入输出:
2、转成rknn模型
使用toolkit2工具,将onnx模型转换成rknn模型:
Usage: python3 onnx2rknn.py onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]
platform choose from [rk3562,rk3566,rk3568,rk3588,rk3576,rk1808,rv1109,rv1126]
dtype choose from [i8, fp] for [rk3562,rk3566,rk3568,rk3588,rk3576]
dtype choose from [u8, fp] for [rk1808,rv1109,rv1126]
# 测试鲁班猫rv1106,设置rv1106,rv1106目前只支持yolo26量化模型
# 例如: python onnx2rknn.py ./yolo26n.onnx rv1106 i8 ./yolo26n-rv1106.rknn
# 测试鲁班猫4,设置参数rk3588,并且使用默认量化数据
(toolkit2.3.2) llh@llh:/xxx/yolo11$ python onnx2rknn.py ./yolo26n.onnx rk3588 i8 ./yolo26_i8.rknn
I rknn-toolkit2 version: 2.3.2
--> Config model
done
--> Loading model
I Loading : 100%|██████████████████████████████████████████████| 204/204 [00:00<00:00, 76649.47it/s]
done
--> Building model
I OpFusing 0: 100%|██████████████████████████████████████████████| 100/100 [00:00<00:00, 610.01it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 352.66it/s]
I OpFusing 0 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 157.82it/s]
I OpFusing 1 : 100%|█████████████████████████████████████████████| 100/100 [00:00<00:00, 152.51it/s]
I OpFusing 2 : 100%|██████████████████████████████████████████████| 100/100 [00:01<00:00, 92.92it/s]
W build: found outlier value, this may affect quantization accuracy
const name abs_mean abs_std outlier value
model.2.m.0.cv2.conv.weight 1.90 2.51 -29.822
model.23.one2one_cv3.1.1.0.conv.weight 0.33 0.71 14.041
model.23.one2one_cv3.1.1.1.conv.weight 0.23 0.33 -9.717
model.23.one2one_cv3.0.1.0.conv.weight 0.65 1.21 -12.786
model.23.one2one_cv3.0.1.1.conv.weight 0.21 0.28 -9.696
I GraphPreparing : 100%|███████████████████████████████████████| 261/261 [00:00<00:00, 15191.90it/s]
I Quantizating : 100%|████████████████████████████████████████████| 261/261 [00:06<00:00, 40.94it/s]
# 省略。。
I rknn building ...
I rknn building done.
done
--> Export rknn model
done
rknn保存在当前目录下,文件名为yolo26_i8.rknn(执行导出命令时可以自行修改名称)。
15.1.2. 模型部署¶
yolo26目标检测模型部署流程(yolo26n):
读取原始图像 → 模型初始化 → 预处理 → NPU推理 → 后处理 → 绘制和保存结果
读取原始图像:可以使用OpenCV或者其他库读取图像
模型初始化:读取rknn模型文件,使用rknn_init函数初始化
预处理:使用RGA或者CPU对图像进行缩放(保持长宽比的缩放),注意数据排布(NHWC),然后设置模型输入(在模型转换时设置了图像的归一化和均值)
NPU推理:模型输入图像,模型输出三个tensor(或者六个), 3个尺度(cls + box,cls_sum),box是框坐标和cls是80个类别的置信度,cls_sum是新增置信度的总和(可选)
后处理:获取模型输出,对3个尺度(80×80, 40×40, 20×20)分别处理后合并,筛选出分数高的框,框坐标转换成原始图像的坐标
绘制和保存结果:在原图像上绘制类别名和置信度,并保存结果。
1、测试鲁班猫4板卡
鲁班猫1/2/3/4/5板卡直接在板卡系统中编译, 板卡系统中获取配套例程,然后将前面转换出的rknn模型放到例程model目录下。
# 板卡上安装相关软件
sudo apt update
sudo apt install libopencv-dev git make gcc g++ libsndfile1-dev
# 鲁班猫系统中,使用命令直接拉取教程配套例程
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
# 切换到例程目录
cd lubancat_ai_manual_code/example/yolo26/cpp
# 在lubancat4板卡(rk3588s)上编译,设置rk3588,,如果是鲁班猫3,请设置rk3576。
cat@lubancat:/xxx/example/yolo26/cpp$ ./build-linux.sh -t rk3588
./build-linux.sh -t rk3588
===================================
TARGET_SOC=rk3588
INSTALL_DIR=/home/cat/lubancat_ai_manual_code/example/yolo26/cpp/install/rk3588_linux
BUILD_DIR=/home/cat/lubancat_ai_manual_code/example/yolo26/cpp/build/build_rk3588_linux
ENABLE_DMA32=OFF
DISABLE_RGA=OFF
BUILD_TYPE=Release
ENABLE_ASAN=OFF
CC=aarch64-linux-gnu-gcc
CXX=aarch64-linux-gnu-g++
# 省略.....
[ 8%] Built target imageutils
[ 16%] Built target fileutils
[ 25%] Built target imagedrawing
[ 41%] Built target yolo26_det_demo
[ 58%] Built target yolo26_seg_demo
[ 75%] Built target yolo26_pose_demo
[ 91%] Built target yolo26_obb_demo
[100%] Built target audioutils
Install the project...
# 省略.....
在install/rk3588_linux目录下将生成yolo26_det_demo可执行文件 (其他yolo26系列模型部署类似),执行程序:
# 测试lubancat-4 固定cpu,npu频率
# 命令使用 ./yolo26_det_demo <model_path> <image_path>
cat@lubancat:~/xxx/cpp/install/rk3588_linux$ ./yolo26_det_demo ./model/yolo26n_i8.rknn ./model/bus.jpg
model input num: 1, output num: 3
input tensors:
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
output tensors:
index=0, name=output0, n_dims=4, dims=[1, 84, 80, 80], n_elems=537600, size=537600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-109, scale=0.034189
index=1, name=631, n_dims=4, dims=[1, 84, 40, 40], n_elems=134400, size=134400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-126, scale=0.056458
index=2, name=653, n_dims=4, dims=[1, 84, 20, 20], n_elems=33600, size=33600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.072688
model is NHWC input fmt
model input height=640, width=640, channel=3
-- init_yolo26_model use: 22.298000 ms
origin size=810x1080 crop size=800x1072
input image: 810 x 1080, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
-- read_image use: 6.429000 ms
scale=0.592593 dst_box=(80 0 559 639) allow_slight_change=1 _left_offset=80 _top_offset=0 padding_w=160 padding_h=0
src width is not 4/16-aligned, convert image use cpu
-- preprocess use: 8.822000 ms
-- rknn inference use: 22.840000 ms
-- get output and postprocess use: 1.628000 ms
person @ (0 550 64 872) 0.452
bus @ (3 231 803 757) 0.945
person @ (221 405 345 864) 0.872
person @ (47 399 236 901) 0.872
person @ (668 394 810 877) 0.872
write_image path: out.png width=810 height=1080 channel=3 data=0xaaaaf7f63860
保存结果图片为out.png,使用图像编辑器查看:

2、测试鲁班猫rv1106板卡(目前支持yolo26目标检测模型)
测试rv1106,使用交叉编译器编译程序。
# 获取交叉编译器armhf-uclibcgnueabihf,从配套网盘或者 https://console.zbox.filez.com/l/H1fV9a (rknn)
# 解压交叉编译文件到/opt目录下
# 获取配套程序
git clone https://gitee.com/LubanCat/lubancat_ai_manual_code
cd lubancat_ai_manual_code/example/yolo26/cpp
# 设置交叉编译器,请根据实际目录修改路径
export GCC_COMPILER=/opt/arm-rockchip830-linux-uclibcgnueabihf/bin/arm-rockchip830-linux-uclibcgnueabihf
# 然后交叉编译程序
./build-linux.sh -t rv1106
执行程序,需要将install/rv1106_linux目录下文件传输到板卡, 以及前面转换的rknn模型也传输到板卡,然后自行命令:
# 修改可执行权限
chmod +x yolo26_det_demo
# ./yolo26_det_demo ./yolo26n-rv1106.rknn ./model/bus.jpg
model input num: 1, output num: 3
input tensors:
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
output tensors:
index=0, name=output0, n_dims=4, dims=[1, 80, 80, 84], n_elems=537600, size=537600, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-109, scale=0.034189
index=1, name=679, n_dims=4, dims=[1, 40, 40, 84], n_elems=134400, size=134400, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-126, scale=0.056458
index=2, name=701, n_dims=4, dims=[1, 20, 20, 84], n_elems=33600, size=33600, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.072688
input_attrs[0].size_with_stride=1228800
model is NHWC input fmt
model input height=640, width=640, channel=3
-- init_yolo26_model use: 35.332001 ms
origin size=640x640 crop size=640x640
input image: 640 x 640, subsampling: 4:2:0, colorspace: YCbCr, orientation: 1
-- read_image use: 27.007999 ms
scale=1.000000 dst_box=(0 0 639 639) allow_slight_change=1 _left_offset=0 _top_offset=0 padding_w=0 padding_h=0
rga_api version 1.10.1_[0]
rknn_run
-- inference_yolo26_model use: 133.729996 ms
person @ (79 327 119 517) 0.395
bus @ (84 135 556 449) 0.945
person @ (211 240 285 512) 0.872
person @ (108 237 224 534) 0.872
person @ (476 234 560 520) 0.800
write_image path: out.png width=640 height=640 channel=3 data=0xa6168000
-- draw boxs use: 733.934998 ms