
飞桨(PaddlePaddle) FastDeploy¶
FastDeploy介绍¶
FastDeploy 是一款全场景、易用灵活、极致高效的AI推理部署工具。 提供超过160+ Text,Vision, Speech和跨模态模型开箱即用的部署体验,并实现端到端的推理性能优化。 包括 物体检测、字符识别(OCR)、人脸、人像扣图、多目标跟踪系统、NLP、Stable Diffusion文图生成、TTS 等几十种任务场景,满足开发者多场景、多硬件、多平台的产业部署需求。
FastDeploy旨在为AI开发者提供模型部署最优解,具备全场景、简单易用、极致高效三大特点。
全场景:支持 GPU、CPU、Jetson、ARM CPU、瑞芯微NPU、晶晨NPU、恩智浦NPU 等多类硬件,支持本地部署、服务化部署、Web端部署、移动端部署等,支持CV、NLP、Speech 三大领域, 支持图像分类、图像分割、语义分割、物体检测、字符识别(OCR)、人脸检测识别、人像扣图、姿态估计、文本分类、信息抽取、行人跟踪、语音合成等16大主流算法场景。
易用灵活:3行代码完成AI模型的部署,1行代码快速切换后端推理引擎和部署硬件,统一API实现不同部署场景的零成本迁移。
极致高效:相比传统深度学习推理引擎只关注模型的推理时间,FastDeploy则关注模型任务的端到端部署性能。通过高性能前后处理、整合高性能推理引擎、一键自动压缩等技术, 实现了AI模型推理部署的极致性能优化。
接下来我们将简单搭建下FastDeploy环境,在RK356X/RK3588上部署轻量检测网络PicoDet。
提示
教程测试环境:lubancat-0/1/2使用Debian10,lubancat-4使用Debian11,PC端是WSL2(ubuntu20.04)
PC端模型转换推理环境搭建¶
1、安装FastDeploy等环境
需要安装rknn-Toolkit2和FastDeploy工具,用于模型转换等。创建一个虚拟环境:
# 使用conda创建一个名为FastDeploy的环境,并指定python版本
conda create -n FastDeploy python=3.8
# 进入环境
conda activate FastDeploy
然后安装fastdeploy等工具:
# 直接用预编译库安装,也可以FastDeploy编译安装
# 详细参考下:
pip3 install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
# 安装paddle2onnx
pip3 install paddle2onnx
# 安装paddlepaddle
python -m pip3 install paddlepaddle==0.0.0 -f https://www.paddlepaddle.org.cn/whl/linux/cpu-mkl/develop.html
paddlepaddle安装详细参考下 这里 。
2、安装rknn-Toolkit2
使用paddlepaddle训练保存的Paddle模型,在板卡上部署rknn模型,目前需要先转换成onnx,然后转成rknn模型。模型转换使用rknn-Toolkit2工具, 该工具安装参考下前面章节 《RKNN Toolkit2介绍》
板端FastDeploy RKNPU2推理环境搭建¶
使用FastDeploy,可以在板卡上快速部署模型,提供有Python和C++ SDK,请根据实际部署需要选择。
编译安装Fastdeploy SDK¶
在rk系列鲁班猫板卡,FastDeploy支持ONNX Runtime和RKNPU2后端后端引擎,具体如下 ( 具体请参考 这里 ):
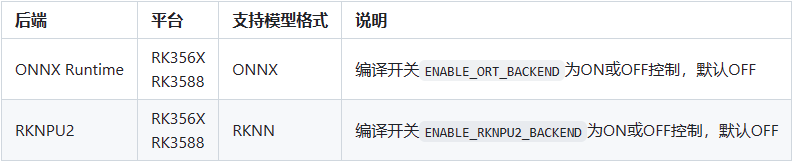
接下来介绍下如何编译FastDeploy Python SDK 和 C++ SDK, 由于板卡性能和资源,编译FastDeploy SDK可能会编译很慢,出现内存不足等情况。
如果需要直接使用(建议自行编译最新的Fastdeploy SDK),我们有提供编译好的安装文件和相关源码,
参考下 云盘资料 (提取码hslu),在 鲁班猫->1-野火开源图书...->AI教程相关源文件 目录中。
1、编译Fastdeploy Python SDK
Python SDK的编译暂时仅支持板端编译, 下面是测试在LubanCat-0/1/2(debian10 python3.7),lubancat-4(Debian11,python3.9.2), 获取SDK源码是develop分支,如果编译遇到问题不能解决,建议使用稳定版本。
# 安装相关软件库等
sudo apt update
sudo apt install -y git cmake python3-dev
# 如果是debian10系统,可以链接,更新下pip
sudo ln -sf /usr/bin/pip3 /usr/bin/pip
pip install --upgrade pip
# git获取源码,默认是develop分支,或者从网盘获取SDK压缩包,目前建议使用稳定版本,切换到其他1.0.7分支等
git clone https://github.com/PaddlePaddle/FastDeploy.git
设置环境变量,编译SDK:
# 设置环境变量
export ENABLE_ORT_BACKEND=ON # 是否编译集成ONNX Runtime后端,ON打开,OFF关闭
export ENABLE_RKNPU2_BACKEND=ON # 使用rknpu2作为后端引擎
export ENABLE_VISION=ON # 是否编译集成视觉模型的部署模块
export RKNN2_TARGET_SOC=RK356X # lubancat-4选择RK3588(一般指rk3588、rk3588s),lubancat-0/1/2选择RK356X(一般指rk3566、rk3568)
# 切换到SDK源码的FastDeploy/python目录下
cd FastDeploy/python
# 编译,打包
python3 setup.py build
python3 setup.py bdist_wheel
提示
rk356X板卡编译时卡死,可能内存不够,建议加下swap交换分区(linux如何添加交换分区,请网上搜索下),至少4G交换空间,板端编译较慢需要等待下。
安装SDK:
# 安装
cd dist
pip3 install fastdeploy_python-0.0.0-cp37-cp37m-linux_aarch64.whl
如果限于板卡资源和性能,可以直接从云盘资料的whl文件,然后使用pip3安装,如果安装遇到问题,可以参考下前面编译过程安装的环境。
2、编译Fastdeploy C++ SDK
Fastdeploy C++ SDK支持板端编译和交叉编译,板卡内存充足建议直接在板卡上编译, 编译可以参考下 这里 。 这里演示下在板卡上编译:
# 获取Fastdeploy源码,如果前面获取了则不需要,也可以从网盘资料获取...
git clone https://github.com/PaddlePaddle/FastDeploy.git
# 切换到源码目录下
cd FastDeploy
# 创建一个编译目录,并切换到该目录下,执行cmake配置
mkdir build && cd build
cmake .. -DENABLE_ORT_BACKEND=ON \
-DENABLE_RKNPU2_BACKEND=ON \
-DENABLE_VISION=ON \
-DRKNN2_TARGET_SOC=RK356X \
-DCMAKE_INSTALL_PREFIX=${PWD}/fastdeploy-0.0.0
# ENABLE_ORT_BACKEND 是指定是否编译集成ONNX Runtime后端
# ENABLE_RKNPU2_BACKEND 是指定否编译集成RKNPU2后端
# ENABLE_VISION 指定是否编译集成视觉模型的部署模块
# RKNN2_TARGET_SOC 指定目标设备,输入值为RK3588,RK356X,必须设置
# CMAKE_INSTALL_PREFIX 安装目录
# ORT_DIRECTORY 开启ONNX Runtime后端时,用于指定用户本地的ONNX Runtime库路径;如果不指定,编译过程会自动下载ONNX Runtime库(教程测试下载的版本是1.12.0)
# OPENCV_DIRECTORY 当ENABLE_VISION=ON时,用于指定用户本地的OpenCV库路径;如果不指定,编译过程会自动下载OpenCV库(教程测试下载的版本是3.4.14)
# 编译,安装,如果是RK356X,指定-j4;如果是RK3588,指定-j8
make -j4
make install
# 最后安装在XXX/FastDeploy/build/fastdeploy-0.0.0目录下
cat@lubancat:~/FastDeploy-develop/build/fastdeploy-0.0.0$ ls
FastDeploy.cmake FastDeployConfig.cmake ThirdPartyNotices.txt fastdeploy_init.sh lib summary.cmake utils
FastDeployCSharp.cmake LICENSE VERSION_NUMBER include openmp.cmake third_libs utils.cmake
部署推理示例¶
轻量化检测网络PicoDet¶
PP-PicoDet是轻量级实时移动端目标检测模型,该模型的介绍参考下 这里 。 下面我们将在板卡上使用FastDeploy部署轻量化检测网络PicoDet:
1、模型转换
rknn-Toolkit2暂时不支持Paddle模型直接导出为RKNN模型,需要使用Paddle2ONNX转成onnx模型,然后导出rknn模型。在PC ubunut系统中:
# 启用虚拟环境
# 这里测试直接下载Paddle静态图模型并解压
wget https://paddledet.bj.bcebos.com/deploy/Inference/picodet_s_416_coco_lcnet.tar
tar xvf picodet_s_416_coco_lcnet.tar
# 静态图模型转换onnx模型,
cd tools/rknpu2/picodet_s_416_coco_lcnet/
paddle2onnx --model_dir picodet_s_416_coco_lcnet \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--enable_dev_version True
# 固定shape
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--output_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"
# 最后模型保存在当前目录下picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx
2、导出RKNN模型
切换到获取的FastDeploy源码tools/rknpu2/目录下(或者从配套程序获取模型转换程序),并复制picodet_s_416_coco_lcnet到该目录下。
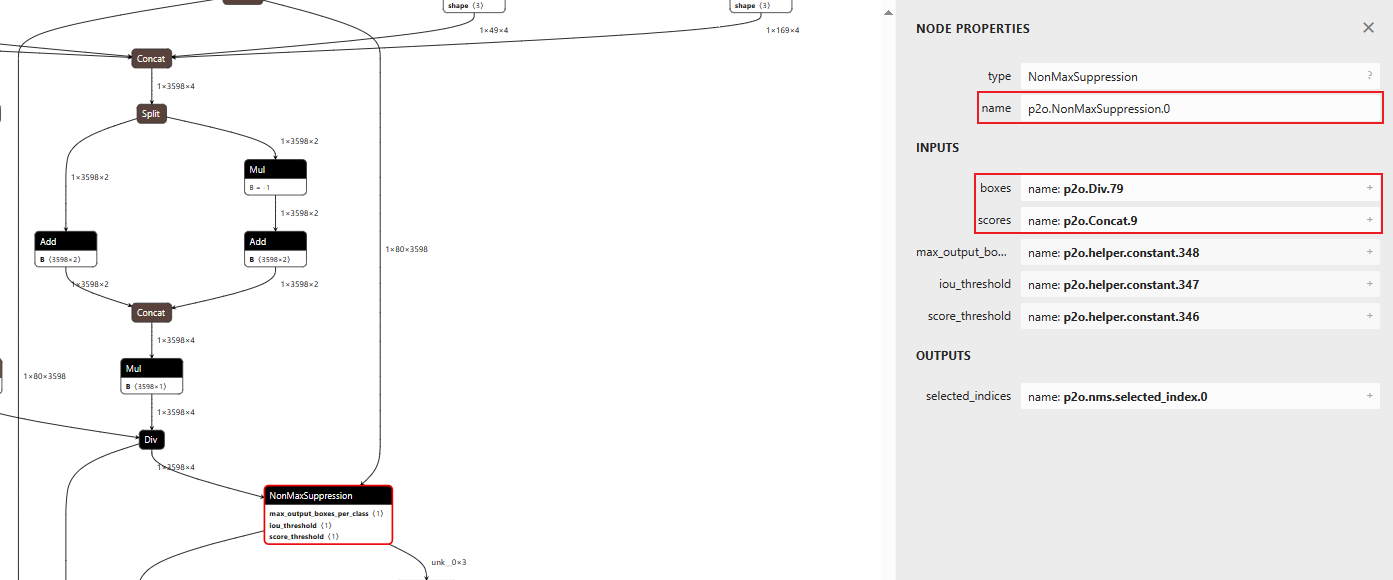
然后修改输出节点,paddle2onnx版本不同,转换模型的输出节点名称可能有所不同,需要使用 Netron 可视化模型, 找到NonMaxSuppression节点,确认输出节点名称,然后修改下config/picodet_s_416_coco_lcnet_unquantized.yaml配置文件中的outputs_nodes参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | mean:
-
- 123.675
- 116.28
- 103.53
std:
-
- 58.395
- 57.12
- 57.375
model_path: ./picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx
outputs_nodes:
- 'p2o.Mul.179'
- 'p2o.Concat.9'
do_quantization: False
dataset:
output_folder: "./picodet_s_416_coco_lcnet"
|
# 环境中可能需要安装的模块
pip install pyyaml
# 切换到获取的FastDeploy源码tools/rknpu2/目录下(或者从配套程序获取模型转换程序),并复制picodet_s_416_coco_lcnet到该目录下
cd tools/rknpu2/
# 按前面可视化模型模型的输出节点,修改config/picodet_s_416_coco_lcnet_unquantized.yaml配置文件
# 导出模型,--config_path 指定配置文件,根据实际tools/rknpu2/config目录下的配置文件设置,--target_platform指定平台,rk3588、rk3566等
python export.py --config_path config/picodet_s_416_coco_lcnet_unquantized.yaml --target_platform rk3568
模型转换的环境中需要安装rknn-Toolkit2(参考下前面 章节 ), rknn模型最后保存在picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet_rk3568_unquantized.rknn 。
板端Python部署推理¶
复制前面转换获取的rknn模型到板卡,然后使用FastDeploy源码中对应的推理程序,进行模型推理测试(测试lubancat-0/1/2板卡,rk356x):
# 部署测试需要python opencv,需要安装下:
pip3 install opencv-python
# 获取FastDeploy源码,前面获取了就不需要,然后切换到推理程序目录下
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/paddledetection/rknpu2/python
# 在板端推理部署,可以使用前面自己导出的rknn模型和配置文件,复制到板卡的推理程序目录下
# 也可以快速测试直接下载模型文件,解压在程序目录下
wget https://bj.bcebos.com/paddlehub/fastdeploy/rknpu2/picodet_s_416_coco_lcnet.zip
unzip picodet_s_416_coco_lcnet.zip
# 获取测试图片
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
# 运行推理程序,--model_file 指定模型文件,--config_file 指定配置文件, --image 指定需要推理的图片
python3 infer.py --model_file ./picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet_rk3568_unquantized.rknn \
--config_file ./picodet_s_416_coco_lcnet/infer_cfg.yml --image 000000014439.jpg
教程测试是lubancat-2(rk3568),指定模文件时需要注意导出模型的平台,运行推理显示:
[INFO] fastdeploy/vision/common/processors/transform.cc(45)::FuseNormalizeCast Normalize and Cast are fused to Normalize in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(81)::GetSDKAndDeviceVersion rknpu2 runtime version: 1.5.1b19 (32afb0e92@2023-07-14T12:46:17)
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(82)::GetSDKAndDeviceVersion rknpu2 driver version: 0.8.2
index=0, name=image, n_dims=4, dims=[1, 416, 416, 3], n_elems=519168, size=1038336, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=0, name=p2o.Mul.179, n_dims=4, dims=[1, 3598, 4, 1], n_elems=14392, size=28784, fmt=NCHW, type=FP32, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=1, name=p2o.Concat.9, n_dims=4, dims=[1, 80, 3598, 1], n_elems=287840, size=575680, fmt=NCHW, type=FP32, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
[INFO] fastdeploy/runtime/runtime.cc(367)::CreateRKNPU2Backend Runtime initialized with Backend::RKNPU2 in Device::RKNPU.
[WARNING] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(420)::InitRKNNTensorMemory The input tensor type != model's inputs type.The input_type need FP16,but inputs[0].type is UINT8
DetectionResult: [xmin, ymin, xmax, ymax, score, label_id]
413.461548,89.649635, 508.461548, 282.605743, 0.833008, 0
160.961548,81.698311, 200.000000, 166.795670, 0.812012, 0
265.576935,79.756004, 299.230774, 167.524033, 0.791992, 0
105.384621,46.251198, 126.730774, 93.534248, 0.769531, 0
584.230774,113.685692, 612.692322, 178.085327, 0.762695, 0
328.269257,40.211838, 344.423096, 80.545067, 0.636719, 0
379.038483,42.093449, 396.153870, 83.397835, 0.554199, 0
510.000031,116.052879, 598.846191, 278.235565, 0.541504, 0
24.038462,116.417061, 55.048080, 153.442307, 0.443115, 0
58.557693,136.325714, 107.115387, 173.836533, 0.428955, 0
352.307709,45.097954, 376.923096, 104.034851, 0.421387, 0
188.750000,45.795971, 200.000000, 61.637917, 0.414551, 0
352.692322,45.097954, 369.615387, 87.343147, 0.388672, 0
360.961548,61.000599, 383.461548, 114.353363, 0.363525, 0
505.000031,114.838936, 556.538452, 269.009613, 0.334717, 0
1.334135,150.286057, 37.091347, 172.622589, 0.400635, 24
58.269234,143.487976, 104.038467, 172.501190, 0.308594, 24
163.076935,87.525238, 600.000000, 344.274017, 0.576660, 33
164.519241,84.975960, 320.000000, 344.516815, 0.389648, 33
Visualized result save in ./visualized_result.jpg
简单测试结果显示:

板端C++部署推理¶
复制前面转换获取的rknn模型到板卡,进行模型推理测试,C++部署推理程序同样在FastDeploy源码中, 在源码根目录examples/vision/detection/paddledetection/rknpu2/cpp下,也可以从配套例程获取,其目录文件如下:
.
├── CMakeLists.txt
├── README.md
├── README_CN.md
├── infer_picodet_demo.cc # PicoDet C++部署推理程序
├── infer_ppyoloe_demo.cc
└── infer_yolov8_demo.cc
0 directories, 6 file
推理程序infer_picodet_demo.cc中RKNPU2推理固定了模型文件名称,我们可以自行修改或者自己重新编写推理程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | // NPU推理
void RKNPU2Infer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + "/picodet_s_416_coco_lcnet_rk3568_unquantized.rknn"; // 修改为自己的模型文件名称,教程测试是lubancat-2(rk3568)
auto params_file = "";
auto config_file = model_dir + "/infer_cfg.yml";
auto option = fastdeploy::RuntimeOption();
option.UseRKNPU2();
auto format = fastdeploy::ModelFormat::RKNN;
auto model = fastdeploy::vision::detection::PicoDet(
model_file, params_file, config_file, option, format);
model.GetPreprocessor().DisablePermute();
model.GetPreprocessor().DisableNormalize();
model.GetPostprocessor().ApplyNMS();
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
fastdeploy::TimeCounter tc;
tc.Start();
if (!model.Predict(&im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
tc.End();
tc.PrintInfo("PPDet in RKNPU2");
std::cout << res.Str() << std::endl;
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
cv::imwrite("infer_rknpu2.jpg", vis_im);
std::cout << "Visualized result saved in ./infer_rknpu2.jpg" << std::endl;
}
|
PicoDet如何编译和运行,可以阅读源码的README_CN.md/README.md文件。下面以lubancat-2板卡为例,简单编译测试下:
# 在源码目录下,创建build目录,然后切换到该目录下
mkdir build && cd build
# 执行cmake目录,FASTDEPLOY_INSTALL_DIR指定前面编译安装Fastdeploy C++ SDK的目录,教程测试就是~/FastDeploy-develop/build/fastdeploy-0.0.0
cmake .. -DFASTDEPLOY_INSTALL_DIR=~/FastDeploy-develop/build/fastdeploy-0.0.0
# 然后执行make编译,默认会编译全部推理程序,在当前目录下生成可执行文件,我们这里测试关注的是infer_picodet_demo
cat@lubancat:~/xxx/rknpu2/cpp/build$ make
Scanning dependencies of target infer_ppyoloe_demo
[ 16%] Building CXX object CMakeFiles/infer_ppyoloe_demo.dir/infer_ppyoloe_demo.cc.o
[ 33%] Linking CXX executable infer_ppyoloe_demo
[ 33%] Built target infer_ppyoloe_demo
Scanning dependencies of target infer_yolov8_demo
[ 50%] Building CXX object CMakeFiles/infer_yolov8_demo.dir/infer_yolov8_demo.cc.o
[ 66%] Linking CXX executable infer_yolov8_demo
[ 66%] Built target infer_yolov8_demo
Scanning dependencies of target infer_picodet_demo
[ 83%] Building CXX object CMakeFiles/infer_picodet_demo.dir/infer_picodet_demo.cc.o
[100%] Linking CXX executable infer_picodet_demo
[100%] Built target infer_picodet_demo
cat@lubancat:~/xxx/rknpu2/cpp/build$ ls
CMakeCache.txt CMakeFiles Makefile cmake_install.cmake infer_picodet_demo infer_ppyoloe_demo infer_yolov8_demo
生成了推理可执行程序infer_picodet_demo ,接下来复制模型文件,获取测试图片,然后推理测试。
复制前面转换的rknn模型文件到板卡,我们可以创建一个文件夹,存放模型文件和推理参数文件。 另外,前面编译Fastdeploy C++ SDK时设置了ENABLE_ORT_BACKEND=ON,也支持cpu推理,我们也复制picodet_s_416_coco_lcnet.onnx模型文件该目录下。
# 复制推理参数文件、模型文件和推理可执行程序,存放到一个目录下
cat@lubancat:~/xxx/test$ ls
infer_cfg.yml infer_picodet_demo picodet_s_416_coco_lcnet.onnx picodet_s_416_coco_lcnet_rk3568_unquantized.rknn
# 拉取测试图片
cat@lubancat:~/xxx/test$ wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
# CPU推理,infer_picodet_demo的第一个参数是指定模型目录,教程测试是当前目录下,第二个参数指定测试图片,最后一个参数是推理引擎,0是用CPU推理,1是RKNPU2推理
cat@lubancat:~/xxx/test$ ./infer_picodet_demo ./ 000000014439.jpg 0
[INFO] fastdeploy/vision/common/processors/transform.cc(45)::FuseNormalizeCast Normalize and Cast are fused to Normalize in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/runtime.cc(326)::CreateOrtBackend Runtime initialized with Backend::ORT in Device::CPU.
[FastDeploy] PPDet in ONNX duration = 0.612096s.
Visualized result saved in ./infer_onnx.jpg
# NPU推理(教程测试未修改CPU,DDR或者NPU频率,lubancat-2 debian10系统默认设置)
cat@lubancat:~/xxx/test$ ./infer_picodet_demo ./ 000000014439.jpg 1
[INFO] fastdeploy/vision/common/processors/transform.cc(45)::FuseNormalizeCast Normalize and Cast are fused to Normalize in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(81)::GetSDKAndDeviceVersion rknpu2 runtime version: 1.5.1b19 (32afb0e92@2023-07-14T12:46:17)
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(82)::GetSDKAndDeviceVersion rknpu2 driver version: 0.8.2
index=0, name=image, n_dims=4, dims=[1, 416, 416, 3], n_elems=519168, size=1038336, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=0, name=p2o.Mul.179, n_dims=4, dims=[1, 3598, 4, 1], n_elems=14392, size=28784, fmt=NCHW, type=FP32, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=1, name=p2o.Concat.9, n_dims=4, dims=[1, 80, 3598, 1], n_elems=287840, size=575680, fmt=NCHW, type=FP32, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
[INFO] fastdeploy/runtime/runtime.cc(367)::CreateRKNPU2Backend Runtime initialized with Backend::RKNPU2 in Device::RKNPU.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::FuseNormalizeColorConvert BGR2RGB and Normalize are fused to Normalize with swap_rb=1
[WARNING] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(420)::InitRKNNTensorMemory The input tensor type != model's inputs type.The input_type need FP16,but inputs[0].type is UINT8
[FastDeploy] PPDet in RKNPU2 duration = 0.190239s.
DetectionResult: [xmin, ymin, xmax, ymax, score, label_id]
413.461548,89.649635, 508.461548, 282.605743, 0.833008, 0
160.961548,81.698311, 200.000000, 166.795670, 0.812012, 0
265.576935,79.756004, 299.230774, 167.524033, 0.791992, 0
105.384621,46.251198, 126.730774, 93.534248, 0.769531, 0
584.230774,113.685692, 612.692322, 178.085327, 0.762695, 0
328.269257,40.211838, 344.423096, 80.545067, 0.636719, 0
379.038483,42.093449, 396.153870, 83.397835, 0.554199, 0
510.000031,116.052879, 598.846191, 278.235565, 0.541504, 0
24.038462,116.417061, 55.048080, 153.442307, 0.443115, 0
58.557693,136.325714, 107.115387, 173.836533, 0.428955, 0
352.307709,45.097954, 376.923096, 104.034851, 0.421387, 0
188.750000,45.795971, 200.000000, 61.637917, 0.414551, 0
352.692322,45.097954, 369.615387, 87.343147, 0.388672, 0
360.961548,61.000599, 383.461548, 114.353363, 0.363525, 0
505.000031,114.838936, 556.538452, 269.009613, 0.334717, 0
1.334135,150.286057, 37.091347, 172.622589, 0.400635, 24
58.269234,143.487976, 104.038467, 172.501190, 0.308594, 24
163.076935,87.525238, 600.000000, 344.274017, 0.576660, 33
164.519241,84.975960, 320.000000, 344.516815, 0.389648, 33
Visualized result saved in ./infer_rknpu2.jpg
在lubancat-2板卡,执行CPU推理一幅测试图片大约0.612096s,结果保存在当前目录的infer_onnx.jpg文件中; 执行NPU推理一幅测试图片大约0.190239s,结果图片保存在infer_rknpu2.jpg,推理结果图片和python推理相同,看下前面图片。