
4. PaddlePaddle FastDeploy¶
4.1. FastDeploy¶
For important AI models in industrial landing scenarios, FastDeploy standardizes the model API and provides demo examples that can be downloaded and run. FastDeploy also supports online (service deployment) and offline deployment forms to meet the deployment needs of different developers.
FastDeploy aims to provide AI developers with the optimal solution for model deployment. It has three characteristics: full-scenario, easy-to-use, and extremely efficient.
Full scene: Support GPU, CPU, Jetson, ARM CPU, Rockchip NPU, Amlogic NPU, NXP NPU and other types of hardware. It supports local deployment, service-based deployment, web-side deployment, mobile-side deployment, etc., and supports the three major fields of CV, NLP, and Speech. Supports 16 mainstream algorithm scenarios such as image classification, image segmentation, semantic segmentation, object detection, character recognition (OCR), face detection and recognition, portrait deduction, pose estimation, text classification, information extraction, pedestrian tracking, and speech synthesis.
Ease of use and flexibility: 3 lines of code complete the deployment of the AI model, 1 line of code quickly switches the back-end reasoning engine and deployment hardware, and the unified API enables zero-cost migration of different deployment scenarios.
Extreme efficiency: Compared with the traditional deep learning inference engine, which only focuses on the inference time of the model, FastDeploy focuses on the end-to-end deployment performance of the model task. Through high-performance pre- and post-processing, integration of high-performance inference engines, one-click automatic compression and other technologies, the ultimate performance optimization of AI model inference deployment is realized.
Next, we will simply build the environment and use FastDeploy to deploy the lightweight detection network PicoDet on rk356X.
提示
Test environment: lubancat board uses Debian10, PC side is WSL2 (ubuntu20.04). FastDeploy version 1.0.0, rknn-Toolkit2 version 1.4.0.
4.2. Environment configuration¶
4.2.1. PC-side model conversion and inference environment construction¶
It is necessary to install rknn-Toolkit2 and FastDeploy tools for model conversion, etc.
1、Install rknn-Toolkit2
Refer to the previous “NPU Use Chapter”
2、Install FastDeploy and other tools to install
# Install directly with the precompiled library, or compile and install with FastDeploy
# For detailed reference:
pip3 install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
# Install paddle2onnx
pip3 install paddle2onnx
# Install paddlepaddle
python -m pip3 install paddlepaddle==0.0.0 -f https://www.paddlepaddle.org.cn/whl/linux/cpu-mkl/develop.html
Please refer to here for paddlepaddle installation details.
4.2.2. Build FastDeploy RKNPU2 inference environment on board¶
1、Install RKNN driver environment
# Use the latest RK driver
git clone https://github.com/rockchip-linux/rknpu2
sudo cp ./rknpu2/runtime/RK356X/Linux/librknn_api/aarch64/* /usr/lib
sudo cp ./rknpu2/runtime/RK356X/Linux/rknn_server/aarch64/usr/bin/* /usr/bin/
You can also refer to the previous 《NPU Usage》.
2、Install FastDeploy
Reasoning needs to be deployed on the board side, so compile the Python SDK on the board side, then package it, and install FastDeploy.
# Get the source code
git clone https://github.com/PaddlePaddle/FastDeploy.git
# Environment variable
export ENABLE_ORT_BACKEND=ON
export ENABLE_RKNPU2_BACKEND=ON # Use rknpu2 as backend engine
export ENABLE_VISION=ON
export RKNN2_TARGET_SOC=rk356X # Rk356X platform
cd FastDeploy/python
# Compile, Package
sudo python3 setup.py build
sudo python3 setup.py bdist_wheel
# Install
cd dist
pip3 install fastdeploy_python-0.0.0-cp37-cp37m-linux_aarch64.whl
# If you don't want to compile and package, use fastdeploy_python-0.0.0-cp37-cp37m-linux_aarch64.whl in the supporting routine to install directly.
提示
rk356X freezes when compiling, probably because of insufficient memory. It is recommended to add a swap partition, at least 4G swap space, the compilation on the board is slow and you need to wait.
4.3. Example deployment inference¶
4.3.1. Lightweight detection network PicoDet¶
1、Model conversion
Rknn-Toolkit2 does not support the direct export of the Paddle model as an RKNN model for the time being. You need to use Paddle2ONNX to convert it into an onnx model, and then export the rknn model.
# Get the Paddle static graph model and decompress it (you can get it from the FastDeploy source file documentation, or get it from the supporting routine of this tutorial).
git clone https://github.com/PaddlePaddle/FastDeploy.git
# Or from the companion routine
git
tar -xvf picodet_s_416_coco_lcnet.zip
# Static graph model conversion onnx model
cd tools/rknpu2/picodet_s_416_coco_lcnet/
paddle2onnx --model_dir picodet_s_416_coco_lcnet \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--enable_dev_version True
# Fixed shape
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--output_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"
2、Export RKNN model
Depending on the version of Paddle2ONNX (1.0.5 was used for testing), the name of the output node of the conversion model is also different. You need to use Netron to visualize the model, find the NonMaxSuppression node, confirm the output node name, and then modify the outputs_nodes parameter in the picodet_s_416_coco_lcnet.yaml configuration file:
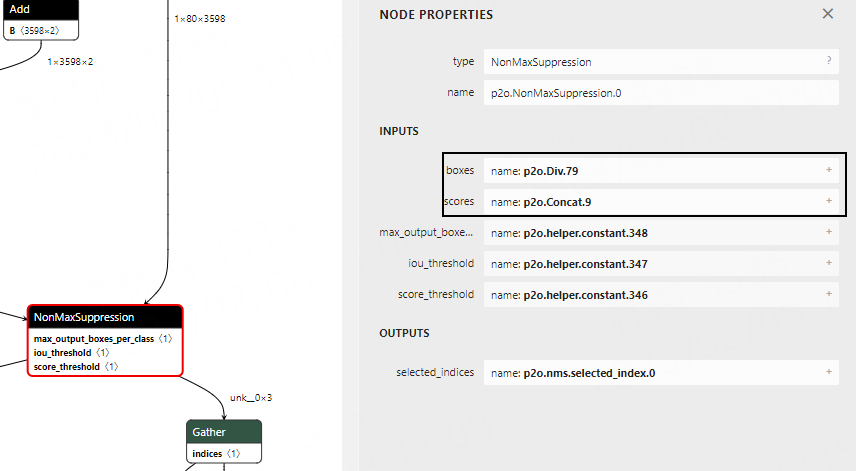
1 2 3 4 5 6 7 8 9 10 | mean:
std:
model_path: ./picodet_s_416_coco_lcnet1/picodet_s_416_coco_lcnet.onnx
target_platform: RK3568
outputs_nodes:
- 'p2o.Div.79'
- 'p2o.Concat.9'
do_quantization: False
dataset:
output_folder: "./picodet_s_416_coco_lcnet1"
|
# Export model
cd tools/rknpu2/
python export.py --config_path config/picodet_s_416_coco_lcnet.yaml --target_platform rk3568
3、 Board side deployment reasoning
# Inference deployment on the board side, you can use the rknn model exported by yourself earlier, or directly use the supporting routines.
cd examples/vision/detection/paddledetection/rknpu2/python
sudo python3 infer.py --model_file picodet_s_416_coco_lcnet_rk3568_unquantized.rknn --config_file infer_cfg.yml --image 00000014439.jpg
# Among them --model_file specifies the model file, --config_file specifies the configuration file, --image specifies the image that needs to be inferred.
Running inference shows:
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::FuseNormalizeColorConvert BGR2RGB and Normalize are fused to Normalize with swap_rb=1
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(57)::GetSDKAndDeviceVersion rknn_api/rknnrt version: 1.4.0 (a10f100eb@2022-09-09T09:07:14), driver version: 0.7.2
E RKNN: [15:17:31.563] rknn_set_core_mask: No implementation found for current platform!
index=0, name=image, n_dims=4, dims=[1, 416, 416, 3], n_elems=519168, size=1038336, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=1, name=scale_factor, n_dims=2, dims=[1, 2, 0, 0], n_elems=2, size=4, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=0, name=p2o.Div.79, n_dims=4, dims=[1, 3598, 4, 1], n_elems=14392, size=28784, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
index=1, name=p2o.Concat.9, n_dims=4, dims=[1, 80, 3598, 1], n_elems=287840, size=575680, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000, pass_through=0
[INFO] fastdeploy/runtime/runtime.cc(449)::CreateRKNPU2Backend Runtime initialized with Backend::RKNPU2 in Device::RKNPU.
[WARNING] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(315)::Infer The input tensor type != model's inputs type.The input_type need FP16,but inputs[0].type is FP32
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(328)::Infer The input model is not a quantitative model. Close the normalize operation.
[WARNING] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(315)::Infer The input tensor type != model's inputs type.The input_type need FP16,but inputs[1].type is FP32
[INFO] fastdeploy/runtime/backends/rknpu2/rknpu2_backend.cc(328)::Infer The input model is not a quantitative model. Close the normalize operation.
DetectionResult: [xmin, ymin, xmax, ymax, score, label_id]
268.500000,91.562500, 329.500000, 290.500000, 0.822266, 0
104.312500,84.187500, 129.500000, 171.500000, 0.810547, 0
172.375000,81.875000, 194.375000, 172.000000, 0.762207, 0
68.437500,47.156250, 82.312500, 96.187500, 0.759766, 0
380.000000,117.250000, 398.000000, 183.125000, 0.750977, 0
213.125000,41.343750, 224.125000, 82.125000, 0.666016, 0
246.125000,42.875000, 257.500000, 85.500000, 0.535645, 0
331.750000,119.625000, 389.750000, 283.500000, 0.502930, 0
229.000000,46.625000, 245.125000, 105.937500, 0.500000, 0
37.968750,140.625000, 72.687500, 178.875000, 0.493164, 0
122.000000,47.031250, 129.500000, 63.625000, 0.430420, 0
15.351562,119.625000, 35.531250, 156.750000, 0.406006, 0
328.000000,118.000000, 361.500000, 276.500000, 0.348145, 0
229.000000,45.750000, 239.750000, 85.875000, 0.334229, 0
234.000000,56.343750, 248.875000, 109.875000, 0.318115, 0
0.632812,154.875000, 24.468750, 177.250000, 0.354248, 24
106.250000,89.875000, 399.500000, 354.250000, 0.607422, 33
107.000000,87.250000, 206.250000, 354.000000, 0.363037, 33
Visualized result save in ./visualized_result.jpg
Simple test results show:

4.4. Reference link¶
For more documents such as environment construction, deployment optimization, and deployment examples, please refer to the following:
https://github.com/PaddlePaddle/FastDeploy/tree/develop/docs
https://github.com/PaddlePaddle/FastDeploy/tree/develop/docs/cn/faq/rknpu2