
1. 进程¶
本章深入讲解Linux内核提供的进程核心机制,涵盖进程基础概念、创建、终止等待、程序替换、优先级调度及实操案例, 吃透进程相关内核特性,既能明晰Linux内核为应用层提供的核心能力,也能为后续底层驱动开发、系统级编程筑牢基础, 助力开发者掌握多任务并发编程的核心技能。
1.1. 进程概述¶
进程是Linux系统调度与资源分配的基本单元,是程序的动态执行实例,区别于静态程序, 进程具备完整生命周期、独立虚拟地址空间和调度属性,是实现系统多任务运行的核心载体。
1.1.1. 进程核心概念¶
程序是存储在磁盘上的二进制指令与数据集合,属于静态实体;而进程是程序加载至内存后的执行实例,是动态运行的单元。 Linux系统通过进程控制块(PCB,task_struct结构体)管理进程, 该结构体存储进程PID、状态、优先级、资源占用、调度信息等全部关键数据,是内核操控进程的核心依据。
进程具备资源隔离特性,每个进程拥有独立的虚拟地址空间,进程间互不干扰,即便单个进程崩溃, 也不会影响其他进程与系统整体稳定性,这也是Linux系统稳定运行的关键保障。
1.1.2. 进程标识符¶
Linux为每个进程分配唯一数字标识,用于内核区分、管理进程,核心标识符为PID和PPID,二者是进程操作的基础依据:
PID(Process ID):进程ID,进程的唯一身份标识,取值范围默认为2~32767。 其中PID=0为系统调度进程,PID=1为init/systemd系统顶级进程,负责初始化系统、管理其他进程。
PPID(Parent Process ID):父进程ID,代表创建当前进程的父进程PID。除系统初始化的顶级进程外,所有进程均由父进程创建。
查看系统进程可通过ps -aux、pstree命令实现,pstree能以树状结构直观展示进程间的父子关系,若命令缺失可通过 sudo apt install psmisc 安装。
1.2. 程序与进程¶
1.2.1. 程序的概念¶
程序(program)是一个普通文件,是为了完成特定任务而准备好的指令序列与数据的集合, 这些指令和数据以”可执行映像”的格式保存在磁盘中。正如我们所写的一些代码,经过编译器编译后, 就会生成对应的可执行文件,那么这个就是程序,或者称之为可执行程序。
1.2.2. 程序变成进程¶
在Linux系统中,程序只是个静态的文件,而进程是一个动态的实体, 进程的状态会在运行过程中改变,整个转换过程主要包含以下3个步骤:
查找命令对应程序文件的位置;
使用fork()函数为启动一个新进程;
在新进程中调用exec族函数装载程序文件,并执行程序文件中的main()函数。
1.2.3. 程序与进程关系¶
总的来说,程序与进程有以下的关系:
程序只是一系列指令序列与数据的集合,它本身没有任何运行的含义, 它只是一个静态的实体。而进程则不同,它是程序在某个数据集上的执行过程, 它是一个动态运行的实体,有自己的生命周期,它因启动而产生,因调度而运行, 因等待资源或事件而被处于等待状态,因完成任务而被销毁。
进程和程序并不是一一对应的,一个程序执行在不同的数据集上运行就会成为不同的进程, 可以用进程控制块来唯一地标识系统中的每个进程。而这一点正是程序无法做到的, 由于程序没有和数据产生直接的联系,既使是执行不同的数据的程序, 他们的指令的集合依然是一样的,所以无法唯一地标识出这些运行于不同数据集上的程序。 一般来说,一个进程肯定有一个与之对应的程序,而且有且只有一个。 而一个程序有可能没有与之对应的进程(因为这个程序没有被运行), 也有可能有多个进程与之对应(这个程序可能运行在多个不同的数据集上)。
进程具有并发性而程序没有。
进程是竞争计算机资源的基本单位,而程序不是。
1.3. 进程状态及转换¶
进程从创建到消亡的生命周期内,会随系统调度、资源等待等场景切换状态,Linux内核定义了5种核心进程状态, 且状态流转遵循固定逻辑,是理解进程运行机制的关键。
进程核心状态:
进程状态 |
状态说明 |
|---|---|
就绪状态(TASK_RUNNING) |
进程已获取除CPU外的全部运行资源,等待系统调度分配CPU,与运行态共用同一标识,仅是否占用CPU存在区别。 |
运行状态(TASK_RUNNING) |
进程占用CPU,正在执行指令,单核CPU同一时刻仅一个进程处于该状态。 |
阻塞状态(睡眠状态) |
进程因等待IO完成、信号触发、资源可用等事件,主动放弃CPU,分为可中断睡眠(TASK_INTERRUPTIBLE,可被信号唤醒)和不可中断睡眠(TASK_UNINTERRUPTIBLE,仅等待事件触发,不响应信号)。 |
暂停状态(TASK_STOPPED) |
进程收到SIGSTOP、SIGTSTP等暂停信号后停止执行,释放CPU,收到SIGCONT信号后可恢复至就绪态。 |
僵尸状态(TASK_ZOMBIE) |
进程已终止运行,但PCB等内核资源未被父进程回收,内核保留其退出信息,属于无效进程且占用系统资源。 |
在<<Linux终端与命令行基础>>章节的ps命令小节已经详细讲解了进程的当前运行状态, 通过ps命令将系统中运行的进程信息打印出来,我们只需要关注STAT那一列的信息即可,进程的状态非常多种:
在PC或开发板上执行以下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #查看系统中前10个进程的详细信息
ps aux | head -10
#信息输出如下
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.9 0.4 165340 9456 ? Ss 08:55 1:48 /sbin/init earlyprintk #jia-01/10/2026
root 2 0.0 0.0 0 0 ? S 08:55 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< 08:55 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< 08:55 0:00 [rcu_par_gp]
root 8 0.0 0.0 0 0 ? I< 08:55 0:00 [mm_percpu_wq]
root 9 0.0 0.0 0 0 ? S 08:55 0:03 [ksoftirqd/0]
root 10 0.7 0.0 0 0 ? I 08:55 1:19 [rcu_sched]
root 11 0.0 0.0 0 0 ? I 08:55 0:00 [rcu_bh]
root 12 0.0 0.0 0 0 ? S 08:55 0:00 [migration/0]
|
常见状态如下:
Ss:S表示可中断睡眠,s表示是会话首进程;
I<:I表示内核空闲线程,<表示高优先级;
R+:R表示正在运行,+表示前台进程;
Ssl+:S睡眠、s会话首进程、l多线程、+前台。
1.3.1. 进程状态转换流程¶
从前文的介绍我们知道,进程是动态的活动的实例,这其实指的是进程会有很多种运行状态, 一会儿睡眠、一会儿暂停、一会儿又继续执行。虽然Linux操作系统是一个多用户多任务的操作系统, 但对于单核的CPU系统来说,在某一时刻,只能有一个进程处于运行状态, 其他进程都处于其他状态,等待系统资源,各任务根据调度算法在这些状态之间不停地切换。 但由于CPU处理速率较快,使用户感觉每个进程都是同时运行。
下图展示了Linux进程从被启动到退出的全部状态,以及这些状态发生转换时的条件。
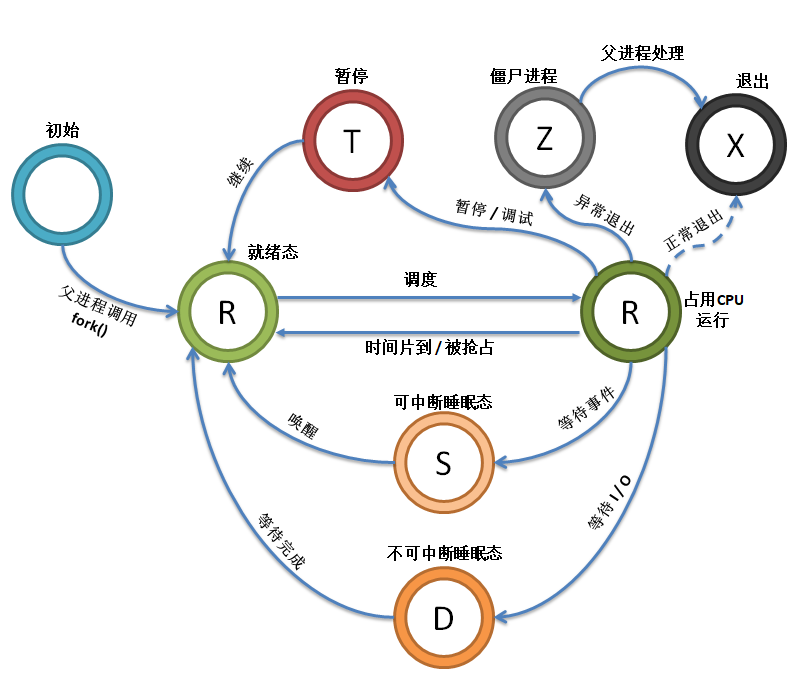
进程通过fork创建后,初始化完成进入就绪状态,排队等待CPU调度;
系统调度器选中就绪进程,分配CPU,进程切换至运行状态,开始执行指令;
运行中进程等待外部事件/资源,主动放弃CPU,进入阻塞状态;
阻塞进程等待的事件触发后,内核将其唤醒,重回就绪状态等待调度;
运行中进程收到暂停信号,进入暂停状态,收到继续信号后恢复至就绪态;
运行中进程时间片耗尽,主动让出CPU,切换为就绪状态,等待下一轮调度;
进程执行完毕或主动终止,进入僵尸状态,父进程回收其资源后,进程彻底消亡。
1.3.2. 孤儿进程与僵尸进程¶
父子进程退出顺序差异,会产生两类特殊进程:
孤儿进程:父进程先于子进程退出,子进程失去父进程成为孤儿进程。系统会将其托管给PID=1的init/systemd进程, 由该进程负责回收资源,孤儿进程可正常运行,无系统危害。
僵尸进程:子进程先于父进程退出,但其PCB资源未被父进程回收,长期处于僵尸状态。 僵尸进程会占用进程表资源,大量堆积会导致进程号耗尽,无法创建新进程,需通过父进程调用wait/waitpid函数回收资源解决。
1.4. 进程创建¶
在Linux中启动一个进程有多种方法,比如可以使用system()函数, 也可以使用fork()函数去启动一个新的进程,第一种方法相对简单,但是效率低下,而且有不容忽视的安全风险。 第二种方法相对复杂了很多,但是提供了更好的弹性、效率和安全性。
1.4.1. system函数¶
这个system()函数是C标准库中提供的,它主要是提供了一种调用其它程序的简单方法。 读者可以利用system()函数调用一些应用程序,它产生的结果与从shell中执行这个程序基本相似。 事实上,system()启动了一个运行着/bin/sh的子进程,然后将命令交由它执行,其中/bin/sh是一个shell的一种。
我们举个例子,使用system()函数启动一个新进程ls,具体的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
pid_t result;
printf("This is a system demo!\n\n");
/*调用 system()函数*/
result = system("ls -l");
printf("Done!\n\n");
return result;
}
|
调用system()函数传入一个命令“ls -l”这个命令与在shell中运行的结果是一样的, 函数的返回值就是被调用的shell命令的返回值。
1.4.2. fork函数¶
在前面的文章我们也了解到,init进程可以启动一个子进程, 它通过fork()函数从原程序中创建一个完全分离的子进程, 当然,这只是init进程启动子进程的第一步,后续还有其他操作的。 不管怎么说,fork()函数的基础功能就是启动一个子进程,其示意图如下。
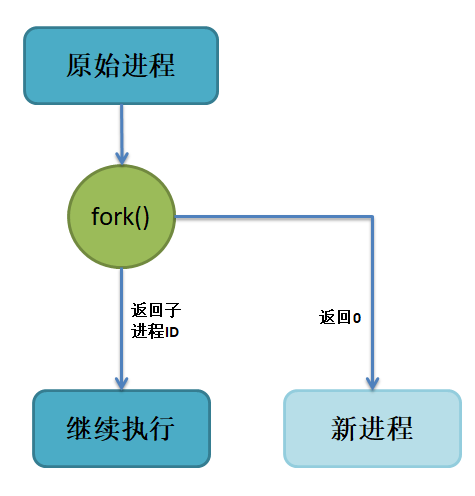
在父进程中的fork()调用后返回的是新的子进程的PID。 新进程将继续执行,就像原进程一样,不同之处在于,子进程中的fork()函数调用后返回的是0, 父子进程可以通过返回的值来判断究竟谁是父进程,谁是子进程。
1.4.2.1. 核心特性¶
使用fork()函数的本质是将父进程的内容复制一份,正如细胞分裂一样, 得到的是几乎两个完全一样的细胞,因此这个启动的子进程基本上是父进程的一个复制品, 但子进程与父进程有不一样的地方,它们的联系与区别简单列举如下:
子进程与父进程一致的内容:
进程的地址空间。
进程上下文、代码段。
进程堆空间、栈空间,内存信息。
进程的环境变量。
标准 IO 的缓冲区。
打开的文件描述符。
信号响应函数。
当前工作路径。
子进程独有的内容:
进程号 PID。 PID 是身份证号码,是进程的唯一标识符。
记录锁。父进程对某文件加了把锁,子进程不会继承这把锁。
挂起的信号。这些信号是已经响应但尚未处理的信号,也就是”悬挂”的信号, 子进程也不会继承这些信号。
1.4.2.2. 写时复制¶
因为子进程几乎是父进程的完全复制,所以父子两个进程会运行同一个程序, 但是这种复制有一个很大的问题,就是资源与时间都会消耗很大。
为优化fork执行效率,Linux采用写时复制机制:子进程创建时,不立即复制父进程全部内存空间,父子进程共享物理内存; 仅当任一进程尝试修改内存数据时,内核才复制对应内存页,实现资源隔离。该机制大幅降低进程创建开销,兼顾效率与独立性。
除此之外,fork创建的子进程继承父进程文件描述符、信号掩码、当前工作目录等属性,同时拥有独立PID、虚拟地址空间, 父子进程并发执行,调度顺序由系统调度器决定,无固定先后。
1.4.2.3. fork函数详解¶
理论相关的知识了解至此,下面看看fork()函数的使用,它的函数原型如下:
1 2 3 4 5 6 7 8 9 | #include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
// 返回值:
// 返回值<0:进程创建失败,原因多为系统进程数达上限、内存不足,可通过errno排查错误;
// 返回值=0:该返回流向子进程,代表当前执行流为子进程;
// 返回值>0:该返回流向父进程,返回值为创建成功的子进程PID。
|
1.4.2.4. 示例源码¶
我们举个例子,使用fork()函数启动一个新进程, 并且在进程中打印相关的信息,具体的代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
pid_t result;
printf("This is a fork demo!\n\n");
/*调用 fork()函数*/
result = fork();
/*通过 result 的值来判断 fork()函数的返回情况,首先进行出错处理*/
if(result == -1) {
printf("Fork error\n");
}
/*返回值为 0 代表子进程*/
else if (result == 0) {
printf("The returned value is %d, In child process!! My PID is %d\n\n", result, getpid());
}
/*返回值大于 0 代表父进程*/
else {
printf("The returned value is %d, In father process!! My PID is %d\n\n", result, getpid());
}
return result;
}
|
代码分析如下:
首先在第12行的时候调用了fork函数,调用fork函数后系统就会启动一个子进程,并且子进程与父进程执行的内容是一样的, 可以通过返回值result判断fork()函数的执行结果。
如果result的值为-1,那代表着fork()函数执行出错。
如果返回的值为0,则表示此时执行的代码是子进程,那么就打印返回的结果、“In child process!!”与子进程的PID, 进程的PID通过getpid()函数获取得到。
如果返回的值大于0,则表示此时执行的代码是父进程,同样也打印出返回的结果、”In father process!!”与父进程的PID。
1.4.2.5. 实验操作¶
fork例程的编译及测试过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 | # 以下操作在system_programing/fork代码目录进行
make
# 运行程序
./build/fork_demo
#信息输出如下
This is a fork demo!
The returned value is 7018, In father process!! My PID is 7017
The returned value is 0, In child process!! My PID is 7018
|
在这个实验现象中,进程和子进程各自执行了一部分代码,所以打印了两遍returned value。 调用fork()后,操作系统会复制当前进程(父进程)的整个地址空间,创建一个全新的子进程。
子进程会从fork()函数 返回的位置 继续执行,而不是从main函数开头重新执行,所以没有打印This is a fork demo!。
父进程的fork()返回子进程的PID(大于 0),子进程的fork()返回0。
1.5. 进程替换¶
事实上,使用fork()函数启动一个子进程是并没有太大作用的,因为子进程跟父进程都是一样的, 子进程能干的活父进程也一样能干,因此世界各地的开发者就想方设法让子进程做不一样的事情, 于是诞生了exec系列函数。
1.5.1. exec系列函数¶
exec系列函数主要是用于替换进程的执行程序,它可以根据指定的文件名或目录名找到可执行文件, 并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外, 其他全部被新程序的内容替换。
另外,这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行脚本文件。 举个例子,A进程通过exec系列函数启动一个进程B,此时进程B会替换进程A, 进程A的内存空间、数据段、代码段等内容都将被进程B占用,然后进程A将不复存在。
1.5.1.1. 函数原型¶
Linux提供6个exec系列函数,功能完全一致,仅传参方式不同,均为系统调用封装。 函数执行成功后,进程执行流跳转至新程序,无返回值;执行失败返回-1,继续执行原进程代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <unistd.h>
// 1. execl:路径+参数列表,以NULL结尾
int execl(const char *path, const char *arg, ...);
// 2. execlp:文件名+参数列表,自动搜索PATH环境变量
int execlp(const char *file, const char *arg, ...);
// 3. execle:路径+参数列表+自定义环境变量
int execle(const char *path, const char *arg, ..., char *const envp[]);
// 4. execv:路径+参数数组
int execv(const char *path, char *const argv[]);
// 5. execvp:文件名+参数数组,自动搜索PATH
int execvp(const char *file, char *const argv[]);
// 6. execvpe:文件名+参数数组+自定义环境变量,搜索PATH
int execvpe(const char *file, char *const argv[], char *const envp[]);
|
这些函数可以分为两大类,execl、execlp和execle传递给子程序的参数个数是可变的, execv、execvp和execve通过数组去装载子程序的参数,无论那种形式,参数都以一个空指针NULL结束。
总结来说,可以通过它们的后缀来区分他们的作用:
名称包含 l 字母的函数(execl、execlp和execle)接收参数列表“list”作为调用程序的参数。
名称包含 p 字母的函数(execvp 和 execlp)可接受一个程序名作为参数, 它会在当前的执行路径和环境变量“PATH”中搜索并执行这个程序(即可使用相对路径); 名字不包含p字母的函数在调用时必须指定程序的完整路径(即要求绝对路径)。
名称包含 v 字母的函数(execv、execvp 和 execve)的子程序参数通过一个数组“vector”装载。
名称包含 e 字母的函数(execve 和 execle)比其它函数多接收一个指明环境变量列表的参数, 并且可以通过参数envp传递字符串数组作为新程序的环境变量, 这个envp参数的格式应为一个以 NULL 指针作为结束标记的字符串数组, 每个字符串应该表示为“environment = virables”的形式。
1.5.1.2. 示例代码¶
下面直接通过execl()实验进行讲解:
1 | int execl(const char *path, const char *arg, ...)
|
execl()函数用于执行参数path字符串所代表的文件路径(必须指定路径),
接下来是一系列可变参数,它们代表执行该文件时传递过去的 argv[0]、argv[1]… argv[n] ,
最后一个参数必须用空指针NULL作为结束的标志。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | int main(void)
{
int err;
printf("this is a execl function test demo!\n\n");
err = execl("/bin/ls", "ls", "-la", NULL);
if (err < 0) {
printf("execl fail!\n\n");
}
printf("Done!\n\n");
}
|
代码中通过execl()函数的参数列表调用了ls命令程序,
然后将第二个以后的参数当做该文件的 argv[0]、argv[1]… argv[n],
最后一个参数必须用空指针NULL作为结束的标志。
它其实就是与我们在终端上运行”ls -la”产生的结果是一样的。
以上函数实例代码在system_programing/exec/sources/exec.c文件中, 使用如下命令即可编译测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 以下操作在system_programing/exec代码目录进行
make
# 运行程序
./build/exec_demo
#信息输出如下
this is a execl function test demo!
total 20
drwxrwxr-x 4 guest guest 4096 Mar 10 02:55 .
drwxrwxr-x 27 guest guest 4096 Mar 3 08:53 ..
drwxrwxr-x 2 guest guest 4096 Mar 10 02:55 build
-rw-rw-r-- 1 guest guest 1557 Mar 10 02:55 Makefile
drwxrwxr-x 2 guest guest 4096 Mar 3 08:53 sources
|
程序先打印出它的第一条消息”this is a execl function test demo!”, 接着调用execl()函数,这个函数在/bin/ls目录中搜索程序ls, 然后它将会替换exec_demo本身的进程, 程序运行结果与在终端中使用以下所示的shell命令一样。
提示
exec系列函数是直接将当前进程给替换掉的, 当调用exec系列函数后,当前进程将不会再继续执行, 所以示例程序中的“ Done! ”将不被输出,因为当前进程已经被替换了,一般情况下, exec系列函数函数是不会返回的,除非发生了错误。出现错误时, exec系列函数将返回-1,并且会设置错误变量errno。
因此我们可以通过调用fork()复制启动一个子进程,并且在子进程中调用exec系列函数替换子进程, 这样把fork()和exec系列函数结合在一起使用就是创建一个新进程所需要的一切了。
1.6. 终止进程¶
进程执行完毕后需规范终止,释放占用资源;父进程需获取子进程退出状态、回收残留资源,避免僵尸进程产生。
1.6.1. 进程终止方式¶
在Linux系统中,进程终止(或者称为进程退出,为了统一,下文均使用“终止”一词)的常见方式有5种, 可以分为正常终止与异常终止:
正常终止
main函数执行return语句,返回值作为进程退出码;
调用exit()标准库函数,执行清理操作后终止进程;
调用_exit()系统调用,内核直接终止进程,无清理操作。
异常终止
进程收到SIGKILL、SIGSEGV等致命终止信号,被迫终止;
进程执行非法指令、内存访问越界,被内核强制终止。
1.6.2. 进程终止函数¶
在Linux系统中,exit()函数定义在stdlib.h中,而_exit()定义在unistd.h中, exit()和_exit()函数都是用来终止进程的,当程序执行到exit()或_exit()函数时, 进程会无条件地停止剩下的所有操作,清除包括PCB在内的各种数据结构,并终止当前进程的运行。 不过这两个函数还是有区别的,具体下图所示。
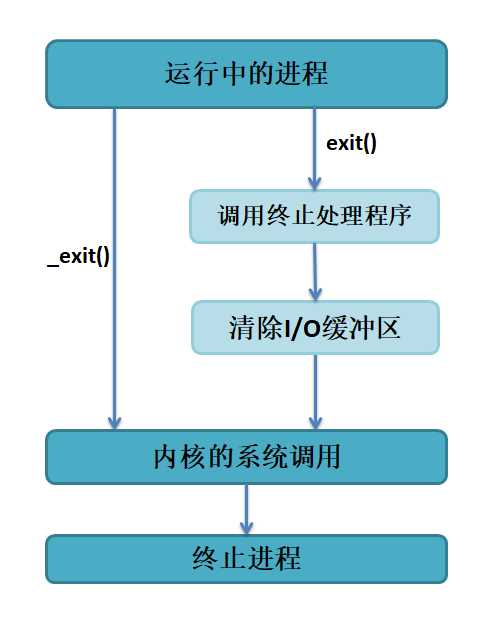
从图中可以看出,_exit()函数的作用最为简单:直接通过系统调用使进程终止运行, 当然,在终止进程的时候会清除这个进程使用的内存空间,并销毁它在内核中的各种数据结构; 而exit()函数则在这些基础上做了一些包装,在执行退出之前加了若干道工序: 比如exit()函数在调用exit系统调用之前要检查文件的打开情况, 把文件缓冲区中的内容写回文件,这就是“清除I/O缓冲”。
由于在 Linux 的标准函数库中,有一种被称作“缓冲 I/O(buffered I/O)”操作, 其特征就是对应每一个打开的文件,在内存中都有一片缓冲区。每次读文件时, 会连续读出若干条记录,这样在下次读文件时就可以直接从内存的缓冲区中读取; 同样,每次写文件的时候,也仅仅是写入内存中的缓冲区,等满足了一定的条件(如达到一定数量或遇到特定字符等), 再将缓冲区中的内容一次性写入文件。
这种技术大大增加了文件读写的速度,但也为编程带来了一些麻烦。 比如有些数据,程序认为已经被写入文件中,实际上因为没有满足特定的条件,它们还只是被保存在缓冲区内, 这时用_exit()函数直接将进程关闭,缓冲区中的数据就会丢失。 因此,若想保证数据的完整性,就一定要使用exit()函数。
不管是那种退出方式,系统最终都会执行内核中的同一代码,这段代码用来关闭进程所用已打开的文件描述符, 释放它所占用的内存和其他资源。
1.6.2.1. _exit函数¶
_exit函数用于直接终止当前进程,内核立即回收进程内存、文件描述符等资源,不执行任何清理操作。
1 2 3 4 5 | #include <unistd.h>
void _exit(int status);
// 参数:status为进程退出状态码,0代表正常退出,非0代表异常退出,状态码会被父进程获取
|
_exit函数适用于子进程,避免重复清理父进程资源。
1.6.2.2. exit函数¶
exit函数是标准进程终止函数,先执行清理操作,再调用_exit()终止进程。
1 2 3 4 5 | #include <stdlib.h>
void exit(int status);
// 参数:status为进程退出状态码,0代表正常退出,非0代表异常退出,状态码会被父进程获取
|
exit函数安全可靠,保证数据完整性,适用于普通进程正常退出场景。
1.7. 等待进程¶
在Linux中,当我们使用fork()函数启动一个子进程时,子进程就有了它自己的生命周期并将独立运行, 在某些时候,可能父进程希望知道一个子进程何时结束,或者想要知道子进程结束的状态, 甚至是等待着子进程结束,那么我们可以通过在父进程中调用wait()或者waitpid()函数让父进程等待子进程的结束。
当一个进程调用了exit()之后,该进程并不会立刻完全消失,而是变成了一个僵尸进程。 无论如何,父进程都要回收这个僵尸进程,因此调用wait()或者waitpid()函数其实就是将这些僵尸进程回收, 释放僵尸进程占有的内存空间,并且了解一下进程终止的状态信息。
1.7.1. wait函数¶
wait函数用于父进程阻塞等待任意子进程终止,回收子进程资源,获取退出状态。
1 2 3 4 5 6 7 | #include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *wstatus);
// 参数:wstatus为整型指针,存储子进程退出状态;
// 返回值:成功返回终止子进程PID,失败返回-1(无子进程可等待);
|
wait()函数在被调用的时候,系统将暂停父进程的执行,直到有信号来到或子进程结束, 如果在调用wait()函数时子进程已经结束,则会立即返回子进程结束状态值。
子进程的结束状态信息会由参数wstatus返回,与此同时该函数会返子进程的PID, 它通常是已经结束运行的子进程的PID,状态信息允许父进程了解子进程的退出状态。
wait()函数有几点需要注意的地方:
wait()要与fork()配套出现,如果在使用fork()之前调用wait(),wait()的返回值则为-1, 正常情况下wait()的返回值为子进程的PID。
参数wstatus用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针, 但如果我们对这个子进程是如何死掉毫不在意,只想把这个僵尸进程消灭掉, (事实上绝大多数情况下,我们都会这样做),我们就可以设定这个参数为NULL。
当然,Linux系统提供了关于等待子进程退出状态的一些宏定义, 我们可以使用这些宏定义来直接判断子进程退出的状态:
WIFEXITED(status) :如果子进程正常结束,返回一个非零值
WEXITSTATUS(status): 如果WIFEXITED非零,返回子进程退出码
WIFSIGNALED(status) :子进程因为捕获信号而终止,返回非零值
WTERMSIG(status) :如果WIFSIGNALED非零,返回信号代码
WIFSTOPPED(status): 如果子进程被暂停,返回一个非零值
WSTOPSIG(status): 如果WIFSTOPPED非零,返回一个信号代码
1.7.1.1. 实验分析¶
wait()函数使用实例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | #include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
pid_t pid, child_pid;
int status;
pid = fork(); //(1)
if (pid < 0) {
printf("Error fork\n");
}
/*子进程*/
else if (pid == 0) { //(2)
printf("I am a child process!, my pid is %d!\n\n",getpid());
/*子进程暂停 3s*/
sleep(3);
printf("I am about to quit the process!\n\n");
/*子进程正常退出*/
exit(0); //(3)
}
/*父进程*/
else { //(4)
/*调用 wait,父进程阻塞*/
child_pid = wait(&status); //(5)
/*若发现子进程退出,打印出相应情况*/
if (child_pid == pid) {
printf("Get exit child process id: %d\n",child_pid);
printf("Get child exit status: %d\n\n",status);
} else {
printf("Some error occured.\n\n");
}
exit(0);
}
}
|
我们来分析一下这段代码:
(1) :首先调用fork()函数启动一个子进程。
(2) :如果fork()函数返回的值pid为0,则表示此时运行的是子进程,那么就让子进程输出一段信息,并且休眠3秒。
(3) :休眠结束后调用exit()函数退出,退出状态为0,表示子进程正常退出。
(4) :如果fork()函数返回的值pid不为0,则表示此时运行的是父进程, 那么在父进程中调用wait(&status)函数等待子进程的退出,子进程的退出状态将保存在status变量中。
(5) :若发现子进程退出(通过wait()函数返回的子进程pid判断),则打印出相应信息,如子进程的pid与status。
本实例代码在system_programing/wait目录下, wait.c文件中包含了wait()函数和waitpid()函数的示例,通过宏进行切换即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 | # 以下操作在 system_programing/wait代码目录进行
make
# 运行程序
./build/wait_demo
#信息输出如下
I am a child process!, my pid is 7735!
I am about to quit the process!
Get exit child process id: 7735
Get child exit status: 0
|
1.7.2. waitpid()¶
waitpid()函数的作用和wait()函数一样,但它并不一定要等待第一个终止的子进程, 它还有其他选项,比如指定等待某个pid的子进程、提供一个非阻塞版本的wait()功能等。 实际上wait()函数只是waitpid()函数的一个特例,在Linux内部实现wait函数时直接调用的就是waitpid函数。
函数原型:
1 2 3 4 | #include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *wstatus, int options);
|
waitpid()函数的参数有3个,下面就简单介绍这些参数相关的选项:
pid:参数pid为要等待的子进程ID,其具体含义如下:
pid < -1:等待进程组号为pid绝对值的任何子进程。
pid = -1:等待任何子进程,此时的waitpid()函数就等同于wait()函数。
pid = 0:等待进程组号与目前进程相同的任何子进程, 即等待任何与调用waitpid()函数的进程在同一个进程组的进程。
pid > 0:等待指定进程号为pid的子进程。
wstatus:与wait()函数一样。
options:参数options提供了一些另外的选项来控制waitpid()函数的行为。 如果不想使用这些选项,则可以把这个参数设为0。
WNOHANG:如果pid指定的子进程没有终止运行,则waitpid()函数立即返回0, 而不是阻塞在这个函数上等待;如果子进程已经终止运行,则立即返回该子进程的进程号与状态信息。
WUNTRACED:如果子进程进入了暂停状态(可能子进程正处于被追踪等情况),则马上返回。
WCONTINUED:如果子进程恢复通过SIGCONT信号运行,也会立即返回(这个不常用,了解一下即可)。
很显然,当waitpid()函数的参数为(子进程pid, status,0)时,waitpid()函数就完全退化成了wait()函数。
wait.c实例文件中提供了waitpid函数的示例,示例的实验现象与wait()函数的是类似的。
1.8. 进程优先级与调度¶
Linux系统并发运行大量进程,CPU通过调度策略分配运行时间,进程优先级是调度核心依据,优先级越高,越易获取CPU资源。
1.8.1. 进程优先级基础¶
Linux进程优先级由nice值决定,nice值取值范围为-20 ~ +19:nice值越小,进程优先级越高,CPU调度权重越大;nice值越大,优先级越低,CPU分配时间越少。
普通用户:仅能调高nice值(0~+19),降低进程优先级,无权提升优先级;
root用户:可自由调整nice值,既能提升(-20~0)也能降低优先级;
默认配置:进程创建后,nice值默认为0,优先级处于中等水平。
1.8.2. 进程优先级调整方式¶
1.8.2.1. nice函数¶
nice函数用于调整当前进程nice值,在原有值基础上增加增量incr。
函数原型:
1 2 3 4 5 6 | #include <unistd.h>
int nice(int incr);
// 参数:incr为增量,正数降低优先级,负数提升优先级(仅root可用)
// 返回值:成功返回调整后的nice值,失败返回-1。
|
1.8.2.2. renice命令¶
除函数调整外,可通过shell命令调整运行中进程优先级,命令格式:
1 | renice [nice值] -p [进程PID]
|
示例:
1 2 3 4 5 | # root提升指定进程优先级
sudo renice -5 -p 1234
# 普通用户降低指定进程优先级
renice 10 -p 1234
|
1.9. 多进程协作程序实现示例¶
本示例实现多子进程创建与管理:
用ChildTask结构体存储每个子进程的PID、任务类型、回收状态,便于父进程统一管理;
循环创建3个子进程,分别执行ls -l、pwd和自定义计算任务。
1.9.1. 程序源码¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 | #include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
// 定义子进程任务类型枚举
typedef enum {
TASK_LS, // 执行ls -l命令
TASK_PWD, // 执行pwd命令
TASK_CUSTOM // 自定义计算任务
} TaskType;
// 子进程任务信息结构体,用于父进程管理
typedef struct {
pid_t pid; // 子进程PID
TaskType type; // 任务类型
char desc[32]; // 任务描述
int is_recycled; // 是否已被回收,0:未回收,1:已回收
} ChildTask;
// 自定义任务:计算1~100的和并写入文件
void custom_child_task() {
printf("子进程PID=%d 开始执行自定义任务:计算1~100的和并写入文件\n", getpid());
// 计算1~100的和
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
// 打开/创建文件,写入计算结果
int fd = open("custom_task_result.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd < 0) {
perror("自定义任务:文件打开失败");
_exit(EXIT_FAILURE);
}
char buf[64];
snprintf(buf, sizeof(buf), "子进程PID=%d | 1~100的和 = %d\n", getpid(), sum);
ssize_t write_len = write(fd, buf, strlen(buf));
if (write_len < 0) {
perror("自定义任务:文件写入失败");
close(fd);
_exit(EXIT_FAILURE);
}
close(fd);
printf("子进程PID=%d 自定义任务执行完成,结果已写入custom_task_result.txt\n", getpid());
_exit(EXIT_SUCCESS); // 自定义任务正常退出
}
int main() {
// 定义3个子进程的任务列表
ChildTask tasks[] = {
{0, TASK_LS, "执行ls -l命令", 0},
{0, TASK_PWD, "执行pwd命令", 0},
{0, TASK_CUSTOM, "计算1~100的和", 0}
};
int task_count = sizeof(tasks) / sizeof(tasks[0]); // 子进程数量
int status;
int recycled_count = 0; // 已回收的子进程数
// 父进程调整优先级,nice值+5,降低优先级
if (nice(5) == -1) {
perror("父进程优先级调整失败");
}
printf("父进程PID=%d 优先级调整完成,开始创建%d个子进程\n", getpid(), task_count);
// 循环创建多个子进程
for (int i = 0; i < task_count; i++) {
pid_t pid = fork();
if (pid < 0) {
perror("fork创建子进程失败");
// 某个子进程创建失败,继续创建剩余子进程
continue;
}
if (pid == 0) { // 子进程逻辑
printf("子进程PID=%d 开始执行任务:%s\n", getpid(), tasks[i].desc);
// 根据任务类型执行不同逻辑
switch (tasks[i].type) {
case TASK_LS:
// 程序替换:执行ls -l,execlp自动搜索PATH
execlp("ls", "ls", "-l", NULL);
// execlp执行成功不会返回,以下仅失败时执行
perror("子进程ls命令执行失败");
_exit(EXIT_FAILURE);
case TASK_PWD:
// 程序替换:执行pwd
execlp("pwd", "pwd", NULL);
perror("子进程pwd命令执行失败");
_exit(EXIT_FAILURE);
case TASK_CUSTOM:
// 执行自定义任务
custom_child_task();
break;
default:
fprintf(stderr, "子进程PID=%d 无效任务类型\n", getpid());
_exit(EXIT_FAILURE);
}
} else { // 父进程记录子进程信息
tasks[i].pid = pid;
printf("父进程已创建子进程PID=%d,任务:%s\n", pid, tasks[i].desc);
}
}
// 父进程非阻塞循环回收所有子进程
printf("\n父进程开始非阻塞回收子进程...\n");
while (recycled_count < task_count) {
// 遍历所有子进程,逐个非阻塞检查是否退出
for (int i = 0; i < task_count; i++) {
if (tasks[i].pid <= 0 || tasks[i].is_recycled) {
continue; // 跳过创建失败或已回收的子进程
}
// WNOHANG:非阻塞模式,子进程未退出则立即返回0
pid_t ret = waitpid(tasks[i].pid, &status, WNOHANG);
if (ret < 0) { // waitpid调用失败
fprintf(stderr, "waitpid回收子进程PID=%d失败:%s\n",
tasks[i].pid, strerror(errno));
tasks[i].is_recycled = 1;
recycled_count++;
} else if (ret > 0) { // 成功回收子进程
tasks[i].is_recycled = 1;
recycled_count++;
// 解析子进程退出状态
if (WIFEXITED(status)) {
printf("回收子进程PID=%d(任务:%s),正常退出,退出码:%d\n",
tasks[i].pid, tasks[i].desc, WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("回收子进程PID=%d(任务:%s),被信号终止,信号编号:%d\n",
tasks[i].pid, tasks[i].desc, WTERMSIG(status));
}
}
// ret == 0:子进程未退出,不处理
}
// 模拟父进程等待期间执行其他任务,每500ms轮询一次
printf("父进程等待中,已回收%d/%d个子进程...\n",
recycled_count, task_count);
usleep(500000); // 休眠500毫秒
}
printf("\n父进程已回收所有子进程,程序执行完毕\n");
return 0;
}
|
1.9.2. 编译及测试¶
以上函数实例代码在system_programing/multiprocess/sources/multiprocess.c文件中, 使用如下命令即可编译测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # 以下操作在system_programing/multiprocess代码目录进行
make
# 运行程序
./build/multiprocess_demo
# 信息输出如下
父进程PID=9429 优先级调整完成,开始创建3个子进程
父进程已创建子进程PID=9430,任务:执行ls -l命令
子进程PID=9430 开始执行任务:执行ls -l命令
父进程已创建子进程PID=9431,任务:执行pwd命令
子进程PID=9431 开始执行任务:执行pwd命令
父进程已创建子进程PID=9432,任务:计算1~100的和
父进程开始非阻塞回收子进程...
父进程等待中,已回收0/3个子进程...
子进程PID=9432 开始执行任务:计算1~100的和
子进程PID=9432 开始执行自定义任务:计算1~100的和并写入文件
子进程PID=9432 自定义任务执行完成,结果已写入custom_task_result.txt
/home/guest/lubancat_rk_code_storage/base_linux/system_programing/multiprocess
total 16
drwxrwxr-x 2 guest guest 4096 Mar 10 06:02 build
-rw-r--r-- 1 guest guest 39 Mar 10 06:02 custom_task_result.txt
-rw-rw-r-- 1 guest guest 1588 Mar 10 06:02 Makefile
drwxrwxr-x 2 guest guest 4096 Mar 10 05:40 sources
回收子进程PID=9430(任务:执行ls -l命令),正常退出,退出码:0
回收子进程PID=9431(任务:执行pwd命令),正常退出,退出码:0
回收子进程PID=9432(任务:计算1~100的和),正常退出,退出码:0
父进程等待中,已回收3/3个子进程...
父进程已回收所有子进程,程序执行完毕
#查看自定义任务的结果
cat custom_task_result.txt
#信息输出如下
子进程PID=9432 | 1~100的和 = 5050
|
运行结果解析:
父进程先调整优先级,然后创建3个子进程;
子进程分别执行 ls、pwd、自定义计算任务;
父进程非阻塞轮询回收所有子进程,期间打印等待状态;
自定义任务的结果会写入custom_task_result.txt文件。
注意事项:
子进程退出优先使用_exit,避免调用exit刷新缓冲区导致资源重复释放,引发程序异常;
exec系列函数执行成功后无返回值,需在调用后紧跟错误处理代码,排查程序替换失败问题;
普通用户无法降低进程nice值,实操中建议仅调高nice值降低优先级,避免权限报错;
父进程必须回收子进程资源,长时间不回收会产生僵尸进程,占用系统进程号资源,影响系统运行。