
11. 文字显示¶
本章代码所在的位置: lubancat_rk_code_storage/base_linux/screen/char/
在前面的章节中,我介绍了framebuffer和drm的应用开发
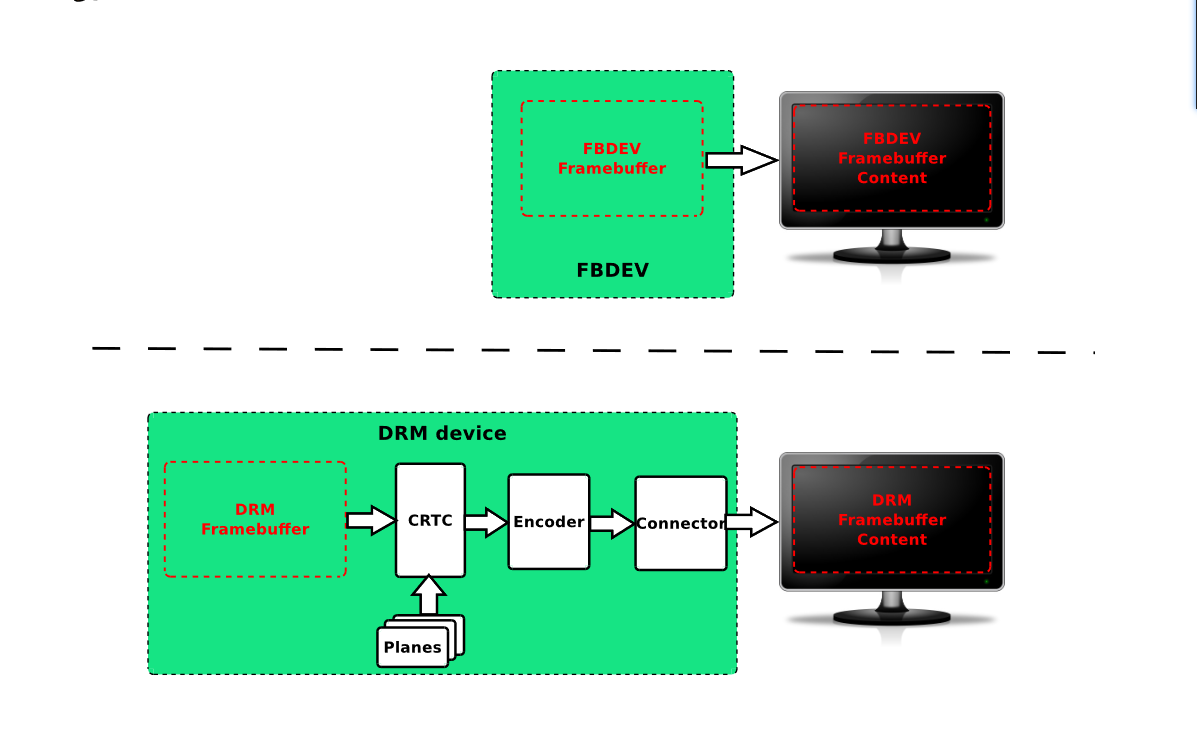
从framebuffer和drm的框架图,我们可以看到,framebuffer和drm的出发点和终点都一致:
出发点:framebuffer - - - -> 终点:屏幕输出
在操作屏幕上,同样也是操作framebuffer就可以控制屏幕的输出。
而文字,图像的输出就是通过改变framebuffer(一段内存)就可以实现的, 在后面的显示文字的实验中,我会使用上一节drm的project来进行实验。 (可以跳过繁杂的drm设置以及分层设计,从而进行屏幕的修改, framebuffer的使用方法也差不多)
11.1. 显示ASCII字符(8x16)¶
在本章的实验中,我们实现的功能是,在屏幕中显示256个ASCII字符
11.1.1. 实现方法¶
要在屏幕上显示一个 ASCII 字符,需要找到字符对应的点阵。 在Linux内核源码中 kernel/lib/fonts/ ,里面有多种大小的ASCII字符的数组表, 里面以数组形式保存各个字符的点阵。如下图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | root@ubuntu_135:~/rk/kernel/lib/fonts# tree
.
├── font_10x18.c
├── font_6x10.c
├── font_6x11.c
├── font_7x14.c
├── font_8x16.c
├── font_8x8.c
├── font_acorn_8x8.c
├── font_mini_4x6.c
├── font_pearl_8x8.c
├── fonts.c
├── font_sun12x22.c
├── font_sun8x16.c
├── Kconfig
└── Makefile
|
我们打开font_8x16.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #include "font.h"
const unsigned char fontdata_8x16[FONTDATAMAX] = {
/* 0 0x00 '^@' */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
/* 1 0x01 '^A' */
0x00, /* 00000000 */
0x00, /* 00000000 */
}
|
可以看到字符是由数组组成的,一个字符由16个字节组成。
我们可以观察一下 ‘A’ —它位于第65个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | /* 65 0x41 'A' */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x10, /* 00010000 */
0x38, /* 00111000 */
0x6c, /* 01101100 */
0xc6, /* 11000110 */
0xc6, /* 11000110 */
0xfe, /* 11111110 */
0xc6, /* 11000110 */
0xc6, /* 11000110 */
0xc6, /* 11000110 */
0xc6, /* 11000110 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
|
我们把后面的字符用空格键隔开,如下图,可以看到每个字节表示字符的一行,因此在屏幕上显示字符的方法就很明显了。
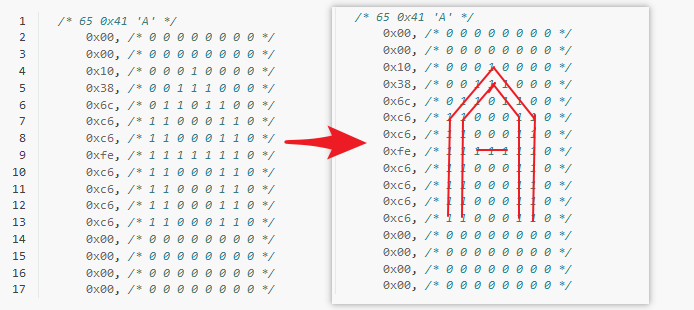
显示字符的方法:
循环获取字符的一行
判断每一位,如果是1就描点
循环16行,就可以完整的显示一个字符
11.1.2. 实验¶
本次实验基于drm章节的最后一个内容—project进行修改,framebuffer也同样可以使用。
代码位置及结构如下:
1 | lubancat/base_linux/screen/char/font
|
1 2 3 4 5 6 7 8 9 10 11 12 | #文件结构
.
|-- Makefile #编译
|-- includes
| |-- drm-core.h #drm头文件
| `-- font.h #字体头文件
`-- sources
|-- main.c #main函数
|-- drm-core.c #drm的初始化以及调用
`-- font.c #字符数组文件
2 directories, 6 files
|
编译及运行:
1 2 3 4 5 | #编译
make
#运行
./test
|
实验现象:
屏幕变成深蓝色
屏幕显示四行ASCII字符
11.1.3. 程序分析¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | #include "drm-core.h"
#include "font.h"
uint32_t color_table[6] = {RED,GREEN,BLUE,BLACK,WHITE,BLACK_BLUE};
//描点函数
void show_pixel(uint32_t x , uint32_t y , uint32_t color)
{
if(x > buf.width || y > buf.height){
printf("wrong set\n");
}
buf.vaddr[ y*buf.width + x] = color;
}
//单个8x16字符的描写
void show_8x16(uint32_t x , uint32_t y , uint32_t color, unsigned char num)
{
int i,j;
unsigned char dot;
for(i = 0 ; i<16 ; i++){
dot = fontdata_8x16[num*16+i];
for(j=0;j<8;j++){
if(dot & 0x80)
show_pixel(x+j,y+i,color);
dot = dot << 1;
}
}
}
//256个ascii字符打印出来
void show_string(uint32_t color)
{
int i,j;
int row=64;
int x_offset = (buf.width - 64*8)/2;
int y_offset = (buf.height - 16*4)/2;
for(j=0;j<4;j++){
for(i=0;i<64;i++){
show_8x16(i*8+x_offset,16*j+y_offset,color,i+j*64);
}
}
}
int main(int argc, char **argv)
{
int i;
//初始化屏幕
drm_init();
//屏幕颜色变化---浅蓝
for(i = 0;i< buf.width*buf.height;i++)
buf.vaddr[i] = BLACK_BLUE;
//屏幕中间显示字体
show_string(WHITE);
//获取字符--enter键进入下一步
getchar();
drm_exit();
return 0;
}
|
第5-13行,描点函数
第16-29行,单个字符的显示,将字符的点覆盖framebuffer,先读取一行然后与最高位进行比对, 循环八次,完成一个字节的比对,一个字符有16字节,循环16次完成一个字符的扫描。
第33-44行,将256个ASCII字符分成四行打印到屏幕的中间。
第46-59行,初始化drm,设置背景的颜色,然后显示256个字符,注销drm
frambuffer的操作只需要把drm_init 和 drm_exit换成相应的函数,即可达到相应的效果。
11.2. 显示汉字(8x16)¶
11.2.1. 实现方法¶
实现方法和上文的字符的实现差不多,但是汉字文化博大精深, 不是区区一个字节就能全部汉字都标号,因此,我们需要其他的能获得汉字编码的编码字符集, GBK2312和Unicode是我们日常互联网上常见的两种包含汉字的字符集。
GBK2312 —-中国在1980年发布了第一个汉字编码标准,也即 GB2312 ,全称 《信息交换用汉字编码字符集·基本集》, 通常简称 GB (“国标”汉语拼音首字母), 共收录了 6763 个常用的汉字和字符,此标准于次年5月实施,它满足了日常 99% 汉字的使用需求。
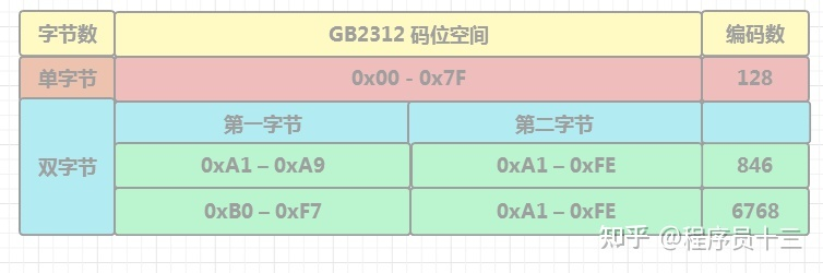
为了兼容ASCII字符,GBK2312有两种模式,一种是单字节ASCII,另一种是双字节汉字
单字节ASCII —–>包含128个ASCII字符
双字节汉字 —–> 第一字节为区位,第二个字节为区内编号,它们的范围如上图
Unicode —-统一码,也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。 Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码, 以满足跨语言、跨平台进行文本转换、处理的要求。
如果把各种文字编码形容为各地的方言,那么Unicode就是世界各国合作开发的一种语言。 在这种语言环境下,不会再有语言的编码冲突,在同屏下,可以显示任何语言的内容, 这就是Unicode的最大好处。就是将世界上所有的文字用2个字节统一进行编码。 那样,像这样统一编码,2个字节就已经足够容纳世界上所有的语言的大部分文字了。
现在用的是UCS-2,即2个字节编码,而UCS-4是为了防止将来2个字节不够用才开发的。
目前,在互联网上基本上都是使用Unicode编码的字符集。
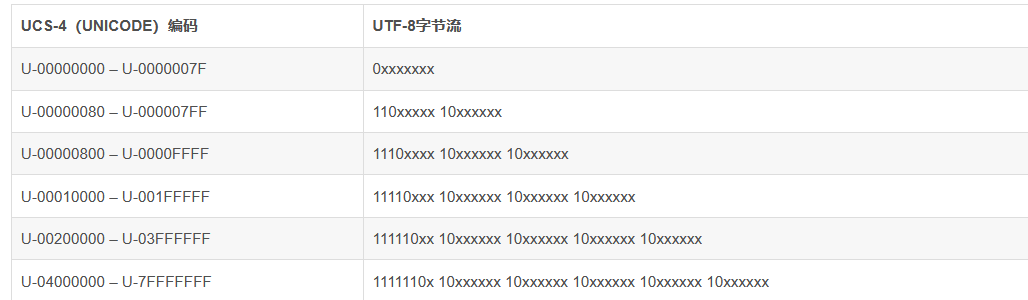
UTF-8 ——是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符, 而且其编码中的第一个字节仍与ASCII相容, 使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。我们的互联网,电脑都是使用utf-8编码进行传输
如果所有字符都用16位的Unicode来进行编码的话,会导致在网络传输中占用大头的ASCII字符会翻倍传输, 这样就会占用大量的带宽,不利于便捷的网络传输,因此,科学家们想到用可变编码的方式, 将Unicode的编码转换为长度可变的方式,在传输ASCII字符时仅需一个字节,其他的字符可需两个以上的字节, 这样可以有效解决网络拥堵,以及带宽占用的问题。
可阅读下列文章了解更多关于汉字编码的信息 (https://blog.csdn.net/m0_46426259/article/details/124087911)
而在本次实验中我们使用的是HZK16,是一个以GBK2312编码的文件,我们通过区码,区内编码,获得文字的字形数组, 然后通过数组,用描点函数描出来即可
11.2.2. 实验¶
本次实验基于上一节内容进行修改,framebuffer也同样可以使用
1 | lubancat/base_linux/screen/char/chinese_16x16
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #文件结构
.
|-- Makefile #编译
|-- includes
| |-- drm-core.h #drm头文件
| `-- font.h #字体头文件
`-- sources
|-- main.c #main函数
|-- drm-core.c #drm的初始化以及调用
`-- font.c #字符数组文件
2 directories, 6 files
#编译
make
#运行
./test
#实验现象
1. 屏幕变成深蓝色
2. 屏幕显示四行ASCII字符
3. 在屏幕的底部会有“野火科技”的中文显示
4. “野火科技”的底部会有红色的野火官网
|
11.2.3. 程序分析¶
以下展示部分为与上一个实验差异的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
//根据GBK2312码,显示一个汉字
void show_chinese(int x, int y, unsigned char *str)
{
unsigned int area = str[0] - 0xA1;
unsigned int where = str[1] - 0xA1;
unsigned char *dots = hzkmem + (area * 94 + where)*32;
unsigned char byte;
int i, j, b;
for (i = 0; i < 16; i++){
for (j = 0; j < 2; j++){
byte = dots[i*2 + j];
for (b = 7; b >=0; b--){
if (byte & (1<<b))
show_pixel(x+j*8+7-b, y+i, WHITE);
}
}
}
}
|
第2-21行,
show_chinese()该函数通过传入一个两字节的GBK2312编码格式的数组 然后进行解码,获取文字的点阵,然后显示出来。第5-6行,获取区码以及区内编码,从上面的GBK2312的编码图可以看到, 汉字的区码有两个
0xA1-0XA9和0xB0-0XF7, 区内编码都是0xA1-0XFE,而HZK16的编码是汉字,如果需要从0x0000-0xffff的所有内容都加进去的话,文件会很大, 因此人们把无关的ASCII编码以及无关汉字的编码的文字数组删除,通过区码和区内编码进行检索汉字, 所以,我们需要在区码和区内编码都减去0xa1以获取HZK16的汉字数组编号 因此在HZK16文件中区码变成了0x0-0X09和0x0f-0X56区内编码0x00-0x5d,可以看到一个区包含了94个区内编码第7行,算出所需的汉字编码在文件中的位置,hzkmem是一个地址,指向HZK16这个文件的首地址, 然后偏移量为 (区码*94+区内编码)*32 (32是每个汉字由32个字节表示);
后面的汉字画函数与上文的显示英语字符的画点十分相似,这里就不过多赘述了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | #include "drm-core.h"
#include "font.h"
int fd_hzk16;
struct stat hzk_stat;
unsigned char *hzkmem;
int main(int argc, char **argv)
{
int i;
//野火科技
unsigned char YHKJ[8] = {0XD2,0XB0,0XBB,0XF0,0XBF,0XC6,0XBC,0XBC};
//官网
unsigned char *web = "www.embedfire.com";
//初始化
drm_init();
//屏幕颜色变化---浅蓝
for(i = 0;i< buf.width*buf.height;i++)
buf.vaddr[i] = BLACK_BLUE;
//打开汉字库
fd_hzk16 = open("file/HZK16", O_RDONLY);
if (fd_hzk16 < 0){
printf("can't open HZK16\n");
return -1;
}
//获取文件长度
if(fstat(fd_hzk16, &hzk_stat)){
printf("can't get fstat\n");
return -1;
}
//将整个文件映射到内存里
hzkmem = (unsigned char *)mmap(NULL , hzk_stat.st_size, PROT_READ, MAP_SHARED, fd_hzk16, 0);
if (hzkmem == (unsigned char *)-1){
printf("can't mmap for hzk16\n");
return -1;
}
//显示255个字母
show_string(WHITE);
//显示中文“野火科技”
for(i = 0 ;i<4;i++)
show_chinese(330+i*16,1000,YHKJ+i*2);
//显示网站"www.embedfire.com"
for(i=0;i<strlen(web);i++){
show_8x16(290+i*8,1025,RED,web[i]);
}
//按键后进入
getchar();
//drm退出
drm_exit();
return 0;
}
|
第20-24行,打开HZK16的文件,获取文件ID
第25-29行,获取HZK16的文件大小,方便把整个文件映射到内存里
第30-35行,将整个文件映射到内存上,我们可以通过读取内存来获取各个汉字的数组
第38-40行,显示中文,显示的中文需要定义包含GBK2312编码的汉字数组
除了直接定义GBK2312的数组,我们还可以通过转换的方法将Unicode编码的数组转换成GBK2312中使用, 下列文章有详细的介绍,在这里我就不再过多的讲述了。
11.3. 矢量文字(freetype)¶
以上的显示文字的方法都比较笨拙,都是通过编号去寻找文字的数组,然后通过数组用描点函数描出来, 而且显示的函数都只有固定的文字大小,如果想用不同的大小的文字还需要切换不同的库进行使用。 这样的方法不利于我们的开发。
矢量字体—大小可以自行设置,可以设置旋转等, 非常适合我们使用,大部分的字形文件(.ttc)以Unicode的形式编码,方便我们的板卡进行使用
这是freetype的官网,里面会有详细的介绍以及例子,下面我的讲解可能只是freetype的冰山一角, 但是也足够我们平时使用,如果想要进阶学习的话,可以前往官网进行进一步的学习。
11.3.1. 实现方法¶
矢量文字是通过从字形文件中获取字形结构,根据我们设置字形大小,旋转角等,然后通过渲染的方式获得文字的描点数组。 因此更改字形文件就可以显示出不同样式的文字,比如宋体,楷书等。
生成矢量字体分三步:
确定字形(由字形文件提供)
使用数学曲线(贝塞尔曲线)连接头键点(渲染)
填充闭合区线内部空间(渲染)
Freetype 是开源的字体引擎库,它提供统一的接口来访问多种字体格式文件,从而实现矢量字体显示。 我们只需要调用对应的 API 接口,提供字体文件,就可以让 freetype 库帮我们取出关键点、 实现闭合曲线,填充颜色,达到显示矢量字体的目的。
后面的实验我们会使用 simsun.ttc 新宋体字形文件,该文件支持Unicode检索字形,我们直接可以使用utf-8转Unicode调用
11.3.1.1. 矢量文字¶
Freetype的矢量文字有以下参数(这里以横向的为例,纵向的可以去官网查看了解)
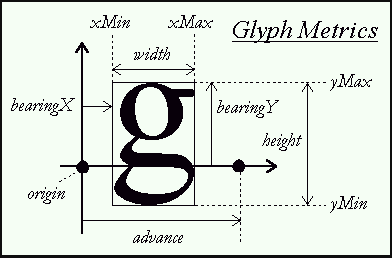
origin :字形文字的灵魂,所有的字形文件的渲染都是基于原点, 在字形的结构体中,所有的数据都是基于原点的数据进行偏移,如果我们不定义的话,原点为(0,0)。
advance :可以根据”font_size”调节
bearingX :原点到显示区域(渲染区域)的第一列的x轴偏移量(可对应下文的
slot->bitmap_left)bearingY :原点到显示区域(渲染区域)的第一行的y轴偏移量(可对应下文的
slot->bitmap_top)width :显示区域(渲染区域)一行的长度(可对应下文的
bitmap->width)height :显示区域(渲染区域)高的长度(可对应下文的
bitmap->rows)xMin :可用这个来计算字符串框,在字形结构体中的数值为原点的偏移量
xMax :可用这个来计算字符串框,在字形结构体中的数值为原点的偏移量
yMin :可用这个来计算字符串框,在字形结构体中的数值为原点的偏移量
yMax :可用这个来计算字符串框,在字形结构体中的数值为原点的偏移量
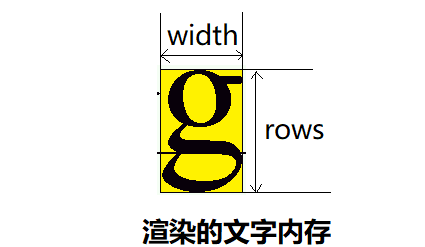
上图为渲染出来的buffer区域,我们就是利用这些buffer区域进行屏幕的显示
11.3.2. 显示单个矢量字体¶
本实验基于基于freetype的教程以及drm章节的project实验而写,更多关于freetype的教程可以点击下列网站进行学习
https://freetype.org/freetype2/docs/design/index.html
1 | lubancat/base_linux/screen/char/freetype/
|
1 2 3 4 5 6 7 8 9 10 11 12 | #文件组成
.
|-- Makefile
|-- file
| `-- simsun.ttc #新宋体
|-- includes
| |-- drm-core.h
| `-- font.h
`-- sources
|-- drm-core.c
|-- font.c
`-- main.c #main函数
|
因为本次实验是要使用到freetype库的,所以,我们在编译的时候需要把库加到里面,而LubanCat系列-ubuntu系统自带这些库, 所以,在编译的时候应用即可,Makefile文件中已经加入了库编译选项,直接使用即可。
1 | 在GCC的后面加入`pkg-config --cflags freetype2` `pkg-config --libs freetype2`
|
因为因为本次实验是要使用到math库的,所以,我们在编译的时候需要把库加到里面
1 | 在GCC的后面加入 -lm
|
11.3.2.1. 编译&运行¶
1 2 3 4 5 6 7 8 9 10 11 | #编译
make
#运行
./test
#实验现象
1. 屏幕上显示大字号的“野火科技”
2. “野火科技”的下面显示野火的官网地址"www.embedfire.com"
3. 官网地址的字母位置没有对齐
|
11.3.2.2. 程序分析¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | int utf_8_to_unicode_string(uint8_t *utf_8,uint16_t *word)
{
int len = 0;
int utf_8_size = strlen(utf_8);
int utf_8_len = 0;
uint16_t unicode[2];
while(utf_8_size > 0){
//1位utf_8转换为两位的unicode
if(utf_8[utf_8_len] < 0x80){
unicode[0] = 0;
unicode[1] = utf_8[utf_8_len];
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len ++;
utf_8_size--;
continue;
}
//2位utf_8转换为两位的unicode
else if(utf_8[utf_8_len] > 0xc0 & utf_8[utf_8_len] <0xe0){
unicode[1] = (utf_8[utf_8_len+1]&0x3f) | ((utf_8[utf_8_len]<< 6)& 0xc0 );
unicode[0] = ((utf_8[utf_8_len]>>2) & 0x07) ;
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len +=2;
utf_8_size -=2;
continue;
}
//3位utf_8转换为两位的unicode
else if(utf_8[utf_8_len] > 0xe0 & utf_8[utf_8_len]<0xf0){
unicode[1] = (utf_8[utf_8_len+2]&0x3f) | ((utf_8[utf_8_len+1] << 6)& 0xc0);
unicode[0] = ((utf_8[utf_8_len+1]>>2)&0x0f) | ((utf_8[utf_8_len] <<4)& 0xf0) ;
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len +=3;
utf_8_size -=3;
continue;
}
//四位的utf_8转换需要三到四位的unicode码,这样不方便操作,
//中文基本都可以用三位utf_8表示,因此,四位及以后的解码就没必要
else
return -1;
}
return len;
}
|
该函数为将三位及三位以内的utf-8字符串转为两位的Unicode字符串–方便后面调用字形文件
转码的原理可看下图,这里不过多阐述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | #include "drm-core.h"
#include <ft2build.h>
#include <math.h>
#include FT_FREETYPE_H
#include FT_GLYPH_H
uint32_t color_table[6] = {RED,GREEN,BLUE,BLACK,WHITE,BLACK_BLUE};
//显示像素点
void show_pixel(uint32_t x , uint32_t y , uint32_t color)
{
if(x > buf.width || y > buf.height)
printf("wrong set\n");
buf.vaddr[ y*buf.width + x] = color;
}
int utf_8_to_unicode_string(uint8_t *utf_8,uint16_t *word)
{
int len = 0;
int utf_8_size = strlen(utf_8);
int utf_8_len = 0;
uint16_t unicode[2];
while(utf_8_size > 0){
//1位utf_8转换为两位的unicode
if(utf_8[utf_8_len] < 0x80){
unicode[0] = 0;
unicode[1] = utf_8[utf_8_len];
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len ++;
utf_8_size--;
continue;
}
//2位utf_8转换为两位的unicode
else if(utf_8[utf_8_len] > 0xc0 & utf_8[utf_8_len] <0xe0){
unicode[1] = (utf_8[utf_8_len+1]&0x3f) | ((utf_8[utf_8_len]<< 6)& 0xc0 );
unicode[0] = ((utf_8[utf_8_len]>>2) & 0x07) ;
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len +=2;
utf_8_size -=2;
continue;
}
//3位utf_8转换为两位的unicode
else if(utf_8[utf_8_len] > 0xe0 & utf_8[utf_8_len]<0xf0){
unicode[1] = (utf_8[utf_8_len+2]&0x3f) | ((utf_8[utf_8_len+1] << 6)& 0xc0);
unicode[0] = ((utf_8[utf_8_len+1]>>2)&0x0f) | ((utf_8[utf_8_len] <<4)& 0xf0) ;
word[len] = (unicode[0]<<8) | unicode[1];
len ++;
utf_8_len +=3;
utf_8_size -=3;
continue;
}
//四位的utf_8转换需要三到四位的unicode码,这样不方便操作,
//中文基本都可以用三位utf_8表示,因此,四位及以后的解码就没必要
else
return -1;
}
return len;
}
void draw_bitmap( FT_Bitmap* bitmap,FT_Int x_ori,FT_Int y_ori)
{
FT_Int x, y;
FT_Int x_count, y_count;
unsigned char show;
uint32_t buffer_size = bitmap->width * bitmap->rows;
uint8_t buffer[buffer_size];
uint32_t color;
FT_Int x_max = x_ori + bitmap->width;
FT_Int y_max = y_ori + bitmap->rows;
memcpy(buffer,bitmap->buffer,buffer_size);
for ( y = y_ori, y_count = 0; y < y_max; y++, y_count++ ){
for ( x = x_ori, x_count = 0; x < x_max; x++, x_count++ ){
if ( x < 0 || y < 0 || x >= buf.width || y >= buf.height )
continue;
//buf里的图像是存放八位的梯度值,需要自己转换成颜色才能显示,否则会表现蓝色
show = buffer[y_count * bitmap->width + x_count];
//梯度大于零,转换为相同强度的白色
if(show > 0)
color = (show&0xff)|((show&0xff)<<8)|((show&0xff)<<16);
//直接为黑色,可以省略
else
color=0;
//像素显示函数
show_pixel(x, y , color);
}
}
}
int freetype_set_char(FT_Face face , int lcd_x,int lcd_y ,int font_size,int angle_degree,uint16_t word)
{
FT_Matrix matrix;
FT_Vector pen;
int charIdx;
FT_GlyphSlot slot= face->glyph;;
double angle;
int error;
FT_Set_Pixel_Sizes(face, font_size, 0);
//设置旋转
angle = (1.0 * angle_degree/360) * 3.14159 * 2;
/* set up matrix */
matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L );
matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L );
matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L );
matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L );
/* 转换:transformation */
FT_Set_Transform(face, &matrix, 0);
/*下列的三条可替换FT_Load_Char使用*/
// charIdx = FT_Get_Char_Index(face,word);
// FT_Load_Glyph(face,charIdx, FT_LOAD_DEFAULT);
// FT_Render_Glyph(face->glyph, FT_RENDER_MODE_NORMAL);
error = FT_Load_Char( face, word, FT_LOAD_RENDER );
if (error){
printf("FT_Load_Char error\n");
return -1;
}
draw_bitmap( &slot->bitmap,lcd_x, lcd_y);
return 0;
}
int main(int argc, char **argv)
{
int i,j,count;
FT_Library library;
FT_Face face;
int error;
int font_size = 180;
int angle_degree = 0;
unsigned char str1[] = "野火科技A";
unsigned char str2[] = "www.embedfire.com";
unsigned char str3[] = "abcdefghijklmnopq";
uint16_t unicode[20];
int unicode_size = 0;
drm_init();
/* 显示矢量字体 */
error = FT_Init_FreeType( &library ); /* initialize library */
/* error handling omitted */
error = FT_New_Face( library, "file/simsun.ttc", 0, &face ); /* create face object */
unicode_size = utf_8_to_unicode_string(str1,unicode);
// 显示野火科技
for(i = 0 ; i<unicode_size;i++)
freetype_set_char(face,0+font_size*i,640,font_size,angle_degree,unicode[i] );
// 显示官网
unicode_size = utf_8_to_unicode_string(str2,unicode);
for(i = 0 ; i<unicode_size;i++)
freetype_set_char(face,0+font_size/6*i,820,font_size/3,angle_degree,unicode[i] );
getchar();
drm_exit();
return 0;
}
|
第23行,初始化Freetype
第24-25行,打开字形文件,创建face
第26,33,38行,分别将UTF-8编码得str1,str2,str3转换为两位的unicode编码的数组
第29-30,34-35,39-40行,设置大小循环打印矢量文字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | int freetype_set_char(FT_Face face , int lcd_x,int lcd_y ,int font_size,int angle_degree,uint16_t word)
{
FT_Matrix matrix;
FT_Vector pen;
int charIdx;
FT_GlyphSlot slot= face->glyph;;
double angle;
int error;
FT_Set_Pixel_Sizes(face, font_size, 0);
//设置旋转
angle = (1.0 * angle_degree/360) * 3.14159 * 2;
/* set up matrix */
matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L );
matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L );
matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L );
matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L );
/* 转换:transformation */
FT_Set_Transform(face, &matrix, 0);
/*下列的三条可替换FT_Load_Char使用*/
// charIdx = FT_Get_Char_Index(face,word);
// FT_Load_Glyph(face,charIdx, FT_LOAD_DEFAULT);
// FT_Render_Glyph(face->glyph, FT_RENDER_MODE_NORMAL);
error = FT_Load_Char( face, word, FT_LOAD_RENDER );
if (error){
printf("FT_Load_Char error\n");
return -1;
}
draw_bitmap( &slot->bitmap,lcd_x, lcd_y);
return 0;
}
|
第10行,设置字体的大小
第11-20行,设置旋转,通过改变
angle_degree就可以改变旋转的角度, 当然这几行代码可以不设置即可运行,在这里添加只是为了给大家讲解第27行,加载文字以及把文字渲染,该函数包含了第23-25行的功能, 具有读取文字表,加载字形数据,渲染字形数据。
第32行,将获得的字形文件描绘出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | void draw_bitmap( FT_Bitmap* bitmap,FT_Int x_ori,FT_Int y_ori)
{
FT_Int x, y;
FT_Int x_count, y_count;
unsigned char show;
uint32_t buffer_size = bitmap->width * bitmap->rows;
uint8_t buffer[buffer_size];
uint32_t color;
FT_Int x_max = x_ori + bitmap->width;
FT_Int y_max = y_ori + bitmap->rows;
memcpy(buffer,bitmap->buffer,buffer_size);
for ( y = y_ori, y_count = 0; y < y_max; y++, y_count++ ){
for ( x = x_ori, x_count = 0; x < x_max; x++, x_count++ ){
if ( x < 0 || y < 0 || x >= buf.width || y >= buf.height )
continue;
//buf里的图像是存放八位的梯度值,需要自己转换成颜色才能显示,否则会表现蓝色
show = buffer[y_count * bitmap->width + x_count];
//梯度大于零,转换为相同强度的白色
if(show > 0)
color = (show&0xff)|((show&0xff)<<8)|((show&0xff)<<16);
//直接为黑色,可以省略
else
color=0;
//像素显示函数
show_pixel(x, y , color);
}
}
}
|
第6行,获取渲染出来的buffer占用内存大小
第7行,创建一个相同大小的内存空间用于存放
第9-10行,获取以x_ori和y_ori为内存的起点的x轴和y轴的最大值
第12行,将buffer复制到刚刚创建的内存中
第14-32行,循环把buffer里的点打出来
第21-26行,在freetype生成的字形文字的内存中是没有颜色分量,只有8位的强度梯度, 即在文字的边缘会暗,文字的像素密集的地方都是最高值, 因此,如果我们想要其他颜色,需要自己替换,或者不做修改,直接传入到描点函数中(显示蓝色)
11.3.2.3. 总结¶
使用freetype生成矢量文字的步骤
获取你想要生成的矢量文字的编码(可以是GBK,unicode等)
初始化freetype
用freetype打开支持你生成的文字的编码的字形文件
设置文字大小
设置旋转角(可以忽略),原点位置
加载位图(可由三个函数联合替换)
根据位图的buffer,使用描点函数描点
11.3.3. freetype显示字符串¶
11.3.3.1. 问题复盘¶
在上一小节的实验现象中,英文的字符在y轴上会出现位置不正确的现象,这是为什么呢?
原因分析:
同一个字体大小渲染出来的文字的大小并不是一样的,我们可以在
draw_bitmap()这个函数中修改,增加显示出来的背景色即else{ color = RED;},修改后重新编译并执行, 可以发现不同字母的buffer大小是不一样的,而且每个字符都从左上角开始显示。
就像下图一样

方法:
前面有说过,原点是所有字体渲染的基点,也就是说, 只要每个字符的原点与上一个字符的(原点+advance)重合就可以让他们变得整齐
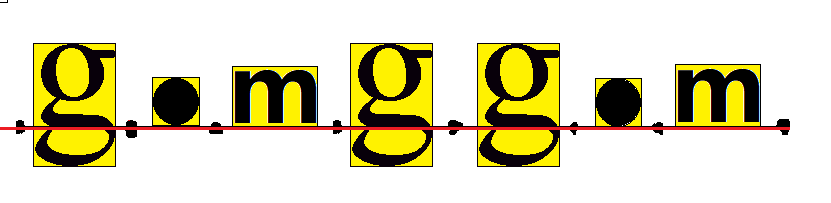
因此,如果我们想办法对齐原点就可以实现字符在y轴上的正确显示。
在上面的字形字符中,有个很重要的参数 yMax ,它位置是相对原点偏移的, 那么我们就可以通过把每个字符的显示区域上移 yMax 个高度, 让每个字形的原点在我们设定的y轴上进行对齐
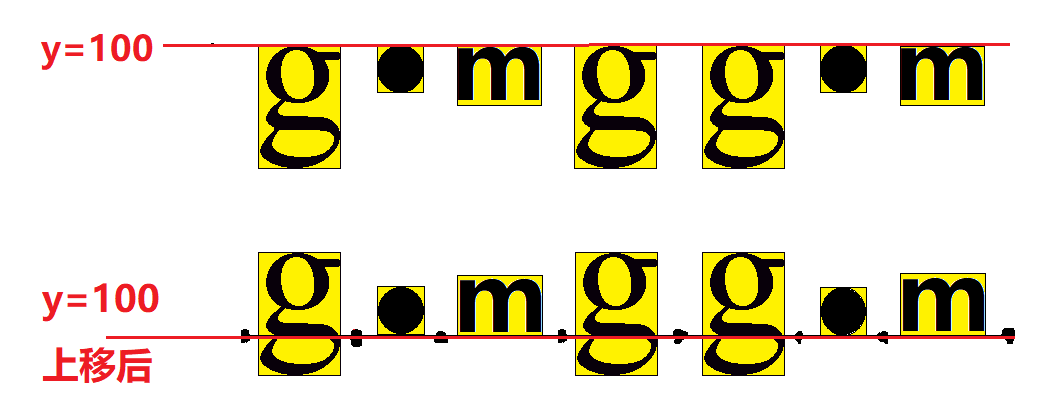
可以看到上移后每个字形都能得到对齐,那我们怎么获得 yMax 呢,如果我们没设置原点或者原点为0,那么,
yMax 相当于 slot->bitmap_top,所以我们可以修改 draw_bitmap 的函数达到刚刚所说的效果。
1 | draw_bitmap( &slot->bitmap,lcd_x,lcd_y-slot->bitmap_top);
|
由于上移后会出现只能从连续的原点轴上生成字体,无法从左上角处确定文字的位置,而下面的这个实验将解决这个问题
11.3.3.2. 显示字符串实验¶
1 | lubancat/base_linux/screen/char/freetype_str/
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | int main(int argc, char **argv)
{
FT_Library library;
FT_Face face;
FT_BBox bbox;
int i,j,error;
//字体大小
int font_size = 180;
uint8_t str[] = "野火科技";
uint8_t str1[] = "www.embedfire.com";
uint16_t unicode[10];
uint16_t unicode1[10];
uint32_t u_len;
uint32_t u1_len;
//清空内容
memset(f_name.unicode,0,sizeof(f_name.unicode));
memset(f_str[0].unicode,0,sizeof(f_str[0].unicode));
memset(f_str[1].unicode,0,sizeof(f_str[1].unicode));
drm_init();
//打开文件,在linux中文件以utf-8编码的形式存在
f_name.fd = open("file/name.txt", O_RDONLY);
//获取文件大小
fstat(f_name.fd, &f_name.stat);
//将文件中的内容全部映射出来
f_name.mem = (unsigned char *)mmap(NULL , f_name.stat.st_size, PROT_READ, MAP_SHARED, f_name.fd, 0);
//utf_8转unicode
f_name.len=utf_8_to_unicode_string(f_name.mem,f_name.unicode);
u_len = utf_8_to_unicode_string(str,unicode);
u1_len = utf_8_to_unicode_string(str1,unicode1);
//初始化freetype
error = FT_Init_FreeType( &library );
//读取文字文件,创建face
error = FT_New_Face( library, "file/simsun.ttc", 0, &face );
//显示野火科技
FT_Set_Pixel_Sizes(face, 80, 0);
compute_string_bbox(face, unicode,u_len,&bbox );
display_string(face, unicode,u_len, 200, 1000,&bbox);
//显示官网
FT_Set_Pixel_Sizes(face, font_size/3, 0);
compute_string_bbox(face,unicode1,u1_len,&bbox);
display_string(face, unicode1,u1_len ,120, 1100,&bbox);
//显示欢迎来到野火科技
FT_Set_Pixel_Sizes(face, 60, 0);
compute_string_bbox(face, f_name.unicode,f_name.len,&bbox);
display_string(face, f_name.unicode, f_name.len,135, 500,&bbox);
getchar();
drm_exit();
return 0;
}
|
第17-20行,清空unicode的缓冲区
第23-30行,打开文件,从文件中获取utf-8编码的文字,并将其转换为unicode码,传入缓冲区中
第31-32行,将两个utf-8编码的字符串转换为unicode编码
第34-37行,初始化freetype
FT_Set_Pixel_Sizes设置文字大小compute_string_bbox获得所有的文字的边框,计算出可以包括所有文字的边框层,方便后面的平移使用display_string显示文字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | int compute_string_bbox(FT_Face face,uint16_t *str,int len, FT_BBox *abbox)
{
int i;
int error;
FT_BBox bbox;
FT_BBox glyph_bbox;
FT_Vector pen;
FT_Glyph glyph;
FT_GlyphSlot slot = face->glyph;
/* 初始化 */
bbox.xMin = bbox.yMin = 32000;
bbox.xMax = bbox.yMax = -32000;
/* 指定原点为(0, 0) */
pen.x = 0;
pen.y = 0;
/* 计算每个字符的bounding box */
/* 先translate, 再load char, 就可以得到它的外框了 */
for (i = 0; i < len; i++)
{
/* 转换:transformation */
FT_Set_Transform(face, 0, &pen);
/* 加载位图: load glyph image into the slot (erase previous one) */
error = FT_Load_Char(face, str[i], FT_LOAD_RENDER);
if (error){
printf("FT_Load_Char error\n");
return -1;
}
/* 取出glyph */
error = FT_Get_Glyph(face->glyph, &glyph);
if (error){
printf("FT_Get_Glyph error!\n");
return -1;
}
/* 从glyph得到外框: bbox */
FT_Glyph_Get_CBox(glyph, FT_GLYPH_BBOX_TRUNCATE, &glyph_bbox);
/* 更新外框 */
if ( glyph_bbox.xMin < bbox.xMin )
bbox.xMin = glyph_bbox.xMin;
if ( glyph_bbox.yMin < bbox.yMin )
bbox.yMin = glyph_bbox.yMin;
if ( glyph_bbox.xMax > bbox.xMax )
bbox.xMax = glyph_bbox.xMax;
if ( glyph_bbox.yMax > bbox.yMax )
bbox.yMax = glyph_bbox.yMax;
/* 计算下一个字符的原点: increment pen position */
pen.x += slot->advance.x;
}
/* return string bbox */
*abbox = bbox;
}
|
该函数的作用是是获得所有的字体的边框,然后计算出最小的可以包括所有文字字形的框,如下图所示
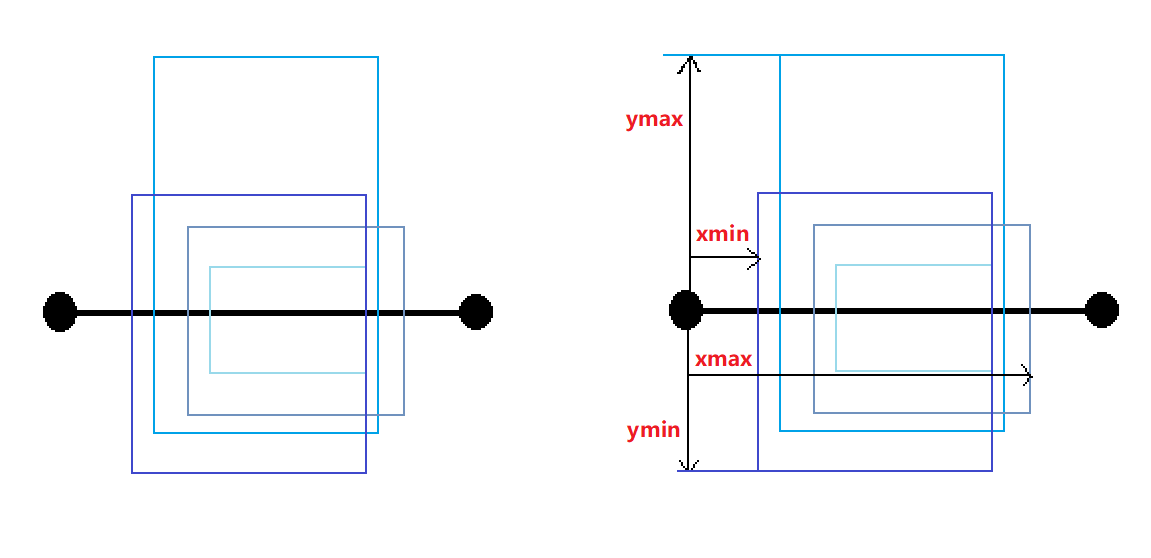
最小的框
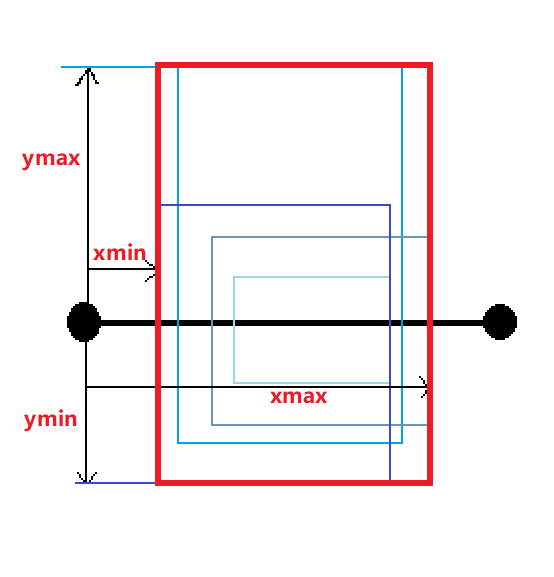
这些框的作用:当我们的一个框能够满足字符串内的所有字符大小的能力, 那么,我们把每个字符的框都以这个框作为标准,向下再移动ymax, 这样的话,我们就可以实现,在左上角确定整个字符串的位置

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | int display_string(FT_Face face, uint16_t *str,int len, int lcd_x, int lcd_y,FT_BBox *bbox)
{
int i;
int error;
FT_Vector pen;
FT_Glyph glyph;
FT_GlyphSlot slot = face->glyph;
FT_Matrix matrix;
int angle_degree = 0;
double angle;
/* 把LCD坐标转换为笛卡尔坐标 */
int x = lcd_x;
int y = buf.height - lcd_y;
//设置原点
pen.x = (x - bbox->xMin) * 64; /* 单位: 1/64像素 */
pen.y = (y - bbox->yMax) * 64; /* 单位: 1/64像素 */
/* 处理每个字符 */
for (i = 0; i < len; i++){
//设置旋转
angle = (1.0 * angle_degree/360) * 3.14159 * 2;
/* set up matrix */
matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L );
matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L );
matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L );
matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L );
/* 转换:transformation */
FT_Set_Transform(face, &matrix, &pen);
/* 加载位图: load glyph image into the slot (erase previous one) */
error = FT_Load_Char(face, str[i], FT_LOAD_DEFAULT|FT_LOAD_RENDER);
/* 显示内容 */
draw_bitmap(&slot->bitmap,slot->bitmap_left,
buf.height - slot->bitmap_top);
/* 计算下一个字符的原点: increment pen position */
pen.x += slot->advance.x;
// 竖向字体使用
// pen.y += slot->advance.y;
}
return 0;
}
|
该函数为让字符串在屏幕上显示
第13-15行,切换屏幕坐标系为笛卡尔坐标系
这是因为原点的位置是基于笛卡尔坐标系构建:
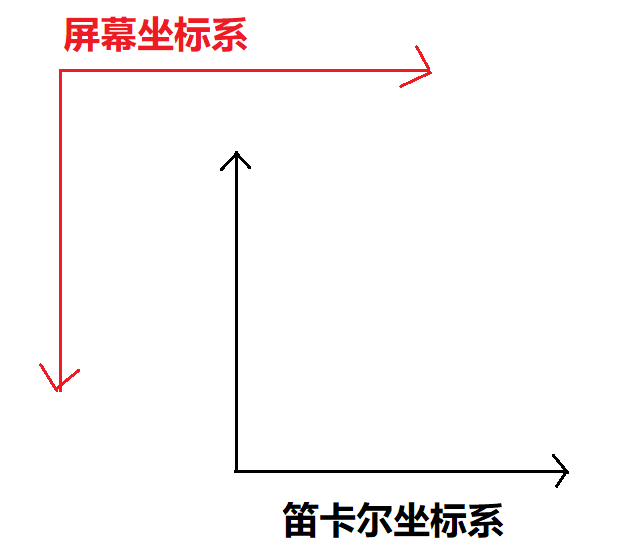
切换的方式就比较简单,x轴不变,y轴上就变成了屏幕纵向高度-屏幕坐标系y轴的
第16-18行,设置原点,x64是因为freetype在渲染的时候将像素点x轴和y轴放大64倍再进行渲染 (不然我们也看不到这么精细的文字),
bbox->xMin和bbox->yMax是从上面计算外框中获得的数据,这里是最大的外框,在笛卡尔坐标系中,减去一个正数, 相当于向左移动,以及向下移动, 在这里原点向左移动bbox->xMin个单位,是为了消除第一个字符的左边的部分空行, 原点向下移动,就是为了前面我所说的让文字显示在y轴下,让文字能在y分量以下显示。第20-36行,正常的设置字体
第37行,将笛卡尔坐标系换回屏幕坐标系再进行画图,下面是
bitmap_left和bitmap_top的关系图 在原点为(0,0)的情况下,bitmap_left= xMin ,bitmap_top= yMax
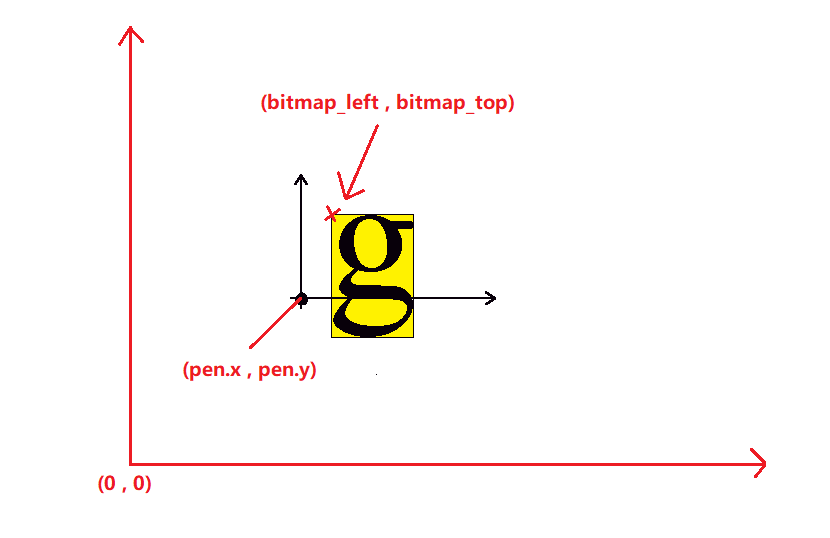
第41行,移动原点,将原点的位置移动到下一个字符的原点
11.3.3.3. 总结¶
使用freetype生成矢量文字字符串的步骤
获取你想要生成的矢量文字的编码(可以是GBK,unicode等)
初始化freetype
用freetype打开支持你生成的文字的编码的字形文件
设置文字大小
计算容纳你字符串的外框
设置旋转角(可以忽略),原点位置
加载位图(可由三个函数联合替换)
根据位图的buffer,使用描点函数描点
11.3.4. freetype进阶¶
freetype的官网内有十分详细的文档来讲解,我在前面的讲解在官方文档面前,只能说是关公面前耍大刀
freetype官方文档中还包含下面的教程,以及丰富的例子。
字距微调
居中
渲染变换的字形序列
等等