
3. 管道¶
管道是Linux中最古老、最基础的进程间通信(IPC)方式,遵循“一切皆文件”的设计思想, 依托内存缓冲区实现数据传输,分为匿名管道(PIPE)和命名管道(FIFO)两类。 匿名管道适配亲缘进程通信,命名管道支持无亲缘关系进程通信,二者均以字节流形式传输数据,具备轻量、易用的特点, 是Linux系统进程协作、命令行管道复用的核心机制。
3.1. 管道的基本概念¶
管道的本质是 内核管理的内存缓冲区 ,对外表现为文件形式,可通过标准文件IO接口操作, 数据遵循先进先出(FIFO)原则,无数据覆盖问题。其核心底层特性如下:
半双工通信:数据只能单向传输,同一时间仅支持一端写、一端读,如需双向通信需创建两个管道;
字节流传输:数据无固定格式边界,读写双方需自行约定数据格式,避免粘包问题;
内存暂存:数据仅存于内存,不占用磁盘空间,进程退出后管道自动销毁;
阻塞特性:默认阻塞模式,读写空管道/满管道时进程会阻塞,可配置为非阻塞模式;
不可定位:不支持lseek()文件定位操作,数据只能顺序读写。
3.1.1. Shell命令管道¶
Shell中的“|”是匿名管道的典型应用,可将前一个命令的标准输出,作为后一个命令的标准输入,无需手动创建管道,系统自动完成进程间数据流转。
在终端中使用以下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 命令
ps -aux | grep root
# 信息输出如下
root 1 0.0 0.0 225376 6376 ? Ss 10月18 0:31 /sbin/init
root 2 0.0 0.0 0 0 ? S 10月18 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< 10月18 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? I< 10月18 0:00 [mm_percpu_wq]
root 7 0.0 0.0 0 0 ? S 10月18 0:02 [ksoftirqd/0]
root 8 0.0 0.0 0 0 ? I 10月18 5:35 [rcu_sched]
root 9 0.0 0.0 0 0 ? I 10月18 0:00 [rcu_bh]
root 10 0.0 0.0 0 0 ? S 10月18 0:00 [migration/0]
root 11 0.0 0.0 0 0 ? S 10月18 0:01 [watchdog/0]
root 12 0.0 0.0 0 0 ? S 10月18 0:00 [cpuhp/0]
root 13 0.0 0.0 0 0 ? S 10月18 0:00 [cpuhp/1]
|
对于shell命令来说,命令的连接是通过管道字符来完成的,正如“ ps -aux | grep root ”命令一样,
只需要使用“|”字符进行连接即可。
那么我们对这个”ps -aux | grep root”命令进行详细的分析,它实际上就是执行以下过程:
shell负责安排两个命令的标准输入和标准输出。
ps的标准输入来自终端鼠标、键盘等。
ps的标准输出传递给grep,作为grep的标准输入。
grep的标准输出连接到终端,即输出到显示器屏幕,最终我们看到grep的输出结果。
shell所做的工作实际上是对标准输入和标准输出流进行了重新连接,在ps命令与grep之间建立了数据管道,示意图如下:
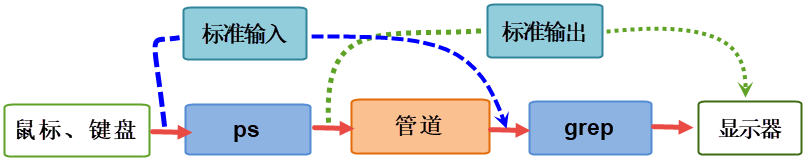
其实,管道本质上也是一个文件,上图的过程可以看作是ps进程将输出的内容写入管道中, grep进程从管道中读取数据,可以把它抽象成一个可读写的文件。 遵循了Linux中“一切皆文件”的设计思想,它借助VFS(虚拟文件系统)给应用程序提供操作接口,实现了管道的功能。
不过还是要注意的是:虽然管道的实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间, 它占用的是内存空间,因此Linux上的管道就是一个操作方式为文件的内存缓冲区而已。
3.2. 管道应用场景¶
Shell命令组合:各类命令行管道复用,实现命令间数据流转;
日志收集系统:多进程将日志写入命名管道,单日志进程统一读取写入文件,避免多进程写文件冲突;
父子进程协作:父进程传递配置/指令给子进程,子进程反馈执行结果;
轻量进程通信:无需复杂IPC机制,快速实现简单进程数据交互。
3.3. 管道的分类¶
Linux系统上的管道分两种类型:
匿名管道
命名管道
这两种管道也叫做无名或有名管道,为了统一,以下我们称为匿名管道和命名管道。
3.3.1. 匿名管道PIPE¶
匿名管道(PIPE)是一种特殊的文件,但虽然它是一种文件,却没有名字, 因此一般进程无法使用open()来获取他的描述符,它只能在一个进程中被创建出来, 然后通过继承的方式将他的文件描述符传递给子进程,这就是为什么匿名管道只能用于亲缘关系进程间通信的原因。
另外,匿名管道不同于一般文件的显著之处是:它有两个文件描述符,一个只能用来读, 另一个只能用来写,这就是所谓的“半双工”通信方式。 而且它对写操作不做任何保护,即:假如有多个进程或线程同时对匿名管道进行写操作,那么这些数据很有可能会相互践踏, 因此一个简单的结论是:匿名管道只能用于一对一的亲缘进程通信。
最后,匿名管道不能使用lseek()来进行定位,因为他们的数据不像普通文件那样按块的方式存放在诸如硬盘、flash等块设备上。
总结来说,匿名管道有以下的特征:
没有名字,因此不能使用open()函数打开,但可以使用close()函数关闭。
只提供单向通信(即半双工通信),也就是说,两个进程都能访问这个文件,假设进程1往文件内写东西, 那么进程2就只能读取文件的内容。
只能用于具有血缘关系的进程间通信,通常用于父子进程建通信 。
管道是基于字节流来通信的。
依赖于文件系统,它的生命周期随着进程的结束而结束。
写入操作不具有原子性,因此只能用于一对一的简单通信情形。
管道也可以看成是一种特殊的文件,对于它的读写也可以使用普通的read()和write()等函数。 但是它又不是普通的文件,并不属于其他任何文件系统,并且只存在于内核的内存空间中, 因此不能使用lseek()来定位。
3.3.2. 命名管道FIFO¶
命名管道(FIFO)与匿名管道(PIPE)是不同的,命名管道可以在多个无关的进程中交换数据(通信)。 我们知道,匿名管道的通信方式通常都由一个共同的祖先进程启动,只能在”有血缘关系”的进程中进行数据交互, 这给我们在不相关的的进程之间交换数据带来了不方便,因此产生了命名管道,来解决不相关进程间的通信问题。
命名管道不同于无名管道之处在于它提供了一个路径名与之关联,以一个文件形式存在于文件系统中, 这样,即使与命名管道的创建进程不存在“血缘关系”的进程,只要可以访问该命名管道文件的路径, 就能够彼此通过命名管道相互通信,因为可以通过文件的形式,那么就可以调用系统中对文件的操作, 如打开(open)、读(read)、写(write)、关闭(close)等函数,虽然命名管道文件存储在文件系统中, 但数据却是存在于内存中的,这点要区分开。
总结来说,命名管道有以下的特征:
有名字,存储于普通文件系统之中。
任何具有相应权限的进程都可以使用 open()来获取命名管道的文件描述符。
跟普通文件一样:使用统一的 read()/write()来读写。
跟普通文件不同:不能使用 lseek()来定位,原因是数据存储于内存中。
具有写入原子性,支持多写者同时进行写操作而数据不会互相践踏。
遵循先进先出(First In First Out)原则,最先被写入 FIFO的数据,最先被读出来。
3.4. 管道创建¶
3.4.1. 创建匿名管道¶
3.4.1.1. pipe函数¶
pipe()函数用于创建一个匿名管道,一个可用于进程间通信的单向数据通道。
函数原型:
1 2 3 | #include <unistd.h>
int pipe(int pipefd[2]);
|
函数原型非常简单,没有任何的传入参数,注意:数组pipefd是用于返回两个引用管道末端的文件描述符, 它是一个由两个文件描述符组成的数组的指针。 pipefd[0] 指管道的读取端, pipefd[1] 指向管道的写端, 向管道的写入端写入数据将会由内核缓冲,即写入内存中,直到从管道的读取端读取数据为止,而且数据遵循先进先出原则。
pipe()函数还会返回一个int类型的变量,如果为0则表示创建匿名管道成功,如果为-1则表示创建失败,并且设置errno。
匿名管道创建成功以后,创建该匿名管道的进程(父进程)同时掌握着管道的读取端和写入端, 但是想要父子进程间有数据交互,则需要以下操作:
父进程调用pipe()函数创建匿名管道,得到两个文件描述符pipefd[0]、pipefd[1], 分别指向管道的读取端和写入端。
父进程调用fork()函数启动(创建)一个子进程, 那么子进程将从父进程中继承这两个文件描述符pipefd[0]、pipefd[1], 它们指向同一匿名管道的读取端与写入端。
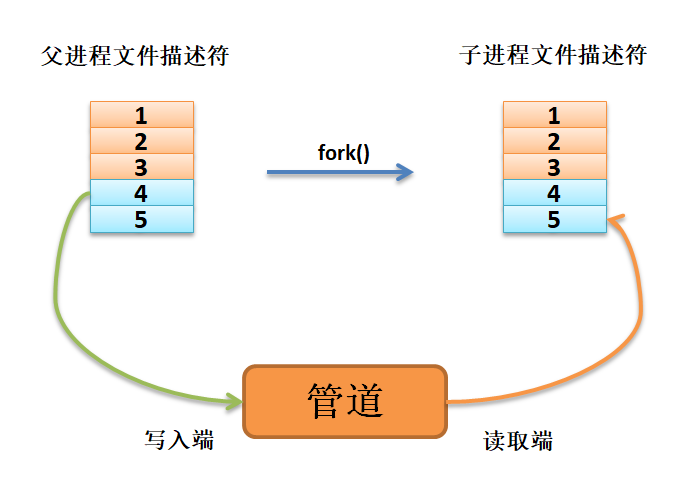
由于匿名管道是利用环形队列实现的,数据将从写入端流入管道,从读取端流出,这样子就实现了进程间通信, 但是这个匿名管道此时有两个读取端与两个写入端, 如图 fork后子进程继承父进程文件描述符 所示,因此需要进行接下来的操作。
fork后子进程继承父进程文件描述符:

如果想要从父进程将数据传递给子进程,则父进程需要关闭读取端,子进程关闭写入端, 如图 数据从父进程流向子进程 所示。
数据从父进程流向子进程:
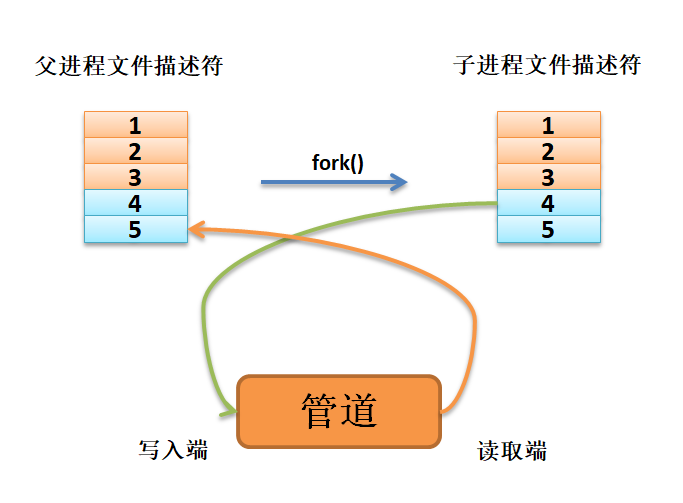
如果想要从子进程将数据传递给父进程,则父进程需要关闭写入端,子进程关闭读取端, 如图 数据从子进程流向父进程 所示。
数据从子进程流向父进程:
当不需要管道的时候,就在进程中将未关闭的一端关闭即可。
3.4.1.2. 实验分析¶
我们可以使用pipe()函数做一个测试实验, 在system_programing/pipe目录下存在pipe.c文件,该文件内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | #include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_DATA_LEN 256
#define DELAY_TIME 1
int main()
{
pid_t pid;
int pipe_fd[2]; //(1)
char buf[MAX_DATA_LEN];
const char data[] = "Pipe Test Program";
int real_read, real_write;
memset((void*)buf, 0, sizeof(buf));
/* 创建管道 */
if (pipe(pipe_fd) < 0) //(2)
{
printf("pipe create error\n");
exit(1);
}
/* 创建一子进程 */
if ((pid = fork()) == 0) //(3)
{
/* 子进程关闭写描述符,并通过使子进程暂停 3s 等待父进程已关闭相应的读描述符 */
close(pipe_fd[1]);
sleep(DELAY_TIME * 3);
/* 子进程读取管道内容 */ //(4)
if ((real_read = read(pipe_fd[0], buf, MAX_DATA_LEN)) > 0)
{
printf("%d bytes read from the pipe is '%s'\n", real_read, buf);
}
/* 关闭子进程读描述符 */
close(pipe_fd[0]); //(5)
exit(0);
}
else if (pid > 0)
{
/* 父进程关闭读描述符,并通过使父进程暂停 1s 等待子进程已关闭相应的写描述符 */
close(pipe_fd[0]); //(6)
sleep(DELAY_TIME);
if((real_write = write(pipe_fd[1], data, strlen(data))) != -1) //(7)
{
printf("Parent write %d bytes : '%s'\n", real_write, data);
}
/*关闭父进程写描述符*/
close(pipe_fd[1]); //(8)
/*收集子进程退出信息*/
waitpid(pid, NULL, 0); //(9)
exit(0);
}
}
|
(1) :定义一个数组pipe_fd,在创建匿名管道后通过数组返回管道的文件描述符。
(2) :调用pipe()创建一个匿名管道,创建成功则得到两个文件描述符pipe_fd[0]、pipe_fd[1],否则返回-1。
(3) :调用fork()创建一个子进程,如果返回值是0则表示此时运行的是子进程, 那么在子进程中调用close()函数关闭写描述符,并使子进程睡眠 3s 等待父进程已关闭相应的读描述符。
(4) :子进程调用read()函数读取管道内容,如果管道没有数据则子进程将被阻塞,读取到数据就将数据打印出来。 特别地如果调用read()函数读取一个关闭了写描述符的管道,那么read()会返回0,(本例子中父进程的写描述符没有关闭)。
(5) :调用close()函数关闭子进程读描述符。
(6) :如果fork()函数的返回值大于0,则表示此时运行的是父进程,那么在父进程中先调用close()关闭管道的读描述符, 并且等待1s,因为此时可能子进程先于父进程运行,暂且等待一会。
(7) :父进程调用write()函数将数据写入管道。
(8) :关闭父进程写描述符。
(9) :调用waitpid()函数收集子进程退出信息并退出进程。
pipe示例的编译及测试过程如下:
1 2 3 4 5 6 7 8 9 | # 以下操作在 system_programing/pipe 代码目录进行
make
# 运行
./build/pipe_demo
#信息输出如下,子进程从管道中读取到父进程写入的内容
Parent write 17 bytes : 'Pipe Test Program'
17 bytes read from the pipe is 'Pipe Test Program'
|
3.4.2. 创建命名管道¶
3.4.2.1. 命令行方式创建¶
至此,我们还只能在有“血缘关系”的程序之间传递数据,即这些程序是由一个共同的祖先进程启动的。 但如果想在不相关的进程之间交换数据,我们可以用FIFO文件来完成这项工作,或者称之为命名管道。
命名管道是一种特殊类型的文件,它在文件系统中以文件名的形式存在,但它的的数据却是存储在内存中的。 我们可以在终端(命令行)上创建命名管道,也可以在程序中创建它。
比如使用mkfifo命令去创建一个命名管道,关于mkfifo命令,我们可以使用man命令查看一下它的描述:
1 2 3 4 5 | # 创建名为myfifo的命名管道
mkfifo myfifo
# 查看文件类型,显示fifo(命名管道)
file myfifo
|
3.4.2.2. 函数方式创建¶
这个mkfifo命令实际上就是Linux系统的同名API mkfifo,在源代码里我们可以通过调用mkfifo函数创建一个命名管道, 其实就类似于创建一个文件,只不过这个文件的类型是命名管道的类型。
mkfifo()的函数原型如下:
1 2 3 4 | #include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
|
mkfifo()会根据参数pathname建立特殊的FIFO文件,而参数mode为该文件的模式与权限。
mkfifo()创建的FIFO文件其他进程都可以进行读写操作,可以使用读写一般文件的方式操作它, 如open,read,write,close等。
mode模式及权限参数说明:
O_RDONLY:读管道。
O_WRONLY:写管道。
O_RDWR:读写管道。
O_NONBLOCK:非阻塞。
O_CREAT:如果该文件不存在,那么就创建一个新的文件,并用第三个参数为其设置权限。
O_EXCL:如果使用 O_CREAT 时文件存在,那么可返回错误消息。这一参数可测试文件是否存在。
函数返回值说明如下:
0:成功
EACCESS:参数 filename 所指定的目录路径无可执行的权限。
EEXIST:参数 filename 所指定的文件已存在。
ENAMETOOLONG:参数 filename 的路径名称太长。
ENOENT:参数 filename 包含的目录不存在。
ENOSPC:文件系统的剩余空间不足。
ENOTDIR:参数 filename 路径中的目录存在但却非真正的目录。
EROFS:参数 filename 指定的文件存在于只读文件系统内。
使用FIFO的过程中,当一个进程对管道进行读操作时:
若该管道是阻塞类型,且当前FIFO内没有数据,则对读进程而言将一直阻塞到有数据写入。
若该管道是非阻塞类型,则不论FIFO内是否有数据,读进程都会立即执行读操作。 即如果FIFO内没有数据,读函数将立刻返回 0。
使用FIFO的过程中,当一个进程对管道进行写操作时:
若该管道是阻塞类型,则写操作将一直阻塞到数据可以被写入。
若该管道是非阻塞类型而不能写入全部数据,则写操作进行部分写入或者调用失败
3.4.2.3. 实验分析¶
下面我们来看看具体的实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 | #include <sys/wait.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <string.h>
#define MYFIFO "myfifo" /* 命名管道文件名*/
#define MAX_BUFFER_SIZE PIPE_BUF /* 4096 定义在于 limits.h 中*/
void fifo_read(void)
{
char buff[MAX_BUFFER_SIZE];
int fd;
int nread;
printf("***************** read fifo ************************\n");
/* 判断命名管道是否已存在,若尚未创建,则以相应的权限创建*/
if (access(MYFIFO, F_OK) == -1) //(4)
{
if ((mkfifo(MYFIFO, 0666) < 0) && (errno != EEXIST)) //(5)
{
printf("Cannot create fifo file\n");
exit(1);
}
}
/* 以只读阻塞方式打开命名管道 */
fd = open(MYFIFO, O_RDONLY); //(6)
if (fd == -1)
{
printf("Open fifo file error\n");
exit(1);
}
memset(buff, 0, sizeof(buff));
if ((nread = read(fd, buff, MAX_BUFFER_SIZE)) > 0) // (7)
{
printf("Read '%s' from FIFO\n", buff);
}
printf("***************** close fifo ************************\n");
close(fd); //(8)
exit(0);
}
void fifo_write(void)
{
int fd;
char buff[] = "this is a fifo test demo";
int nwrite;
sleep(2); //等待子进程先运行 //(9)
/* 以只写阻塞方式打开 FIFO 管道 */
fd = open(MYFIFO, O_WRONLY | O_CREAT, 0644); //(10)
if (fd == -1)
{
printf("Open fifo file error\n");
exit(1);
}
printf("Write '%s' to FIFO\n", buff);
/*向管道中写入字符串*/
nwrite = write(fd, buff, MAX_BUFFER_SIZE); //(11)
if(wait(NULL)) //等待子进程退出
{
close(fd); //(12)
exit(0);
}
}
int main()
{
pid_t result;
/*调用 fork()函数*/
result = fork(); //(1)
/*通过 result 的值来判断 fork()函数的返回情况,首先进行出错处理*/
if(result == -1)
{
printf("Fork error\n");
}
else if (result == 0) /*返回值为 0 代表子进程*/
{
fifo_read(); //(2)
}
else /*返回值大于 0 代表父进程*/
{
fifo_write(); //(3)
}
return result;
}
|
下面介绍这个例程的流程,我们先从main函数开始:
(1): 首先使用fork函数创建一个子进程。
(2): 返回值为 0 代表子进程,就运行fifo_read()函数。
(3): 返回值大于 0 代表父进程,就运行fifo_write()函数。
(4): 在子进程中先通过access()函数判断命名管道是否已存在,若尚未创建,则以相应的权限创建
(5): 调用mkfifo()函数创建一个命名管道。
(6): 使用open()函数以只读阻塞方式打开命名管道。
(7): 使用read()函数读取管道的内容,由于打开的管道是阻塞的,而此时管道中没有存在任何数据, 因此子进程会阻塞在这里,等待到管道中有数据时才恢复运行,并打印从管道中读取到的数据。
(8): 读取完毕,使用close()函数关闭管道。
(9): 父进程休眠2秒,等待子进程先运行,因为本例子是在子进程中创建管道的。
(10): 以只写阻塞方式打开 FIFO 管道。
(11): 向管道中写入字符串数据,当写入后管道中就存在数据了,此时处于阻塞的子进程将恢复运行, 并将字符串数据打印出来。
(12): 等待子进程退出,并且关闭管道。
fifo例程的编译及测试过程如下:
1 2 3 4 5 6 7 8 9 10 11 | # 以下操作在 system_programing/fifo 代码目录进行
make
# 运行
./build/fifo_demo
# 信息输出如下
***************** read fifo ************************
Write 'this is a fifo test demo' to FIFO
Read 'this is a fifo test demo' from FIFO
***************** close fifo ************************
|