
2. 手写数字识别–飞桨(PaddlePaddle)¶
2.1. 飞桨(PaddlePaddle)简介¶

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础, 集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。
飞桨(PaddlePaddle)已凝聚477万开发者,基于飞桨创建56万个模型,服务18万家企事业单位。 飞桨助力开发者快速实现AI想法,创新AI应用,作为基础平台支撑越来越多行业实现产业智能化升级。 截至2022年12月,通信通院最新报告显示,飞桨已经成为中国深度学习市场应用规模第一的深度学习框架和赋能平台, 已汇聚535万开发者,服务20万家企事业单位,基于飞桨构建了67万个模型。
我们将基于飞桨(PaddlePaddle),完成一个简单的手写数字识别任务,并部署到鲁班猫板卡。通过本章节简单了解下飞桨(PaddlePaddle)以及深度学习模型。
提示
测试环境:鲁班猫板卡使用Debian10,PC是ubuntu20.04。PaddlePaddle是CPU版,rknn-Toolkit2版本1.4.0。
2.2. 安装飞桨(PaddlePaddle)¶
# PC端使用pip3工具安装飞桨CPU版
pip3 install paddlepaddle -i https://mirror.baidu.com/pypi/simple
# 验证安装,进入python解释器,输入:
python
import paddle
paddle.utils.run_check()
# 验证安装,打印版本信息
print(paddle.__version__)
# 最后显示PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
# 说明安装成功
详细安装paddlepaddle参考 安装教程 。
2.3. 手写数字识别任务¶
手写数字识别任务是机器学习领域使用最广泛的示例之一,相对简单的模型,非常适用初学者。 任务的整体流程,参考图片(图片来自Paddle 教程):
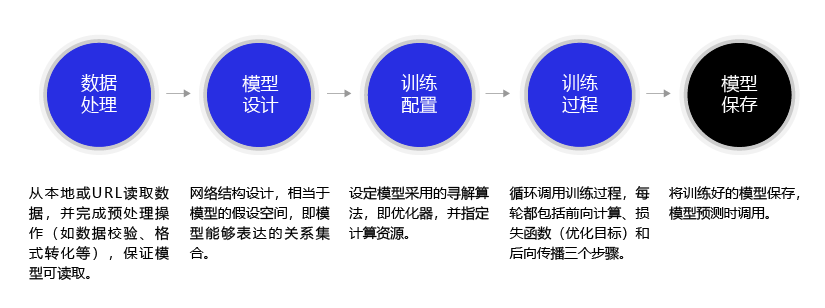
2.3.1. 准备训练集和测试集¶
手写数字识别用灰度图表示不同人书写的数字,每张图片尺寸28*28,我们使用MNIST 数据集,可以到 官网 下载,或者我们直接使用Paddle加载MNIST。
这里我们加载了MNIST训练集(mode=’train’)和测试集(mode=’test’),训练集用于训练模型,测试集用于评估模型效果。
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
2.3.2. 模型组网¶
在数字识别过程中,直接使用了飞桨内置的模型LeNet,使用高层API,一行代码即完成LeNet的网络构建和初始化,也可以自定义组网, 参考 这里
# 模型组网并初始化网络,
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
#paddle.summary(lenet,(1, 1, 28, 28))
LeNet模型包含 2个Conv2D卷积层、2个ReLU激活层、2个MaxPool2D池化层以及3个Linear全连接层,取消上面 paddle.summary(lenet,(1, 1, 28, 28)) 一行的注释,
打印网络的结构和参数统计:
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 1, 28, 28]] [1, 6, 28, 28] 60
ReLU-1 [[1, 6, 28, 28]] [1, 6, 28, 28] 0
MaxPool2D-1 [[1, 6, 28, 28]] [1, 6, 14, 14] 0
Conv2D-2 [[1, 6, 14, 14]] [1, 16, 10, 10] 2,416
ReLU-2 [[1, 16, 10, 10]] [1, 16, 10, 10] 0
MaxPool2D-2 [[1, 16, 10, 10]] [1, 16, 5, 5] 0
Linear-1 [[1, 400]] [1, 120] 48,120
Linear-2 [[1, 120]] [1, 84] 10,164
Linear-3 [[1, 84]] [1, 10] 850
===========================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
---------------------------------------------------------------------------
2.3.3. 模型训练与评估¶
模型训练包括多轮迭代(epoch), 每轮迭代遍历一次训练数据集,并且每次从中获取一小批(mini-batch)样本,送入模型执行前向计算得到预测值,并计算预测值(predict_label)与真实值(true_label)之间的损失函数值(loss)。 执行梯度反向传播,并根据设置的优化算法(optimizer)更新模型的参数。 观察每轮迭代的loss值减小趋势,可判断模型训练效果。
# 设置优化器及其学习率,并将网络的参数传入优化器,设置损失函数和精度计算方式
# optimizer 优化器,寻找最优解的方法;Loss 损失函数;metric 评价指标
# 这里配置使用Adam优化器,使用交叉熵损失函数CrossEntropyLoss用于分类任务评估,
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练,epoch 训练轮次,batch_size 批次大小,verbose=1 打印训练过程中的日志
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估,将测试数据集送入训练好的模型进行评估,得到预测值,计算预测值与真实值之间的损失函数值(loss),
# 并计算评价指标值(metric),用于评估模型效果
model.evaluate(test_dataset, batch_size=64, verbose=1)
2.3.4. 模型保存和导出ONNX模型¶
训练好的模型,可以保存到文件中,后续需要训练调优或推理部署时,再加载(load)到内存中运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # 保存模型
model.save('./output/mnist')
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
|
Paddle模型训练之后,转换成ONNX协议只需要调用paddle.onnx.export接口,便会在指定的路径下生成ONNX模型, 也可以Paddle模型保存为部署模型(静态图模型),然后使用Paddle2ONNX命令行进行转换。 转换原理参考 这里 。
# 需要保存的路径,当前onnx目录下
save_path = 'onnx/lenet'
# 为模型指定输入的形状和数据类型
x_spec = paddle.static.InputSpec([1, 1, 28, 28], 'float32', 'x')
# 生成ONNX模型
paddle.onnx.export(lenet, save_path, input_spec=[x_spec], opset_version=11)
2.3.5. 完整程序¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | import paddle
import numpy as np
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
# 加载模型
# model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 需要保存的路径
save_path = 'onnx/lenet'
# 为模型指定输入的形状和数据类型
x_spec = paddle.static.InputSpec([1, 1, 28, 28], 'float32', 'x')
# 生成ONNX模型
paddle.onnx.export(lenet, save_path, input_spec=[x_spec], opset_version=11)
|
测试显示:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 938/938 [==============================] - loss: 0.0117 - acc: 0.9368 - 19ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.0072 - acc: 0.9778 - 18ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0521 - acc: 0.9814 - 19ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 0.0047 - acc: 0.9848 - 19ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.0208 - acc: 0.9857 - 19ms/step
Eval begin...
step 157/157 [==============================] - loss: 0.0011 - acc: 0.9843 - 8ms/step
Eval begin...
step 157/157 [==============================] - loss: 2.8939e-04 - acc: 0.9825 - 8ms/step
Eval samples: 10000
true label: 7, pred label: 7
I0209 16:10:02.397411 8350 interpretercore.cc:279] New Executor is Running.
2023-02-09 16:10:02 [INFO] Static PaddlePaddle model saved in onnx/paddle_model_static_onnx_temp_dir.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: onnx/paddle_model_static_onnx_temp_dir/model.pdmodel
[Paddle2ONNX] Paramters file path: onnx/paddle_model_static_onnx_temp_dir/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2023-02-09 16:10:02 [INFO] ONNX model saved in onnx/lenet.onnx.
2.3.6. 模拟推理和导出RKNN模型¶
使用RKNN-Toolkit2工具进行模型的转换和模拟推理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | INPUT_SIZE = 28
IMG_PATH = 'test.jpg'
# 创建RKNN执行对象,打印信息
#rknn = RKNN(verbose=True)
rknn = RKNN()
# 配置模型输入,用于NPU对数据输入的预处理
# mean_values:输入的均值
# std_values:输入的归一化值
# target_platform: 目标平台
# 更多设置参考RKNN toolkit2用户指导手册
print('--> Config model')
rknn.config(mean_values=[127.5], std_values=[127.5], target_platform='rk3568')
# 加载ONNX模型
print('--> Loading model')
rknn.load_onnx(model='./lenet.onnx')
print('done')
print('--> Building model')
ret = rknn.build(do_quantization=False)
print('done')
# 初始化RKNN运行环境,运行测试
print('--> Init runtime environment')
ret = rknn.init_runtime()
print('done')
# 输入图像处理
img = cv2.imread(IMG_PATH)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = cv2.resize(img,(28,28))
img = np.expand_dims(img, 0)
img = np.expand_dims(img, 0)
# 模拟推理
print('--> Running model')
outputs = rknn.inference(inputs=[img], data_format='nchw')
print("result: ", outputs)
print("本次预测数字是:", np.argmax(outputs))
# 导出rknn模型文件
print('--> Export rknn model')
rknn.export_rknn('./lenet.rknn')
print('done')
# 释放rknn
rknn.release()
|
简单转换和推理测试结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | W __init__: rknn-toolkit2 version: 1.4.0-22dcfef4
--> Config model
--> Loading model
done
--> Building model
done
--> Init runtime environment
W init_runtime: Target is None, use simulator!
done
--> Running model
Analysing : 100%|█████████████████████████████████████████████████| 11/11 [00:00<00:00, 1931.24it/s]
Preparing : 100%|██████████████████████████████████████████████████| 11/11 [00:00<00:00, 360.11it/s]
result: [array([[-3.5175781, -4.140625 , -1.8232422, 0.5727539, 2.7480469,
-1.9824219, -7.9726562, -0.5292969, 3.46875 , 7.5039062]],
dtype=float32)]
本次预测数字是: 9
--> Export rknn model
done
|
2.4. 板端部署推理¶
2.4.1. 安装RKNN Toolkit Lite2和相关库¶
Toolkit Lite2的安装参考前面 《NPU使用章节》
# 板端安装相关的库
sudo apt update
sudo apt -y install python3-pil python3-numpy python3-pip git wget
sudo apt install python3-opencv
2.4.2. 推理测试¶
使用前面转换出的rknn模型,然后编写测试程序(也可以直接从配套例程获取文件):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | IMG_PATH = '9.jpg'
RKNN_MODEL = 'lenet.rknn'
# 创建RKNN
rknn_lite = RKNNLite()
# 导入模型
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(RKNN_MODEL)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn_lite.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# load image
img = cv2.imread(IMG_PATH)
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = cv2.resize(img,(28,28))
# runing model
print('--> Running model')
outputs = rknn_lite.inference(inputs=[img])
print("result: ", outputs)
print("本次预测的数字是:", np.argmax(outputs))
rknn_lite.release()
|
运行程序:
--> Load RKNN model
done
--> Init runtime environment
I RKNN: [11:37:03.185] RKNN Runtime Information: librknnrt version: 1.4.0 (a10f100eb@2022-09-09T09:07:14)
I RKNN: [11:37:03.185] RKNN Driver Information: version: 0.7.2
I RKNN: [11:37:03.185] RKNN Model Information: version: 1, toolkit version: 1.4.0-22dcfef4(compiler version: 1.4.0 (3b4520e4f@2022-09-05T20:52:35)), target: RKNPU lite, target platform: rk3568, framework name: ONNX, framework layout: NCHW
done
--> Running model
result: [array([[-3.5429688 , -4.1445312 , -1.7900391 , 0.57128906, 2.7421875 ,
-2.015625 , -7.9882812 , -0.52734375, 3.4882812 , 7.5234375 ]],
dtype=float32)]
本次预测的数字是: 9
2.5. 总结¶
以上是一个简单的示例,是用LeNet对手写数字数据及MNIST进行分类,调用封装好的训练与测试接口快速完成模型的组建与预测,用于简单学习参考。如果想一步一步自己构建模型训练, 可以参考 PaddlePaddle零基础实践深度学习 。