
1. TPU¶
LubanCat-P1板卡基于SG2000芯片的一款高性能、低功耗嵌入式板卡,拥有更大的内存(512MB)和更多的IO接口,支持在 RISC-V 和 ARM 启动之间切换, 更多详情请参考下快速 LubanCat-P1板卡使用手册 。
SG2000芯片内部集成了TPU,它在INT8运算下可提供约0.5TOPS的计算能力,有设计专门的TPU调度引擎高效地为张量处理单元核心提供高带宽数据流, 配套有强大的深度学习模型编译器和软件SDK开发套件,支持Caffe、Pytorch、ONNX、MXNet、TensorFlow(Lite)等主流深度学习框架。
1.1. TPU开发¶
TPU软件框架如下图所示(仅仅用于了解下大致框架):
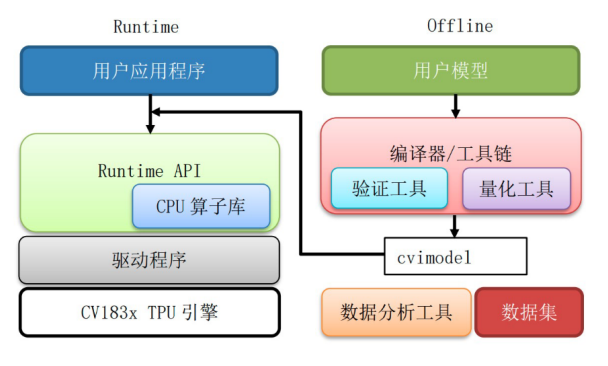
用户模型经过模型导入,模型变换,量化,优化等步骤,最终组装为cvimodel格式的模型文件。
Runtime模型推理库加载cvimodel,读取运行时信息进行设置和资源分配,加载权重数据和指令序列, 驱动硬件执行其中的指令序列,完成神经网络推理计算任务,输出推理结果数据。
Runtime提供一组API供应用程序运行时调用,实现模型在板端的在线推理。 也支持API调用仿真器,用户可以在仿真平台完成模型移植,验证和精度测试,再加载到真实硬件上验证和执行。
其中,cvimodel模型文件支持多batch、多分辨率和模型分段等特性,生成cvimodel模型文件时设置不同平台将运行在不同平台上, 例如设置cv181x平台⽣成的cvimodel可以运⾏在1810C/1811C/1812C/1810H/1811H/1812H等cv181x系列芯⽚上等等。
LubanCat-P1板卡上运行的cvimodel,转换成cvimodel模型文件时需要设置平台参数cv181x。
另外,关于算⼦的⽀持请参考 TPU SDK 开发资料汇总 中的文档:《CVITEK TPU SDK开发指南》。
1.1.1. TPU-MLIR¶
TPU-MLIR 是算能深度学习处理器的 神经⽹络编译器。 该工程提供了一套完整的工具链, 其可以将不同框架下预训练的神经网络, 转化为可以在算能智能视觉深度学习处理器上高效运算的模型文件bmodel/cvimodel。
TPU-MLIR代码开源地址: https://github.com/sophgo/tpu-mlir。
TPU-MLIR的整体框架如下:
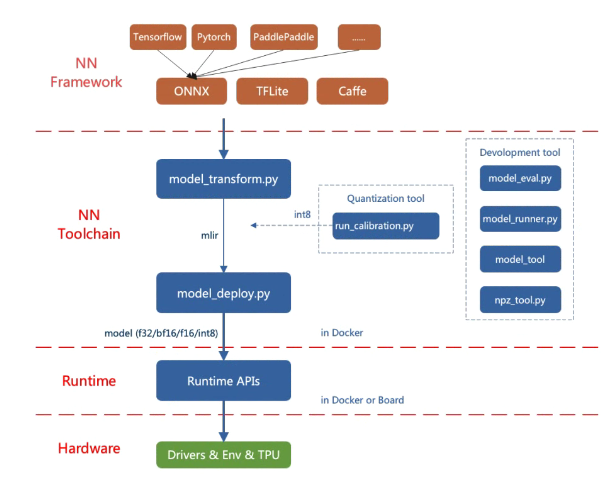
TPU-MLIR直接支持的框架有PyTorch、ONNX、TFLite和Caffe,其他框架的模型需要转换成ONNX模型。
TPU-MLIR模型转换大致步骤:
通过model_transform将原始模型转换成mlir文件
通过model_deploy将mlir文件转换成bmodel/cvimodel
其中,如果要转INT8模型, 则需要调用run_calibration生成校准表, 然后传给model_deploy就行模型转换 如果INT8模型不满足精度需要, 可以调用run_qtable生成量化表, 用来决定哪些层采用浮点计算,然后传给model_deploy生成混精度模型。
1.1.2. TDL SDK¶
TDL(Turnkey Deep Learning)SDK 是一款集成算法开发包,提供了便捷的编程接口, 使开发者们能够更快、高效地将各种智能技术应用于自己的产品和服务中。
TDL SDK的系统架构图如下:
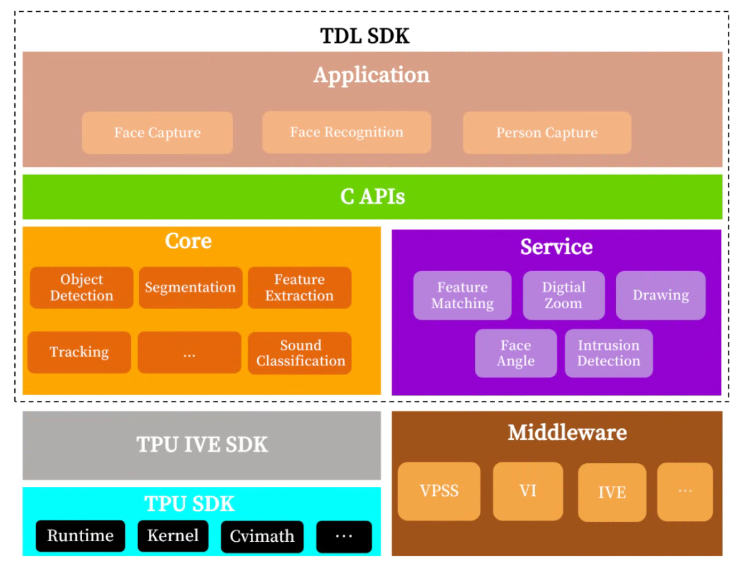
TDL SDK主要有两大核心模块(Core和Service),以及应用(Application)和C接口(C APIs)。
Core提供了算法相关接口,封装复杂的底层操作及算法细节,在内部会对模型进行相应的前后处理,并完成推理。
Service提供算法相关辅助API,例如:绘图, 特征比对, 区域入侵判定等功能。
C APIs实现对现有现有算法模块的功能封装,除了支持TDL SDK内部模型外,还支持开发者自有模型(需按TDL SDK文档进行模型转换)。
Application封装应用逻辑,包含人脸抓拍的应用逻辑等等。