
2. Linux内核模块¶
从本章开始,我们就要真真正正地步入Linux设备驱动的殿堂了。 在Linux系统中,设备驱动会以内核模块的形式出现,学习Linux内核模块编程是驱动开发的先决条件。 第一次接触Linux内核模块,我们将围绕着“Linux内核模块是什么”,“Linux内核模块的工作原理”以及 “我们该怎么使用Linux内核模块”这样的思路一起走进Linux内核世界。
Linux内核模块的介绍大致分为四个部分:
内核模块的概念:内核模块是什么东西?为什么引入内核模块这一机制?
内核模块的原理:内核模块在内核中的加载、卸载过程,深入剖析内核模块如何导出符号。
helloworld实验: 理解内核模块的代码框架和原理,写一个属于自己的模块,以及模块的使用方法等。
内核模块传参与符号共享实验: 理解内核模块的参数模式、符号共享,验证内核模块的运行机制。
这章我们先为大家介绍前两部分,后两部分主要在后面一章的内核模块实验中, 所以会有一节环境准备及介绍的小节作为前导,这章内容关联性很强,建议仔细按顺序阅读。
2.1. 内核模块的概念¶
2.1.1. 内核¶
内核,是一个操作系统的核心。是基于硬件的第一层软件扩充,提供操作系统的最基本的功能, 是操作系统工作的基础,决定着整个操作系统的性能和稳定性。
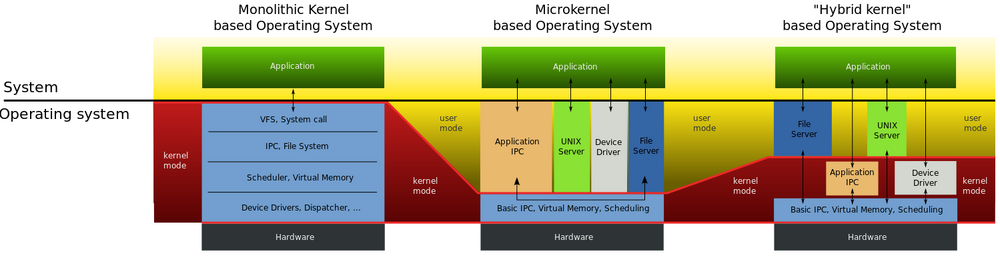
内核按照体系结构分为: 微内核(Micro Kernel) 、 宏内核(Monolithic Kernel) 混合内核(Hybrid Kernel) 等。 在微内核架构中,内核只提供操作系统核心功能,如实现进程管理、存储器管理、进程间通信、I/O设备管理等, 而其它的应用层IPC、文件系统功能、设备驱动模块 则不被包含到内核功能中,属于微内核之外的模块,所以针对这些模块的修改不会影响到微内核的核心功能。 微内核具有动态扩展性强的优点。Windows操作系统、华为的鸿蒙操作系统就属于这类微内核架构。
而宏内核架构是将上述包括微内核以及微内核之外的应用层IPC、文件系统功能、设备驱动模块都编译成一个整体。 其优点是执行效率非常高,但缺点也是十分明显的,一旦我们想要修改、增加内核某个功能时(如增加设备驱动程序)都需要重新编译一遍内核。 Linux操作系统正是采用了宏内核结构,为了解决这一缺点,linux中引入了内核模块这一机制。 具体的差异可以看下下面图片:
2.1.2. 内核模块机制引入¶
2.1.2.1. 内核模块引入原因¶
Linux是一个跨平台的操作系统,支持众多的设备,在Linux内核源码中有超过50%的代码都与设备驱动相关。 Linux为宏内核架构,如果开启所有的功能,内核就会变得十分臃肿。 内核模块就是实现了某个功能的一段内核代码,在内核运行过程,可以加载这部分代码到内核中, 从而动态地增加了内核的功能。基于这种特性,我们进行设备驱动开发时,以内核模块的形式编写设备驱动, 只需要编译相关的驱动代码即可,无需对整个内核进行编译。
2.1.2.2. 内核模块引入好处¶
内核模块的引入不仅提高了系统的灵活性,对于开发人员来说更是提供了极大的方便。 在设备驱动的开发过程中,我们可以随意将正在测试的驱动程序添加到内核中或者从内核中移除, 每次修改内核模块的代码不需要重新启动内核。 在开发板上,我们也不需要将内核模块程序,或者说设备驱动程序的ELF文件存放在开发板中, 免去占用不必要的存储空间。当需要加载内核模块的时候,可以通过挂载NFS服务器, 将存放在其他设备中的内核模块,加载到开发板上。 在某些特定的场合,我们可以按照需要加载/卸载系统的内核模块,从而更好的为当前环境提供服务。
2.1.3. 内核模块的定义和特点¶
了解了内核模块引入以及带来的诸多好处,我们可以在头脑中建立起对内核模块的初步认识, 下面让我们给出内核模块的具体的定义:内核模块全称Loadable Kernel Module(LKM), 是一种在内核运行时加载一组目标代码来实现某个特定功能的机制。
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不一样的。 模块由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序和其他内核上层功能。 因此内核模块具备如下特点:
模块本身不被编译入内核映像,这控制了内核的大小。
模块一旦被加载,它就和内核中的其它部分完全一样。
有了内核模块的概念,下面我们一起深入了解内核模块的工作机制。
2.2. 内核模块的工作机制¶
我们编写的内核模块,经过编译,最终形成.ko为后缀的ELF文件,我们可以使用file命令来查看它。
1 2 3 4 5 | #查看上一次章节编译生成的驱动模块
file helloworld.ko
#信息输出如下
helloworld.ko: ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV), BuildID[sha1]=bc8bd8252d55812798342354a5953d03af2321e5, with debug_info, not stripped
|
这样的文件是如何被内核一步一步拿到并且很好的工作的呢? 为了便于我们更好的理解内核模块的加载/卸载过程,可以先跟我一起学习ELF文件格式,了解ko究竟是怎么一回事。 再一同去看看内核源码,探究内核模块加载/卸载,以及符号导出的经过。
2.2.1. 内核模块详细加载/卸载过程¶
2.2.1.1. ko文件的文件格式¶
ko文件在数据组织形式上是ELF(Excutable And Linking Format)格式,是一种普通的可重定位目标文件。 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。
ELF 文件格式的可能布局如下图。
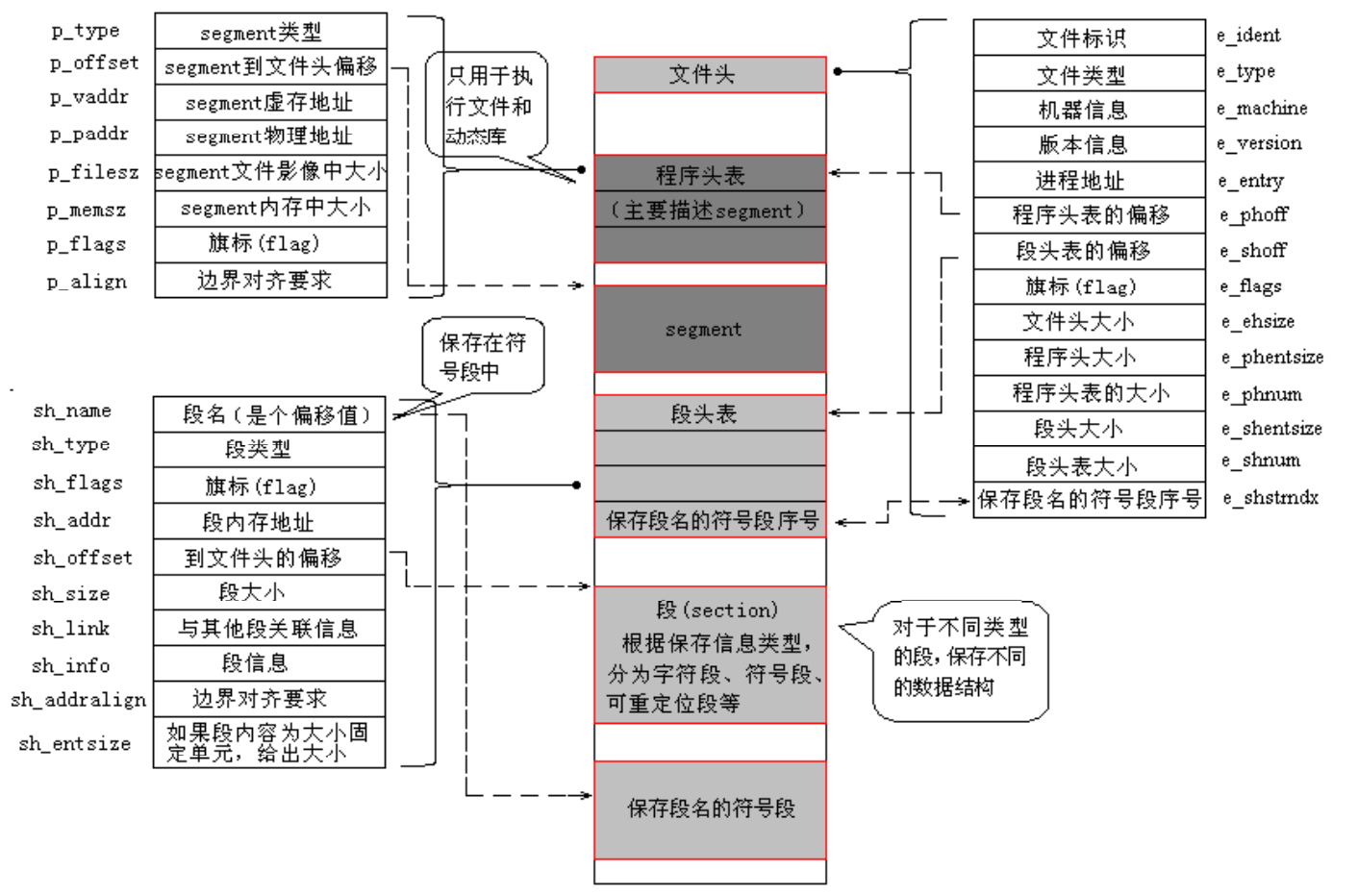
文件开始处是一个ELF头部(ELF Header),用来描述整个文件的组织,这些信息独立于处理器, 也独立于文件中的其余内容
我们可以使用readelf工具查看elf文件的头部详细信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #查看elf文件的头部详细信息
readelf -h helloworld.ko
#信息输出如下
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: AArch64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 160704 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 36
Section header string table index: 35
|
头部详细信息,又叫程序头部表(Program Header Table),它是个数组结构,它的每一个元素的数据结构如下每个数组元素表示:
一个“段”:包含一个或者多个“节区”,程序头部仅对于可执行文件和共享目标文件有意义。
其他信息:系统准备程序执行所必需的其它信息”。
节区头部表/段表(Section Heade Table) ELF文件中有很多各种各样的段,这个段表(Section Header Table)就是保存这些段的基本属性的结构, ELF文件的段结构就是由段表决定的,编译器、链接器、装载器都是依靠段表来定位和访问各个段的属性的,包含了描述文件节区的信息。
ELF头部中:
e_shoff:给出从文件头到节区头部表格的偏移字节数。
e_shnum:给出表格中条目数目。
e_shentsize: 给出每个项目的字节数。
从这些信息中可以确切地定位节区的具体位置、长度和程序头部表一样, 每一项节区在节区头部表格中都存在着一项元素与它对应,因此可知,这个节区头部表格为一连续的空间, 每一项元素为一结构体(思考这节开头的那张节区和节区头部的示意图)。
我们可以加上-S参数读取elf文件的节区头部表的详细信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | #-S参数读取elf文件的节区头部表的详细信息
readelf -S helloworld.ko
#信息输出如下
There are 36 section headers, starting at offset 0x273c0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0 # 空节区,默认占位
[ 1] .note.gnu.build-i NOTE 0000000000000000 00000040
0000000000000024 0000000000000000 A 0 0 4 # 构建ID备注信息
[ 2] .text PROGBITS 0000000000000000 00000064
0000000000000000 0000000000000000 AX 0 0 1 # 可执行代码段(大小0,核心代码在.init.text/.exit.text)
[ 3] .init.text PROGBITS 0000000000000000 00000064
0000000000000028 0000000000000000 AX 0 0 4 # 模块初始化函数的代码段(模块加载时执行)
[ 4] .rela.init.text RELA 0000000000000000 00015650
0000000000000060 0000000000000018 I 33 3 8 # .init.text的重定位表
[ 5] .exit.text PROGBITS 0000000000000000 0000008c
000000000000001c 0000000000000000 AX 0 0 4 # 模块退出函数的代码段(模块卸载时执行)
[ 6] .rela.exit.text RELA 0000000000000000 000156b0
0000000000000048 0000000000000018 I 33 5 8 # .exit.text的重定位表
[ 7] .modinfo PROGBITS 0000000000000000 000000a8
0000000000000098 0000000000000000 A 0 0 1 # 模块信息段(存储模块名、版本、依赖等元信息)
[ 8] .rodata.str1.1 PROGBITS 0000000000000000 00000140
0000000000000032 0000000000000001 AMS 0 0 1 # 只读字符串数据段(如helloworld的字符串)
[ 9] __mcount_loc PROGBITS 0000000000000000 00000178
0000000000000008 0000000000000000 A 0 0 8 # 性能分析函数位置段
[10] .rela__mcount_loc RELA 0000000000000000 000156f8
0000000000000018 0000000000000018 I 33 9 8 # __mcount_loc的重定位表
[11] .note.Linux PROGBITS 0000000000000000 00000180
0000000000000018 0000000000000000 A 0 0 4 # Linux系统备注信息
[12] .data PROGBITS 0000000000000000 00000198
0000000000000000 0000000000000000 WA 0 0 1 # 已初始化的可写数据段
[13] .gnu.linkonce.thi PROGBITS 0000000000000000 000001c0
00000000000003c0 0000000000000000 WA 0 0 64 # 链接时一次性数据段
[14] .rela.gnu.linkonc RELA 0000000000000000 00015710
0000000000000030 0000000000000018 I 33 13 8 # .gnu.linkonce.thi的重定位表
[15] .plt NOBITS 0000000000000000 00000580
0000000000000001 0000000000000000 WA 0 0 1 # 过程链接表(无实际内容)
[16] .init.plt NOBITS 0000000000000000 00000580
0000000000000001 0000000000000000 WA 0 0 1 # 初始化过程链接表(无实际内容)
[17] .text.ftrace_tram NOBITS 0000000000000000 00000580
0000000000000001 0000000000000000 WA 0 0 1 # ftrace跟踪跳板段(无实际内容)
[18] .bss NOBITS 0000000000000000 00000580
0000000000000000 0000000000000000 WA 0 0 1 # 未初始化的可写数据段(NOBITS类型,文件中不占空间,加载后分配内存)
[19] .debug_info PROGBITS 0000000000000000 00000580
000000000000acd8 0000000000000000 0 0 1 # 调试信息段
[20] .rela.debug_info RELA 0000000000000000 00015740
00000000000119d0 0000000000000018 I 33 19 8 # .debug_info的重定位表
[21] .debug_abbrev PROGBITS 0000000000000000 0000b258
00000000000008fe 0000000000000000 0 0 1 # 调试缩写段
[22] .debug_aranges PROGBITS 0000000000000000 0000bb56
0000000000000060 0000000000000000 0 0 1 # 调试地址范围段
[23] .rela.debug_arang RELA 0000000000000000 00027110
0000000000000060 0000000000000018 I 33 22 8 # .debug_aranges的重定位表
[24] .debug_ranges PROGBITS 0000000000000000 0000bbb6
0000000000000030 0000000000000000 0 0 1 # 调试范围段
[25] .rela.debug_range RELA 0000000000000000 00027170
0000000000000060 0000000000000018 I 33 24 8 # .debug_ranges的重定位表
[26] .debug_line PROGBITS 0000000000000000 0000bbe6
0000000000000c7b 0000000000000000 0 0 1 # 调试行号段
[27] .rela.debug_line RELA 0000000000000000 000271d0
0000000000000030 0000000000000018 I 33 26 8 # .debug_line的重定位表
[28] .debug_str PROGBITS 0000000000000000 0000c861
0000000000008804 0000000000000001 MS 0 0 1 # 调试字符串段
[29] .comment PROGBITS 0000000000000000 00015065
0000000000000062 0000000000000001 MS 0 0 1 # 编译器注释段
[30] .note.GNU-stack PROGBITS 0000000000000000 000150c7
0000000000000000 0000000000000000 0 0 1 # GNU栈权限标识段
[31] .debug_frame PROGBITS 0000000000000000 000150c8
0000000000000060 0000000000000000 0 0 8 # 调试栈帧段
[32] .rela.debug_frame RELA 0000000000000000 00027200
0000000000000060 0000000000000018 I 33 31 8 # .debug_frame的重定位表
[33] .symtab SYMTAB 0000000000000000 00015128
0000000000000420 0000000000000018 34 39 8 # 符号表
[34] .strtab STRTAB 0000000000000000 00015548
0000000000000105 0000000000000000 0 0 1 # 符号名字符串表
[35] .shstrtab STRTAB 0000000000000000 00027260
000000000000015d 0000000000000000 0 0 1 # 节区名字符串表
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
p (processor specific)
|
节区头部表中又包含了很多子表的信息,我们简单的来看两个。
重定位表
从输出中可以清晰看到多个Type=RELA的节区,这些就是ELF格式的重定位表(RELA是带加数的重定位表,是Linux内核模块中最常见的重定位表类型)。 内核模块本质是未完全链接的ELF文件,加载到内核时需要内核完成最终的重定位(比如将符号地址替换为实际的内核虚拟地址),因此必然包含重定位表。
读取重定位表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | readelf -r helloworld.ko
Relocation section '.rela.init.text' at offset 0x15650 contains 4 entries: # .init.text(模块初始化代码)的重定位表,共4个条目
# 字段说明:Offset=重定位在目标节区的偏移 | Info=符号索引+重定位类型 | Type=重定位类型 | Sym. Value=符号值 | Sym. Name + Addend=符号名+加数
Offset Info Type Sym. Value Sym. Name + Addend
00000000000c 002b0000011b R_AARCH64_CALL26 0000000000000000 _mcount + 0 # 调用_mcount函数,26位跳转重定位
000000000010 000600000113 R_AARCH64_ADR_PRE 0000000000000000 .rodata.str1.1 + 0 # 寻址只读字符串段,ADR指令预重定位
000000000014 000600000115 R_AARCH64_ADD_ABS 0000000000000000 .rodata.str1.1 + 0 # 计算只读字符串段绝对地址,加法重定位
000000000018 002a0000011b R_AARCH64_CALL26 0000000000000000 printk + 0 # 调用内核printk(日志打印),26位跳转重定位
Relocation section '.rela.exit.text' at offset 0x156b0 contains 3 entries: # .exit.text(模块退出代码)的重定位表,共3个条目
Offset Info Type Sym. Value Sym. Name + Addend
000000000004 000600000113 R_AARCH64_ADR_PRE 0000000000000000 .rodata.str1.1 + 19 # 寻址只读字符串段偏移19处(退出提示字符串)
000000000008 000600000115 R_AARCH64_ADD_ABS 0000000000000000 .rodata.str1.1 + 19 # 计算该退出字符串的绝对地址
000000000010 002a0000011b R_AARCH64_CALL26 0000000000000000 printk + 0 # 调用内核printk(退出时打印日志)
...
|
字符串表
ELF文件中用到了很多字符串,比如段名、变量名等。因为字符串的长度往往是不定的, 所以用固定的结构来表示比较困难,一种常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。 一般字符串表在ELF文件中也以段的形式保存,常见的段名为“.strtab”(String Table 字符串表)或者“.shstrtab”(Section Header String Table 段字符串表)
读取节区字符串表:
1 2 3 4 5 6 7 8 9 10 11 | #如查看.modinfo节区字符串表
readelf -p .modinfo helloworld.ko
#信息输出如下
String dump of section '.modinfo':
[ 0] license=GPL
[ c] description=hello world module
[ 2b] author=embedfire <embedfire@embedfire.com>
[ 56] depends=
[ 5f] name=helloworld
[ 6f] vermagic=4.19.232 SMP mod_unload aarch64
|
ELF文件格式相关的知识比较晦涩,我们只需要大概了解,有个初步印象即可,主要是为了理解内核模块的加载卸载以及符号导出,在后面提到相关名词不至于太陌生。
2.2.1.2. 内核模块加载过程¶
在前面我们了解了ko内核模块文件的一些格式内容之后, 我们可以知道内核模块其实也是一段经过特殊加工的代码, 那么既然是加工过的代码,内核就可以利用到加工时留在内核模块里的信息, 对内核模块进行利用。
首先 insmod 会通过文件系统将 .ko模块 读到用户空间的一块内存中,
然后执行系统调用 sys_init_module() 解析模组,这时,内核在vmalloc区分配与ko文件大小相同的内存来暂存ko文件,
暂存好之后解析ko文件,将文件中的各个section分配到init 段和core 段,在modules区为init段和core段分配内存,
并把对应的section copy到modules区最终的运行地址,经过relocate函数地址等操作后,就可以执行ko的init操作了,
这样一个ko的加载流程就结束了。
同时,init段会被释放掉,仅留下core段来运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
|
第14行:通过vmalloc在vmalloc区分配内存空间,将内核模块copy到此空间,info->hdr 直接指向此空间首地址,也就是ko的elf header 。
第18行:然后通过load_module()进行模块加载的核心处理,在这里完成了模块的搬移,重定向等艰苦的过程。
下面是load_module()的详细过程,代码已经被简化,主要包含setup_load_info()和layout_and_allocate()。
1 2 3 4 5 6 7 8 9 10 11 12 13 | /* 分配并加载模块 */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
err = setup_load_info(info, flags);
...
mod = layout_and_allocate(info, flags);
...
}
|
第9行:setup_load_info()加载struct load_info 和 struct module, rewrite_section_headers,将每个section的sh_addr修改为当前镜像所在的内存地址, section 名称字符串表地址的获取方式是从ELF头中的e_shstrndx获取到节区头部字符串表的标号,找到对应section在ELF文件中的偏移,再加上ELF文件起始地址就得到了字符串表在内存中的地址。
第11行:在layout_and_allocate()中,layout_sections() 负责将section 归类为core和init这两大类,为ko的第二次搬移做准备。move_module()把ko搬移到最终的运行地址。内核模块加载代码搬运过程到此就结束了。
但此时内核模块要工作起来还得进行符号导出,内核模块导出符号我们放到后面小节详细讲解。
2.2.1.3. 内核模块卸载过程¶
卸载过程相对加载比较简单,我们输入指令rmmod,最终在系统内核中需要调用sys_delete_module进行实现。
具体过程如下:先从用户空间传入需要卸载的模块名称,根据名称找到要卸载的模块指针, 确保我们要卸载的模块没有被其他模块依赖,然后找到模块本身的exit函数实现卸载。 代码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
audit_log_kern_module(name);
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
if (!list_empty(&mod->source_list)) {
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count damn the torpedoes */
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();
blocking_notifier_call_chain(&module_notify_list,MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}
|
第8行:确保有插入和删除模块不受限制的权利,并且模块没有被禁止插入或删除。
第11行:获得模块名字。
第20行:找到要卸载的模块指针。
第26行:有依赖的模块,需要先卸载它们 。
第39行:检查模块的退出函数 。
第48行:停止机器,使参考计数不能移动并禁用模块。
第56行:告诉通知链module_notify_list上的监听者,模块状态变为MODULE_STATE_GOING。
第60行:等待所有异步函数调用完成。
2.2.2. 内核是如何导出符号的¶
符号是什么东西?我们为什么需要导出符号呢?内核模块如何导出符号呢?其他模块又是如何找到这些符号的呢?
这是这一小节讨论的知识,实际上,符号指的就是内核模块中使用EXPORT_SYMBOL声明的函数和变量。 当模块被装入内核后,它所导出的符号都会记录在公共内核符号表中。 在使用命令insmod加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
通常情况下我们无需导出任何符号,但是如果其他模块想要从我们这个模块中获取某些方便的时候, 就可以考虑使用导出符号为其提供服务。这被称为模块层叠技术。 例如msdos文件系统依赖于由fat模块导出的符号;USB输入设备模块层叠在usbcore和input模块之上。 也就是我们可以将模块分为多个层,通过简化每一层来实现复杂的项目。
modprobe是一个处理层叠模块的工具,它的功能相当于多次使用insmod, 除了装入指定模块外还同时装入指定模块所依赖的其他模块。
当我们要导出模块的时候,可以使用下面的宏
1 2 | EXPORT_SYMBOL(name)
EXPORT_SYMBOL_GPL(name) //name为我们要导出的标志
|
符号必须在模块文件的全局部分导出,不能在函数中使用,_GPL使得导出的模块只能被GPL许可的模块使用。 编译我们的模块时,这两个宏会被拓展为一个特殊变量的声明,存放在ELF文件中。 具体也就是存放在ELF文件的符号表中:
st_name: 是符号名称在符号名称字符串表中的索引值
st_value: 是符号所在的内存地址
st_size: 是符号大小
st_info: 是符号类型和绑定信息
st_shndx: 表示符号所在section
当ELF的符号表被加载到内核后,会执行simplify_symbols来遍历整个ELF文件符号表。 根据st_shndx找到符号所在的section和st_value中符号在section中的偏移得到真正的内存地址。 并最终将符号内存地址,符号名称指针存储到内核符号表中。
simplify_symbols函数原型如下:
1 | static int simplify_symbols(struct module *mod, const struct load_info *info)
|
函数参数和返回值如下:
参数:
mod: struct module类型结构体指针
info: const struct load_info结构体指针
返回值:
ret: 错误码
内核导出的符号表结构有两个字段,一个是符号在内存中的地址,一个是符号名称指针, 符号名称被放在了__ksymtab_strings这个section中, 以EXPORT_SYMBOL举例,符号会被放到名为___ksymtab的section中。 这个结构体我们要注意,它构成的表是导出符号表而不是通常意义上的符号表 。
1 2 3 4 | struct kernel_symbol {
unsigned long value;
const char *name;
};
|
value: 符号在内存中的地址
name: 符号名称
其他的内核模块在寻找符号的时候会调用resolve_symbol_wait去内核和其他模块中通过符号名称 寻址目标符号,resolve_symbol_wait会调用resolve_symbol,进而调用 find_symbol。 找到了符号之后,把符号的实际地址赋值给符号表 sym[i].st_value = ksym->value;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | /* 找到一个符号并将其连同(可选)crc和(可选)拥有它的模块一起返回。需要禁用抢占或模块互斥。 */
const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const s32 **crc,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
if (each_symbol_section(find_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
EXPORT_SYMBOL_GPL(find_symbol);
|
第14行:在each_symbol_section中,去查找了两个地方,一个是内核的导出符号表,即我们在将内核符号是如何导出的时候定义的全局变量,一个是遍历已经加载的内核模块,查找动作是在each_symbol_in_section中完成的。
第25行:导出符号标志
至此符号查找完毕,最后将所有section借助ELF文件的重定向表进行重定向,就能使用该符号了。
到这里内核就完成了内核模块的加载/卸载以及符号导出,感兴趣的读者可以查阅内核源码目录下/kernel/module.c。