
3. 内核模块¶
3.1. 内核概念¶
内核,是一个操作系统的核心。是基于硬件的第一层软件扩充,提供操作系统的最基本的功能, 是操作系统工作的基础,决定着整个操作系统的性能和稳定性。
内核按照体系结构分为: 微内核(Micro Kernel) 、 宏内核(Monolithic Kernel) 混合内核(Hybrid Kernel) 等。
下面是微内核和宏内核的简易对照图(图片来自于网络):
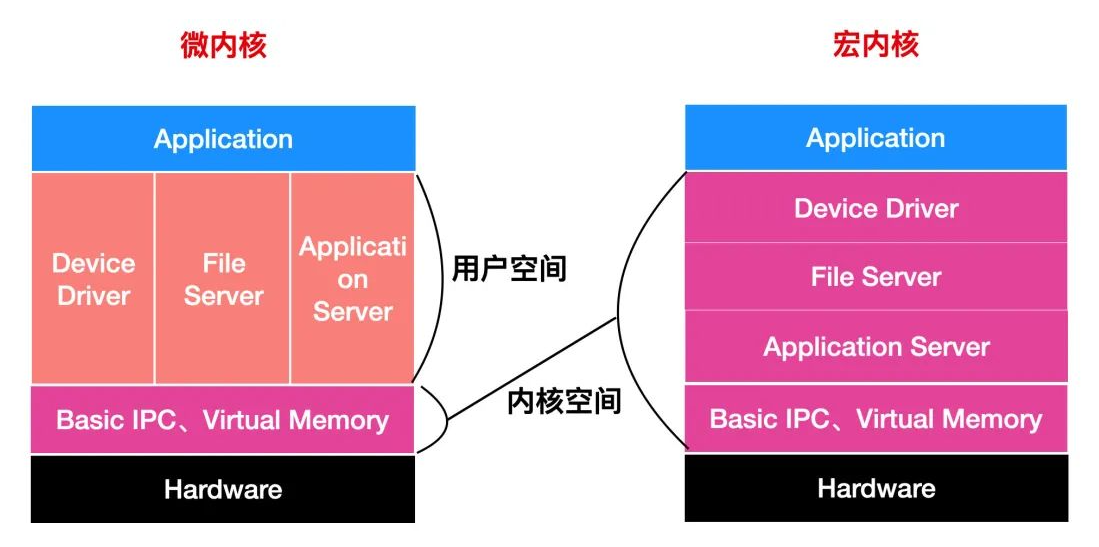
3.1.1. 微内核架构¶
在微内核架构中,内核只提供操作系统核心功能,如
进程管理、存储器管理、进程间通信、I/O设备管理等
而下面这些则不被包含到内核功能中,属于微内核之外的模块,所以针对这些模块的修改不会影响到微内核的核心功能。
应用层IPC、文件系统功能、设备驱动模块。
微内核具有动态扩展性强的优点。Windows操作系统、华为的鸿蒙操作系统就属于这类微内核架构。
3.1.2. 宏内核架构¶
宏内核架构是将上述包括微内核以及微内核之外的应用层IPC、文件系统功能、设备驱动模块都编译成一个整体。
优点:执行效率非常高
缺点:一旦我们想要修改、增加内核某个功能时(如增加设备驱动程序)都需要重新编译一遍内核。
Linux操作系统正是采用了宏内核结构,但是它也区分内核空间和用户空间。
关于内核模块的概念,在上个章节中 《Linux驱动编译方法》 中就有提及。
3.2. 内核模块的基本概念和特点¶
内核模块全称Loadable Kernel Module(LKM),是一种在内核运行时加载一组目标代码来实现某个特定功能的机制。
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不一样的。
模块由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序和其他内核上层功能。内核模块具备如下特点:
模块本身不被编译入内核映像,这控制了内核的大小。模块一旦被加载,它就和内核中的其它部分完全一样。
3.3. 内核模块常用命令¶
在讲内核模块的编译、加载/卸载内容之前,先介绍一下内核模块常用命令
3.3.1. lsmod命令¶
查看目前内核加载了多少模块,包含名称、大小、是否被其他模块所用
3.3.2. insmod命令¶
insmod命令(英文全拼:install module)用于将给定的模块加载到内核中。 关于该命令更多内容,可参考 《Linux insmod 命令》。
格式: insmod 模块完整路径名
示例: insmod /helloworld/helloworld.ko
3.3.3. rmmod命令¶
rmmod命令用于将已加载模块从内核中移除。
格式: rmmod [选项] 模块名
示例: rmmod helloworld.ko
选项:
-v:显示指令执行的详细信息;-f:强制移除模块,不论是否正在被使用,使用此选项比较危险;-s:向系统日志(syslog)发送错误信息。
3.3.5. modprobe命令¶
自动加载所需的模块依赖,并加载一个或多个模块。想了解更多可参考 《Linux modprobe命令》。这里不作详细介绍
3.3.6. depmod命令¶
depmod命令更新模块依赖信息。通常在安装新模块或更新内核后运行 depmod -a 来更新所有模块的依赖关系。想了解更多可参考 《Linux depmod命令》。这里不作详细介绍
3.3.7. modinfo命令¶
显示模块的详细信息,包括它的作者、版权、依赖项、符号等。想了解更多可参考 《Linux modinfo命令》。
3.3.8. kmod命令¶
内核模块管理工具,可以用于加载、卸载、刷新和列出模块。它是 insmod、rmmod、modprobe 和 lsmod 的现代替代品。kmod 构建在 libkmod 库之上,这个库提供了内核模块管理的功能。kmod 命令通常在 Linux 发行版中预装,或者可以通过包管理器安装。
注意
kmod 工具集的实际命令可能会根据您的系统和安装的 kmod 版本而有所不同。在大多数情况下,kmod 会接管传统的内核模块管理命令,因此您可以直接使用 insmod, modprobe, lsmod 等命令,它们通常会通过别名指向 kmod 对应的函数。
3.4. 内核模块的编译、加载和卸载¶
在上一章节我们已经写了一个最简单的 helloworld驱动,那么这个章节将来学习怎么将我们写的驱动编译成驱动文件,并加载到内核中。
3.4.1. 内核模块的编译¶
首先分析一下Makefile文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | KERNEL_DIR=../../kernel/
# KERNEL_DIR的路径得是内核源码路径
#声明编译的架构为arm64,编译器前缀为aarch64-linux-gnu-
ARCH=arm64
CROSS_COMPILE=aarch64-linux-gnu-
export ARCH CROSS_COMPILE
#obj-m:编译成模块
obj-m := helloworld.o
all:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) modules
#伪目标
.PHONE:clean
#指当make命令后紧跟clean时(即make clean),执行以下伪目标clean对应的指令
clean:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) clean
|
注解
第1行: 指定内核目录,根据自己编译内核时指定的输出目录,可以相对路径或者绝对路径,如果编译内核时没有指定特定输出目录,那么就将这个变量指定到内核源码的根目录。
第5行: arm64体系结构。
第6行: 指定交叉编译工具链。
第7行: 导出环境变量。
第9行: 表示以模块进行编译。
第10行: all只是个标号,可以自行定义,是make的默认执行目标。
第11行: 调用make编译时执行的语句
第14行: clean 就是删除后面这些由make生成的文件。
对11行语句单独分析:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) modules
$(MAKE):MAKE是Makefile中的宏变量,要引用宏变量要使用符号。这里实际上就是指向make程序,所以这里也可以把$(MAKE)换成make。make -C $(KERNEL_DIR):是make命令的一个选项,-C作用是changedirectory,-C $(KERNEL_DIR)指明跳转到内核源码目录下去执行那里的Makefile。M=$(CURDIR):返回当前目录。modules:make modules指单独编译模块这句话的意思是:当make执行默认的目标all时,-C $(KERNEL_DIR)指明跳转到内核源码目录下去执行那里的Makefile,M=$(CURDIR)表示又返回到当前目录来执行当前的Makefile。
注意
编译内核模块前一定要确认内核是否成功编译,否则会报错。
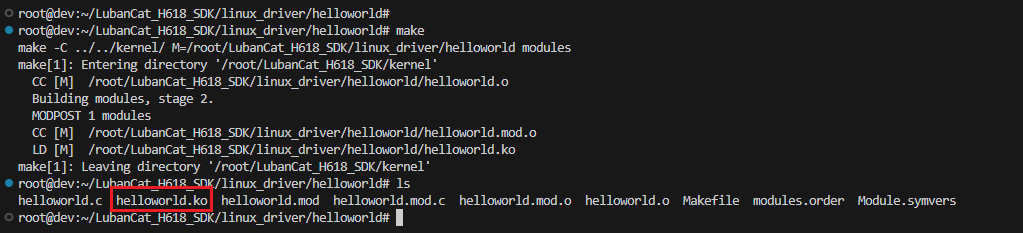
下面开始编译:
cd linux_driver/helloworld/
make
新增的helloworld.ko文件,这就是编译生成的内核驱动模块。
3.4.2. 内核模块的加载和卸载¶
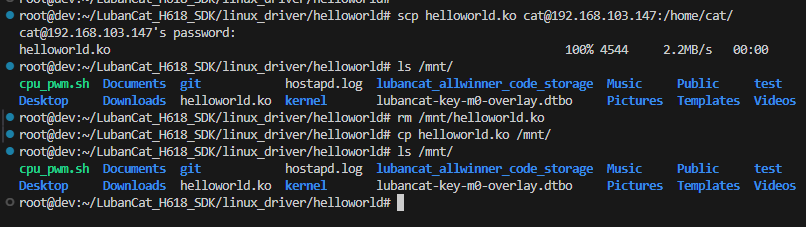
编译好内核驱动模块,可以通过多种方式将helloworld.ko拷贝到开发板,我们可以使用 NFS网络文件系统 、 scp命令 、 sftp命令 等。
其中NFS环境请搭建请参考开发环境搭建章节的 《搭建文件传输环境》 内容。
scp 命令用于 Linux 之间复制文件和目录,该命令基于ssh,需要搭建好ssh环境。
#SCP传输
scp helloworld.ko cat@192.168.103.147:/home/cat/
#NFS文件系统
cp helloworld.ko /mnt/
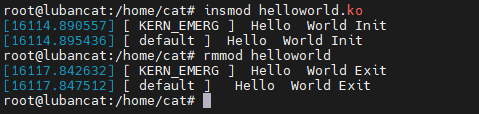
打开鲁班猫终端,输入以下命令将helloworld驱动模块加载到内核。
insmod helloworld.ko
我们也可以输入以下命令,将 helloworld 驱动拆卸。
rmmod helloworld
rmmod helloworld.ko
具体演示如下:
3.5. 内核模块的工作机制¶
我们编写的内核模块,经过编译,最终形成.ko为后缀的ELF文件。我们可以使用 file 命令来查看它。

那么这样的文件是如何被内核一步一步拿到并且很好的工作的呢?
为了便于我们更好的理解内核模块的加载/卸载过程,可以先跟我一起学习ELF文件格式,了解ko究竟是怎么一回事儿。
再一同去看看内核源码,探究内核模块加载/卸载,以及符号导出的经过。
3.5.1. ko文件的文件格式¶
ko文件在数据组织形式上是ELF(Excutable And Linking Format)格式,是一种普通的可重定位目标文件。这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。
ELF 文件格式的可能布局如下图。
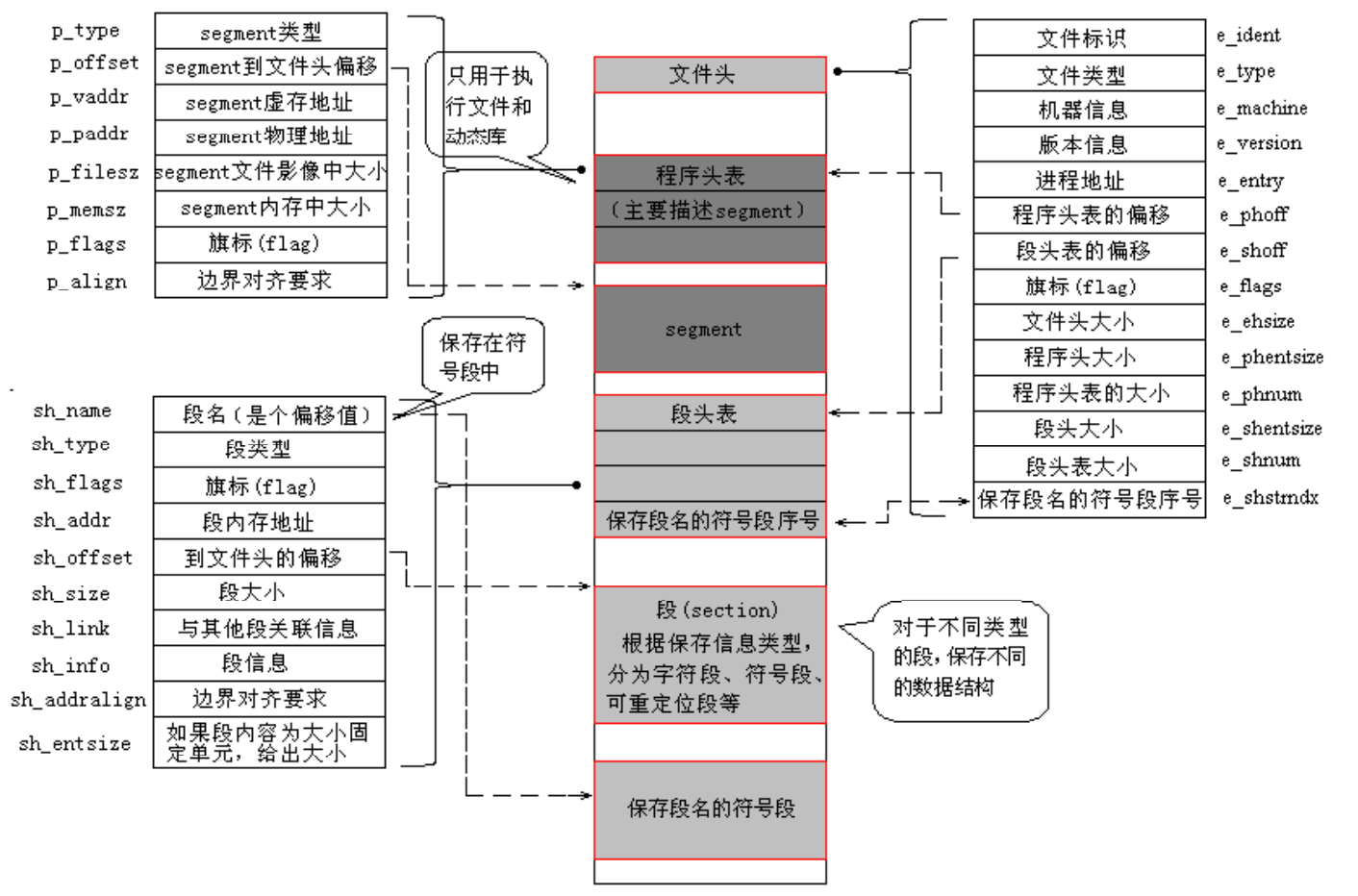
3.5.1.1. ELF文件头¶
文件开始处是一个ELF头部(ELF Header),用来描述整个文件的组织,这些信息独立于处理器,也独立于文件中的其余内容。文件头描述了ELF文件很多重要信息,例如它运行的平台,支持的CPU类型等。
Linux可执行文件采用ELF(Executable and Linkable Format)格式来存储数据。每个ELF文件都以以下的数据来开头:
#define EI_NIDENT (16)
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;
从中可知,ELF文件中的主要内容为 program header 和 section header ,两者的大小、在ELF文件中的位置和数量都能通过文件头来获取。而后又可以通过program header来获得每个segment的属性,通过section header来获得每个section的属性。
我们可以使用 readelf -h 工具查看elf文件的头部详细信息。
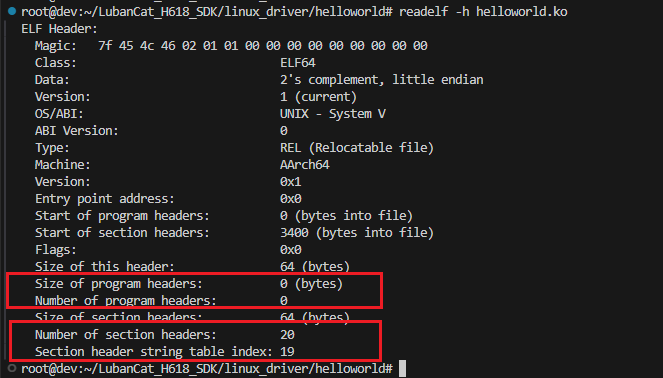
注意
注意此处program header的大小为0。
3.5.1.2. 程序头部表¶
头部详细信息,又叫程序头部表(Program Header Table),它是个数组结构。
程序头部表关注的是ELF文件加载时会有几个不同的属性的段,关心如何将相同属性的段合并为一个segment,以优化时间和空间消耗(只有dll/exe文件拥有程序头部表,relocatable文件没有程序头部表)
程序头部表格式如下:
typedef struct elf64_phdr {
Elf64_Word p_type;
Elf64_Word p_flags;
Elf64_Off p_offset; /* Segment file offset */
Elf64_Addr p_vaddr; /* Segment virtual address */
Elf64_Addr p_paddr; /* Segment physical address */
Elf64_Xword p_filesz; /* Segment size in file */
Elf64_Xword p_memsz; /* Segment size in memory */
Elf64_Xword p_align; /* Segment alignment, file & memory */
} Elf64_Phdr;
可以通过 readelf -l 查看程序头部表,如下:

可以看出这个文件没有程序头部表,这也符合了上面ELF文件头部分“program header的大小为0”的描述。
3.5.1.3. 节区头部表¶
节区头部表实际上是一个Elf_Shdr[m]数组,其中的每一个元素(表项)记录系统中一个节区的信息,包括如节区名,类型,flag,内存/文件起始地址,大小,对齐等信息,如:
typedef struct elf64_shdr {
Elf64_Word sh_name; /* Section name, index in string tbl */
Elf64_Word sh_type; /* Type of section */
Elf64_Xword sh_flags; /* Miscellaneous section attributes */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Size of section in bytes */
Elf64_Word sh_link; /* Index of another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
我们可以使用 readelf -S 读取elf文件的节区头部表的详细信息。
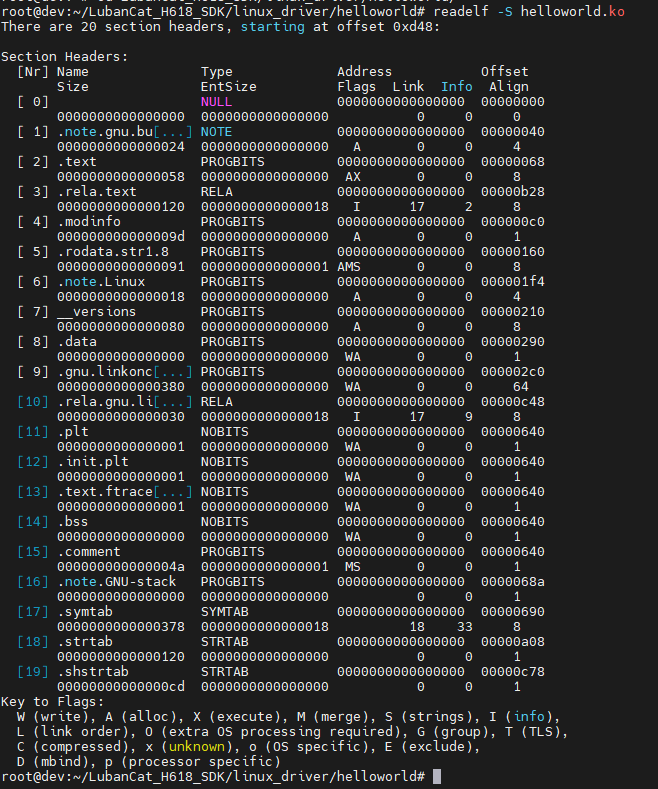
其中每一行是节区头部表中的一个表项,也代表着此elf文件中的一个节区信息(ELF文件中定位节区的方式是: ELF头–>节区头部表–>节区首地址及其他信息)
节区头部表中又包含了很多子表的信息,我们这里就简单介绍一个字符串表。
3.5.1.4. 字符串表¶
字符串表,严格来说应该是节区头部表字符串表,该表是给节区头部表专门准备的字符串表,ELF文件中通常存在两个字符串表:
一个是代码中所有使用到的字符串的表,名称为.strtab
一个是记录所有节区名的字符串表,名称为.shstrtab
二者通常是没有关系的,.shstrtab只记录节区名称,而.strtab则记录符号表中符号相关的字符串信息。
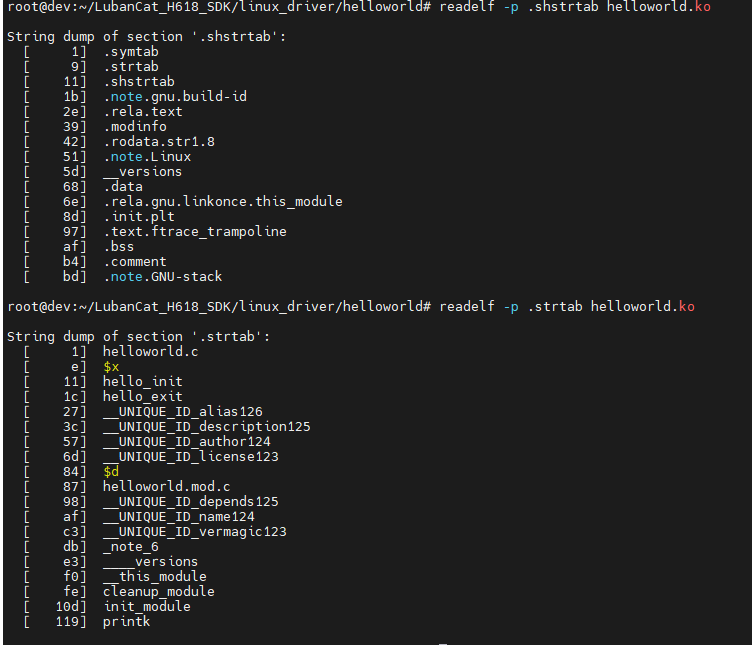
我们可以使用 readelf -p .shstrtab 读取.shstrtab字符串表的详细信息,使用 readelf -p .strtab 读取.strtab字符串表的详细信息。
演示如下:
3.5.2. 内核模块加载过程¶
在前面我们了解了ko内核模块文件的一些格式内容之后,我们可以知道内核模块其实也是一段经过特殊加工的代码,那么既然是加工过的代码,内核就可以利用到加工时留在内核模块里的信息,对内核模块进行利用。
所以我们就可以接着了解内核模块的加载过程了。
首先
insmod会通过文件系统将.ko模块读到用户空间的一块内存中;然后执行系统调用
init_module()解析模块,这时,内核在 vmalloc 区分配与ko文件大小相同的内存来暂存ko文件;暂存好之后解析ko文件,将文件中的各个section 分配到init 段和core 段;
在modules区为init段和core段分配内存,并把对应的section copy到modules区最终的运行地址,经过relocate函数地址等操作后,就可以执行ko的init操作了。
这样一个ko的加载流程就结束了。同时,init段会被释放掉,仅留下core段来运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | /*************************************************************************************************
* @brief init_module() (SYSCALL_DEFINE3为Linux 内核中用于定义一个系统调用的宏)
* @note 这个系统调用名为 init_module,它允许用户空间的程序向内核加载一个内核模块。
* @param umod 指向用户空间中包含模块数据的内存区域的指针
* @param len 模块数据的长度,以字节为单位
* @param uargs 指向用户空间中的字符串的指针,该字符串包含了传递给模块的参数
* @return 成功时返回0,失败时返回负数(ret:错误码)
*************************************************************************************************/
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
|
注解
第22行:通过vmalloc在vmalloc区分配内存空间,将内核模块copy到此空间,info->hdr 直接指向此空间首地址,也就是ko的elf header 。
第26行:然后通过load_module()进行模块加载的核心处理,在这里完成了模块的搬移,重定向等艰苦的过程。
下面是load_module()的详细过程,代码已经被我简化,主要包含setup_load_info()和layout_and_allocate()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | /*************************************************************************************************
* @brief load_module
* @note 用于加载内核模块的内部函数。通常由用户空间的系统调用接口通过 init_module 系统调用触发
* @param info 指向 load_info 结构体的指针,该结构体包含了模块加载所需的信息
* @param uargs 指向用户空间字符串的指针,该字符串包含了传递给模块的参数。
* @param flags 用于指定加载模块时的标志,这些标志可以控制模块加载的行为。
* @return 成功时返回0,失败时返回负数(ret:错误码)
*************************************************************************************************/
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
err = setup_load_info(info, flags);
...
mod = layout_and_allocate(info, flags);
...
}
|
注解
第16行:setup_load_info()加载struct load_info 和 struct module, rewrite_section_headers,将每个section的sh_addr修改为当前镜像所在的内存地址, section 名称字符串表地址的获取方式是从ELF头中的e_shstrndx获取到节区头部字符串表的标号,找到对应section在ELF文件中的偏移,再加上ELF文件起始地址就得到了字符串表在内存中的地址。
第18行:在layout_and_allocate()中,layout_sections() 负责将section 归类为core和init这两大类,为ko的第二次搬移做准备。move_module()把ko搬移到最终的运行地址。内核模块加载代码搬运过程到此就结束了。
注意
但此时内核模块要工作起来还得进行符号导出,内核模块导出符号我们放到后面小节详细讲解。
3.5.3. 内核模块卸载过程¶
卸载过程相对加载比较简单,我们输入指令rmmod,最终在系统内核中需要调用delete_module进行实现。
具体过程如下:先从用户空间传入需要卸载的模块名称,根据名称找到要卸载的模块指针,确保我们要卸载的模块没有被其他模块依赖,然后找到模块本身的exit函数实现卸载。代码如下。
代码文件路径:内核源码(kernel)/kernel/module.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | /*************************************************************************************************
* @brief delete_module() (SYSCALL_DEFINE2为Linux 内核中用于定义一个系统调用的宏)
* @note 这个系统调用名为 delete_module,它用于从内核中移除一个已经加载的内核模块。
* @param name_user 指向用户空间的字符串的指针,该字符串包含了要删除的模块的名称
* @param uargs 这是一个标志值,用于指定删除模块时的行为。
* @return 成功时返回0,失败时返回负数(ret:错误码)
*************************************************************************************************/
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
audit_log_kern_module(name);
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
if (!list_empty(&mod->source_list)) {
/* Other modules depend on us: get rid of them first. */
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count damn the torpedoes */
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
/* If it has an init func, it must have an exit func to unload */
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
/* Stop the machine so refcounts can't move and disable module. */
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();
blocking_notifier_call_chain(&module_notify_list,
MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
/* someone could wait for the module in add_unformed_module() */
wake_up_all(&module_wq);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}
|
注解
第15行:确保有插入和删除模块不受限制的权利,并且模块没有被禁止插入或删除
第18行:获得模块名字
第27行:找到要卸载的模块指针
第33行:有依赖的模块,需要先卸载它们
第48行:检查模块的退出函数
第58行:停止机器,使参考计数不能移动并禁用模块
第66-67行:告诉通知链module_notify_list上的监听者,模块状态变为MODULE_STATE_GOING
第71行:等待所有异步函数调用完成
注意
从 Linux 内核版本 5.10 开始,delete_module 系统调用已被弃用,并在后续版本中被移除。取而代之的是 request_module 系统调用,它可以用来请求内核卸载一个模块。这是因为 delete_module 可能会导致系统不稳定,特别是在强制删除正在使用的模块时。request_module 系统调用提供了更安全的方式来管理内核模块的生命周期。
3.5.4. 内核是如何导出符号的¶
符号是什么东西?我们为什么需要导出符号呢?内核模块如何导出符号呢?其他模块又是如何找到这些符号的呢?
这是这一小节讨论的知识,实际上,符号指的就是内核模块中使用EXPORT_SYMBOL声明的函数和变量。当模块被装入内核后,它所导出的符号都会记录在公共内核符号表中。在使用命令insmod加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
通常情况下我们无需导出任何符号,但是如果其他模块想要从我们这个模块中获取某些方便的时候, 就可以考虑使用导出符号为其提供服务。这被称为模块层叠技术。 例如msdos文件系统依赖于由fat模块导出的符号;USB输入设备模块层叠在usbcore和input模块之上。 也就是我们可以将模块分为多个层,通过简化每一层来实现复杂的项目。
modprobe是一个处理层叠模块的工具,它的功能相当于多次使用insmod,除了装入指定模块外还同时装入指定模块所依赖的其他模块。该命令在前面的“内核模块常用命令”中也有提及。
当我们要导出模块的时候,可以使用下面的宏
EXPORT_SYMBOL(name)
EXPORT_SYMBOL_GPL(name) //name为我们要导出的标志
符号必须在模块文件的全局部分导出,不能在函数中使用,_GPL使得导出的模块只能被GPL许可的模块使用。
编译我们的模块时,这两个宏会被拓展为一个特殊变量的声明,存放在ELF文件中。 具体也就是存放在ELF文件的符号表中:
st_name: 是符号名称在符号名称字符串表中的索引值
st_value: 是符号所在的内存地址
st_size: 是符号大小
st_info: 是符号类型和绑定信息
st_shndx: 表示符号所在section
当ELF的符号表被加载到内核后,会执行simplify_symbols来遍历整个ELF文件符号表。 根据st_shndx找到符号所在的section和st_value中符号在section中的偏移得到真正的内存地址。并最终将符号内存地址,符号名称指针存储到内核符号表中。
simplify_symbols函数原型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | /********************************************************************************************
* @brief simplify_symbols()
* @note 在模块加载过程中简化模块的符号表(内部函数)
* @param mod 指向 module 结构体的指针,该结构体代表了一个内核模块
* @param info 指向 load_info 结构体的指针,该结构体包含了模块加载时的详细信息
* @return 成功时返回0,失败时返回负数(ret:错误码)
********************************************************************************************/
static int simplify_symbols(struct module *mod, const struct load_info *info)
{
Elf_Shdr *symsec = &info->sechdrs[info->index.sym];
Elf_Sym *sym = (void *)symsec->sh_addr;
unsigned long secbase;
unsigned int i;
int ret = 0;
const struct kernel_symbol *ksym;
for (i = 1; i < symsec->sh_size / sizeof(Elf_Sym); i++) {
const char *name = info->strtab + sym[i].st_name;
switch (sym[i].st_shndx) {
case SHN_COMMON:
/* Ignore common symbols */
if (!strncmp(name, "__gnu_lto", 9))
break;
/* We compiled with -fno-common. These are not
supposed to happen. */
pr_debug("Common symbol: %s\n", name);
pr_warn("%s: please compile with -fno-common\n",
mod->name);
ret = -ENOEXEC;
break;
case SHN_ABS:
/* Don't need to do anything */
pr_debug("Absolute symbol: 0x%08lx\n",
(long)sym[i].st_value);
break;
case SHN_LIVEPATCH:
/* Livepatch symbols are resolved by livepatch */
break;
case SHN_UNDEF:
ksym = resolve_symbol_wait(mod, info, name);
/* Ok if resolved. */
if (ksym && !IS_ERR(ksym)) {
sym[i].st_value = kernel_symbol_value(ksym);
break;
}
/* Ok if weak or ignored. */
if (!ksym &&
(ELF_ST_BIND(sym[i].st_info) == STB_WEAK ||
ignore_undef_symbol(info->hdr->e_machine, name)))
break;
ret = PTR_ERR(ksym) ?: -ENOENT;
pr_warn("%s: Unknown symbol %s (err %d)\n",
mod->name, name, ret);
break;
default:
/* Divert to percpu allocation if a percpu var. */
if (sym[i].st_shndx == info->index.pcpu)
secbase = (unsigned long)mod_percpu(mod);
else
secbase = info->sechdrs[sym[i].st_shndx].sh_addr;
sym[i].st_value += secbase;
break;
}
}
return ret;
}
|
内核导出的符号表结构有两个字段,一个是符号在内存中的地址,一个是符号名称指针, 符号名称被放在了 __ksymtab_strings 这个section中,以 EXPORT_SYMBOL 举例,符号会被放到名为 ___ksymtab 的section中。这个结构体我们要注意,它构成的表是导出符号表而不是通常意义上的符号表 。
1 2 3 4 5 | struct kernel_symbol {
unsigned long value;
const char *name;
const char *namespace;
};
|
成员 |
描述 |
|---|---|
value |
符号的虚拟地址。在内核中,这通常是函数或变量在内存中的地址。对于内核符号,这个地址是相对于内核的虚拟地址空间的。 |
name |
符号的名称 |
namespace |
符号的命名空间。在内核中,命名空间用于区分不同类型的符号。 |
其他的内核模块在寻找符号的时候会调用resolve_symbol_wait去内核和其他模块中通过符号名称寻址目标符号,resolve_symbol_wait会调用resolve_symbol,进而调用 find_symbol。找到了符号之后,把符号的实际地址赋值给符号表 sym[i].st_value = ksym->value。
注意
find_symbol 函数是 Linux 内核中用于搜索特定符号的函数。这个函数在内核模块加载、符号解析和依赖管理中扮演着重要角色。当你需要找到一个符号的地址、所有者、CRC 校验和、许可证信息等时,可以使用这个函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | /************************************************************************************
* @brief find_symbol()
* @note 用于搜索特定符号的函数
* @param name 要搜索的符号名称,这个名称应该与内核中的一个符号完全匹配
* @param owner 指向指向 module 结构体的指针的指针
* @param crc 设置为指向该符号的 CRC 校验和,如果不关心CRC校验和,设置为 NULL
* @param license 设置为指向该符号的许可证信息,如果你不关心许可证信息,设置为 NULL
* @param gplok 指定是否允许在 GPL 兼容的模块中搜索符号
* @param warn 指定如果找不到符号是否应该发出警告
* @return 成功找到返回该符号的地址,没有找到返回 NULL
************************************************************************************/
static const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const s32 **crc,
enum mod_license *license,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
if (each_symbol_section(find_exported_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
if (license)
*license = fsa.license;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
/************************************************************************************
* @brief __symbol_get()
* @note 用于根据符号名称获取其对应的内核地址(内部函数)
* @param symbol 要查找的符号的名称。这个名称应该与内核中的一个符号完全匹配。
* @return 返回值是一个 void 指针,指向找到的符号的地址。符号不存在返回 NULL
************************************************************************************/
void *__symbol_get(const char *symbol)
{
struct module *owner;
const struct kernel_symbol *sym;
preempt_disable();
sym = find_symbol(symbol, &owner, NULL, NULL, true, true);
if (sym && strong_try_module_get(owner))
sym = NULL;
preempt_enable();
return sym ? (void *)kernel_symbol_value(sym) : NULL;
}
EXPORT_SYMBOL_GPL(__symbol_get);
|
注解
第25行:在each_symbol_section中,去查找了两个地方,一个是内核的导出符号表,即我们在将内核符号是如何导出的时候定义的全局变量,一个是遍历已经加载的内核模块,查找动作是在each_symbol_in_section中完成的。
第50行:__symbol_get函数调用了find_symbol函数。
第57行:导出符号标志。
至此符号查找完毕,最后将所有section借助ELF文件的重定向表进行重定向,就能使用该符号了。
到这里内核就完成了内核模块的加载/卸载以及符号导出,感兴趣的读者可以查阅内核源码目录下/kernel/module.c文件。
3.6. 本章命令/函数汇总¶
3.6.1. 命令汇总¶
注意
关于上述内核模块的常用命令,这里仅列举1~2个例子,如 depmod 命令举例为 depmod -a 。
# 查看目前内核加载的模块
lsmod
# 加载模块到内核
insmod xxx.ko
# 卸载模块
rmmod xxx.ko
rmmod xxx
# 查看内核打印的所有信息
sudo dmesg
# 查看包含xxx内容的内核打印信息
sudo dmesg | grep xxx
# 自动加载所需的模块依赖,并加载一个或多个模块。(下一个章节实验会用到)
modprobe xxx
# 递归地更新所有模块的依赖关系,更新 modules.dep 文件。
depmod -a
# 显示特点模块的简要信息,包括它的作者、版权、依赖项、符号等。
modinfo xxx
# 显示crct10dif_ce模块的简要信息,该模块为lsmod列出来随便选的
modinfo crct10dif_ce
# 列出所有已安装的内核模块
kmod list
# 通过scp将xxx.ko文件传输到鲁班猫的/home/cat/目录下
scp xxx.ko cat@192.168.103.147:/home/cat/
# 查看elf文件的头部详细信息。
readelf -h xxx.ko
# 查看程序头部表
readelf -l xxx.ko
# 读取elf文件的节区头部表的详细信息。
readelf -S xxx.ko
# 读取.shstrtab字符串表的详细信息
readelf -p .shstrtab xxx.ko
# 读取.strtab字符串表的详细信息。
readelf -p .strtab xxx.ko
3.6.2. 函数汇总¶
以下内容不仅包含函数,还有系统调用的宏
// 内核模块加载系统调用名为init_module的宏
SYSCALL_DEFINE3(init_module, void __user *, umod, unsigned long, len, const char __user *, uargs)
// 用于加载内核模块的内部函数。通常由用户空间的系统调用接口通过 init_module 系统调用触发
static int load_module(struct load_info *info, const char __user *uargs, int flags)
// 内核模块卸载系统调用名为delete_module的宏
SYSCALL_DEFINE2(delete_module, const char __user *, name_user, unsigned int, flags)
// 在模块加载过程中简化模块的符号表(内部函数)
static int simplify_symbols(struct module *mod, const struct load_info *info)
// 用于搜索特定符号的函数
static const struct kernel_symbol *find_symbol(const char *name, struct module **owner, const s32 **crc, enum mod_license *license, bool gplok, bool warn)
// 根据符号名称获取其对应的内核地址(内部函数)
void *__symbol_get(const char *symbol)